重温经典Dijkstra算法——看我用现代算法来为大唐运荔枝!
原创
重温经典Dijkstra算法——看我用现代算法来为大唐运荔枝!
原创
熊猫钓鱼
发布于 2025-06-20 23:47:40
发布于 2025-06-20 23:47:40
引言:从历史到代码的奇妙穿越
一骑红尘妃子笑:当Dijkstra遇上杨贵妃的荔枝

其实我一直没想明白,长安的荔枝,究竟是贵妃独独偏爱吃荔枝,还是因为长安其他水果的含糖量不高?
我,一个现代普通码农,一觉醒来居然穿越到了魂牵梦绕的大唐。
只见远处走来一个公公,他告诉我:
“圣上有旨,你是圣人钦点的“荔枝使”,负责将荔枝从“岭南”运往“长安”,即可启程,钦此!”
我,低头,看了一眼自己身上这花花红红的朝服。再看看周遭繁华的市井。
我,一个熊猫一样的男人,居然穿越成了大唐“荔枝使”!
不是,哥们,我没想到你来真的!
来来来,我现在来就给你运荔枝!
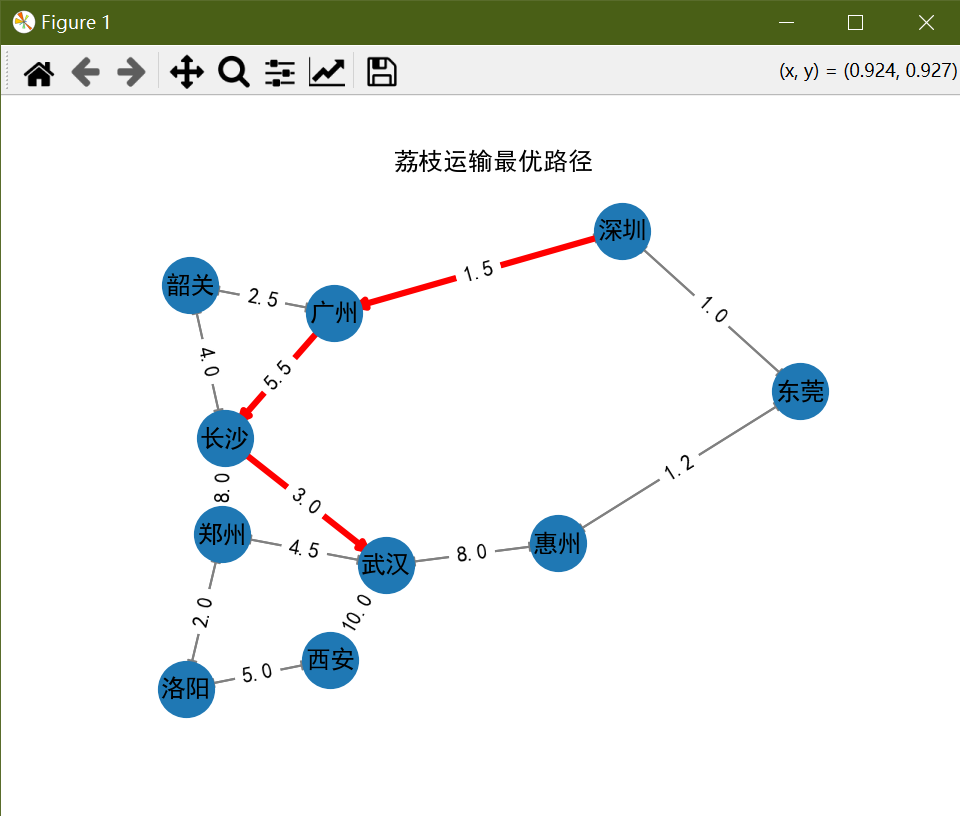
众所周知荔枝特别容易坏,所以为了让圣人满意,让“中书省”的各位大人们肯拨付银两,咱们还是得想出一条最短最快的运输路径。
略微写下程序跑图,你看看这图,这点,这边~!
我从深圳除非到广州,再到长沙到武汉...
考虑到这一路跋山涉水,特别是武汉到西安那令人发指的10.0的权重,其实本武汉“荔枝使”想的是,咱就自个儿吃好喝好再谢罪得了,咳咳,圣人就不必吃了!

"一骑红尘妃子笑,无人知是荔枝来。"
杜牧笔下这短短14个字,真是可以说道尽了唐代荔枝运输的艰辛。作为程序员,每想到这句诗,我的CPU就又开始过热——如果用现代算法优化,究竟能否让杨贵妃吃上更新鲜的荔枝?
本文将记录从灵光乍现到代码实现的全过程,以及那些比荔枝还甜的技术感悟。
技术选型:当古典问题遇上现代算法
1. 城市图和那些跑马跑的要发疯的官道驿站们
首先需要将唐代的驿站网络抽象为图结构:
目标:使用以下城市图,用你熟悉的算法(如 Dijkstra、A*)找出从深圳→西安的最优路线,并输出路径和总代价
城市图如下:括号中的数字代表运输时间(单位:小时)
city_graph = {
'深圳': {'广州': 1.5, '东莞': 1.0},
'广州': {'深圳': 1.5, '韶关': 2.5, '长沙': 5.5},
'东莞': {'深圳': 1.0, '惠州': 1.2},
'惠州': {'东莞': 1.2, '武汉': 8.0},
'韶关': {'广州': 2.5, '长沙': 4.0},
'长沙': {'韶关': 4.0, '武汉': 3.0, '郑州': 8.0},
'武汉': {'惠州': 8.0, '长沙': 3.0, '郑州': 4.5, '西安': 10.0},
'郑州': {'长沙': 8.0, '武汉': 4.5, '洛阳': 2.0},
'洛阳': {'郑州': 2.0, '西安': 5.0},
'西安': {'武汉': 10.0, '洛阳': 5.0}
}我理解了一下,这种处理结构,有以下特点:
- 每个城市(V)是图中的一个节点表示,并给出了它能到达的节点和对应的距离
- 每条运输路线(E)就是图中的一条边,由出发节点和对应到达的节点作为端点
- 运输时间或者说路径自然就成为边的权重(cost),越短越值钱!
考虑到古代道路交通网并不发达,想要速度快肯定是骑马走官道这样的大道,那么显然古代的官道就那么几条,而且在一段时间内基本不会有大的变化,我们确实可以将运输问题简化模型为边和点集合表示的图结构。
这是我站在出题者立场做的脑补,应该基本合理吧?
这不禁让我想到:人生不也是一张有向图吗?每个选择都是通往不同节点的边,而时间成本就是边的权重。咳咳,不好意思,扯远了~
那么,解决这种复杂度一般的运输问题,最简单易懂的思路就是Dijkstra算法了,虽然它的时间复杂度其实是O(V^2),但是这是纸面上的课本上教的,懂的兄弟们都懂,事实上在节点数量比较少时它还是很高效的。使用优先队列还可以优化:使用最小堆(如二叉堆)高效选取最近节点,可将时间复杂度从 O(V^2)优化到 O(E+VlogV)。
何况链路变化小,这大唐太平盛世不可能所有道路同时“断联”,哈哈。
2. 算法大战:Dijkstra vs A*
A*算法其实也可以用,它更多用于游戏中的寻路,是一种启发式搜索,能更快找到目标节点路径,但不保证全局最优。也就是作为荔枝使的你还是不能免责,很可能被圣人刀了啊 (:з」∠)
Dijkstra算法是一种用于求解单源最短路径的经典算法,适用于带权有向图或无向图(权重为非负数)。它的核心思想是通过逐步扩展已知的最短路径集合,最终找到从起点到所有其他节点的最短路径。Dijkstra同时也是路由算法的核心,尤其适用于链路状态协议(如OSPF)。
它计算的是全局最优路径,但对负权边和动态网络适应性较弱。咱这也基本不是这种情况,所以就选它了。
小小总结一下,
Dijkstra算法最终胜出,原因有三:
- 实现简单,适合MVP版本
- 保证找到最短路径
- 时间复杂度O(V log V)可以接受
3. 实现过程与解析
附代码如下:
import heapq
def dijkstra(graph, start, end):
# 初始化距离字典,所有城市距离设为无穷大
distances = {city: float('infinity') for city in graph}
distances[start] = 0
# 优先队列,存储(距离, 当前城市, 路径)
heap = [(0, start, [start])]
heapq.heapify(heap)
while heap:
current_distance, current_city, path = heapq.heappop(heap)
# 如果到达终点,返回结果
if current_city == end:
return current_distance, path
# 如果当前距离大于已知距离,跳过
if current_distance > distances[current_city]:
continue
# 遍历邻居城市
for neighbor, weight in graph[current_city].items():
distance = current_distance + weight
# 如果找到更短路径,更新距离并加入堆
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(heap, (distance, neighbor, path + [neighbor]))
return float('infinity'), [] # 如果没有路径函数接收三个参数:graph(图结构)、start(起点)和end(终点)。函数内部初始化了一个distances字典,将所有城市的初始距离设为无穷大,但起点的距离设为0。这是Dijkstra算法的标准步骤,用于记录从起点到各个节点的最短距离。
然后,函数使用优先队列(堆)来管理待处理的节点,初始时将起点加入堆中,堆中的元素包括当前距离、当前城市和路径。堆的特性保证了每次取出的是距离最小的节点,这符合Dijkstra算法的贪心策略。
在while循环中,每次从堆中取出当前节点。如果当前节点是终点,就返回当前的距离和路径,这是算法的终止条件之一。如果当前节点的距离已经大于之前记录的最短距离,则跳过,这处理了可能存在的旧数据,确保不会重复处理无效的路径。
接下来,遍历当前节点的所有邻居,计算经过当前节点到达邻居的新距离。如果新距离更短,则更新距离,并将邻居及其新距离和路径加入堆中。这一步是算法的核心,不断松弛(relax)边的过程,寻找更短的路径。
最后,如果堆被处理完毕仍未找到终点,则返回无穷大和空列表,表示没有可行路径。
以上,是不是非常容易理解?
PS:这个算法是图论经典算法,刷OJ会遇到,面试要考!建议将其堆实现方式背下来,哈哈!
4. 计算结果
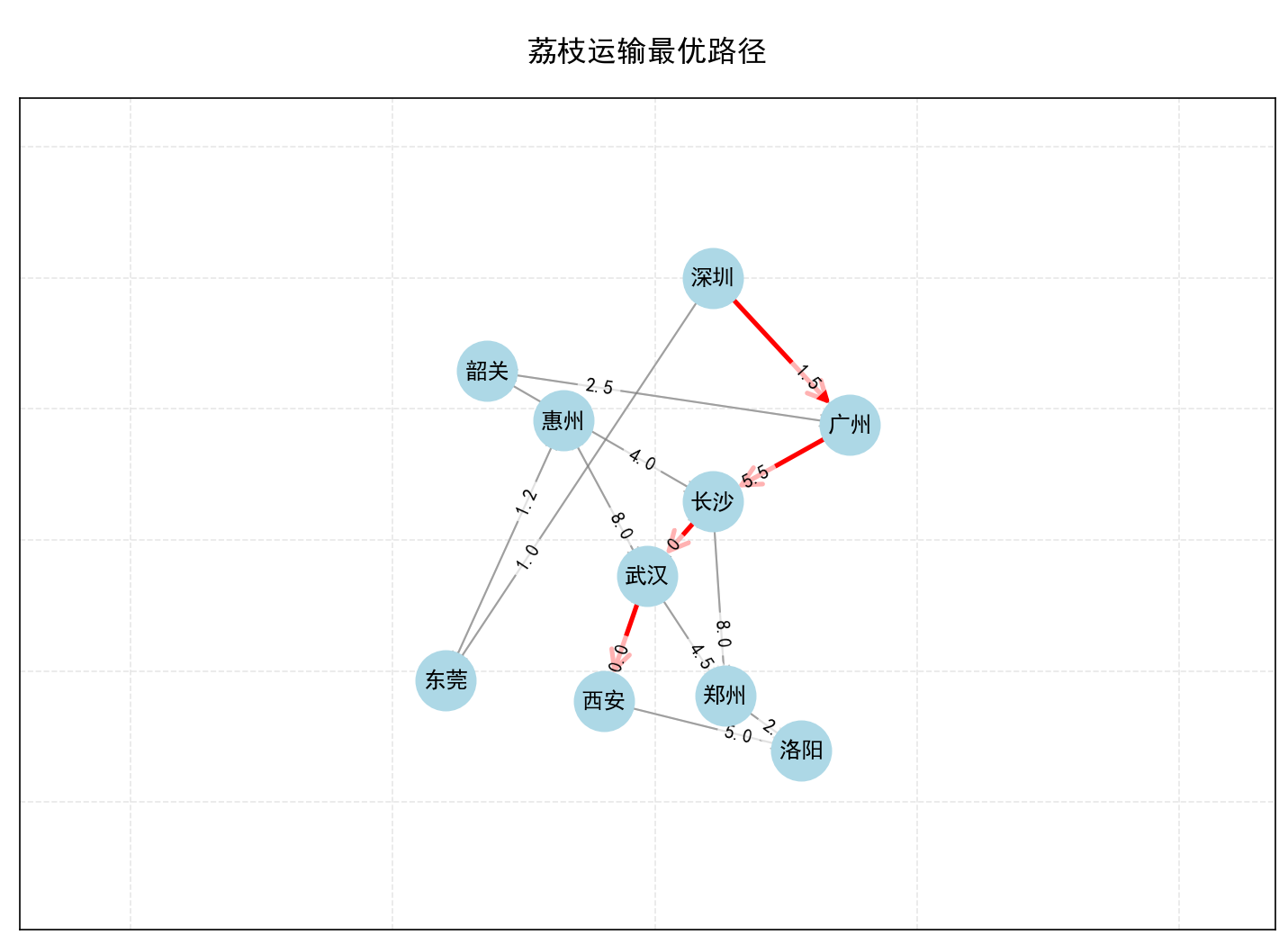
从深圳到西安的荔枝运输最优路径如下:
最优路径: 深圳 → 广州 → 长沙 → 武汉 → 西安
总运输时间: 20.0小时
详细路径信息:
深圳 → 广州: 1.5小时
广州 → 长沙: 5.5小时
长沙 → 武汉: 3.0小时
武汉 → 西安: 10.0小时
程序使用Dijkstra算法成功计算出了最短路径,总运输时间为20小时。这是从深圳到西安运输荔枝的最优路线。
开发历险记:那些比荔枝还棘手的Bug
1. 中文显示惨案
第一次可视化时,所有中文都变成了"□□□":这显然是字体的兼容性问题。
# 血的教训:必须显式设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']这个Bug教会我:兼容性要从第一天就考虑。
2. 可视化技巧
使用NetworkX的进阶技巧:
# 路径高亮显示
path_edges = [(a,b) for a,b in zip(path, path[1:])]
nx.draw_networkx_edges(G, pos, edgelist=path_edges,
edge_color='r', width=3)实现绘图展示代码如下:
import matplotlib.pyplot as plt
import networkx as nx
def visualize_path(graph, path):
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
G = nx.DiGraph()
# 添加所有节点和边
for city in graph:
G.add_node(city)
for neighbor, weight in graph[city].items():
G.add_edge(city, neighbor, weight=weight)
# 设置图形布局
pos = nx.spring_layout(G)
# 绘制所有节点和边
nx.draw_networkx_nodes(G, pos, node_size=700)
nx.draw_networkx_labels(G, pos)
nx.draw_networkx_edges(G, pos, edge_color='gray', width=1, arrows=True)
# 高亮显示路径
path_edges = list(zip(path[:-1], path[1:]))
nx.draw_networkx_edges(G, pos, edgelist=path_edges,
edge_color='red', width=3, arrows=True)
# 添加边权重标签
edge_labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.title("荔枝运输最优路径")
plt.axis('off')
plt.show()实现运输效果图如下
3. 多目标优化的启示
后期加入费用权重时,需要平衡时间和成本:
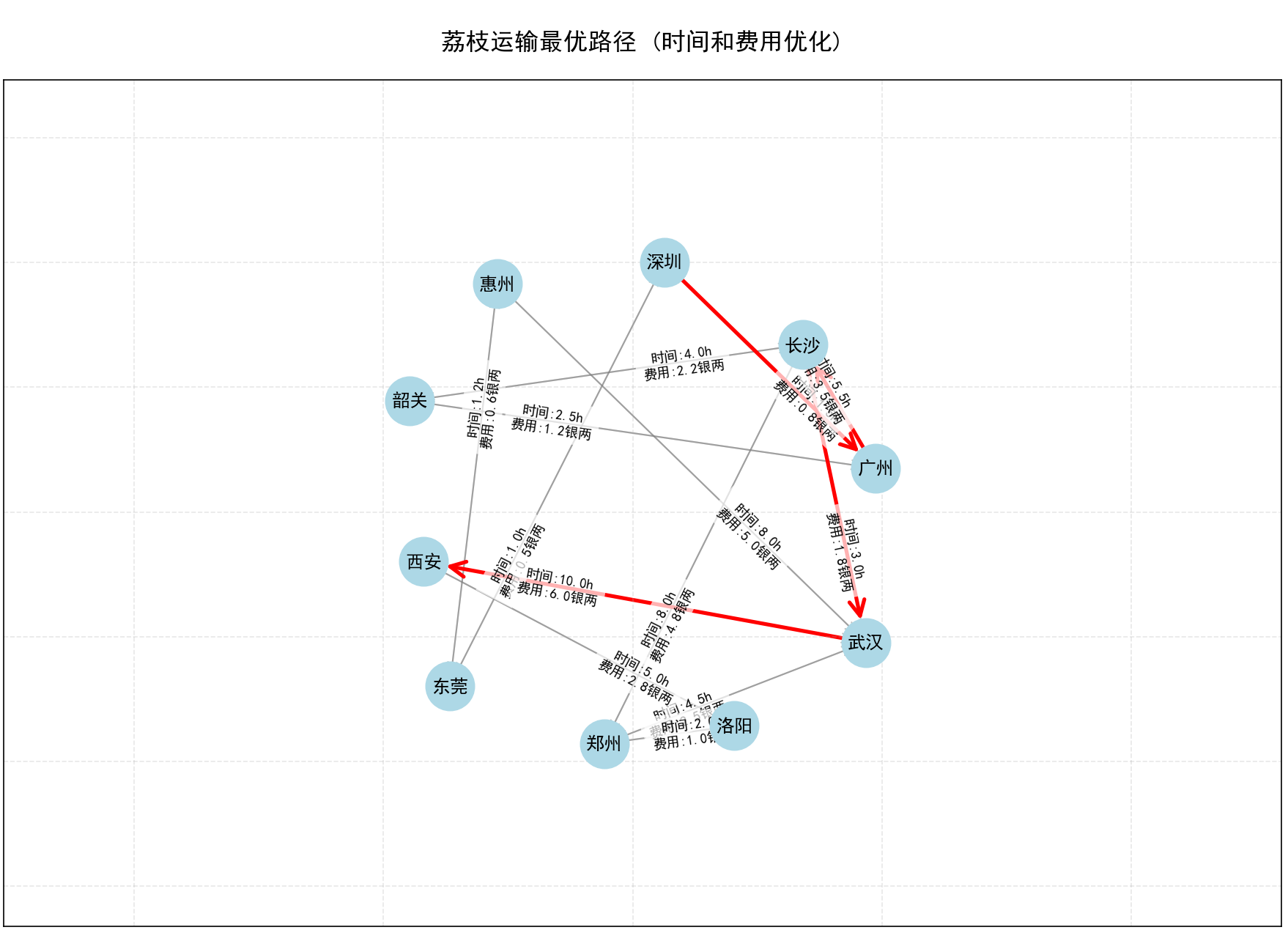
综合成本 = α*时间 + β*费用这不就是成年人的日常抉择吗?在时间和金钱间寻找平衡点。
新的城市图数据结构(包含时间和费用)如下:
city_graph2 = {
'深圳': {
'广州': {'time': 1.5, 'cost': 0.8}, # 高速公路,费用适中
'东莞': {'time': 1.0, 'cost': 0.5} # 短距离,费用低
},
'广州': {
'深圳': {'time': 1.5, 'cost': 0.8},
'韶关': {'time': 2.5, 'cost': 1.2}, # 中等距离,费用适中
'长沙': {'time': 5.5, 'cost': 3.5} # 长距离,费用高
},
'东莞': {
'深圳': {'time': 1.0, 'cost': 0.5},
'惠州': {'time': 1.2, 'cost': 0.6} # 短距离,费用低
},
'惠州': {
'东莞': {'time': 1.2, 'cost': 0.6},
'武汉': {'time': 8.0, 'cost': 5.0} # 长距离,费用高
},
'韶关': {
'广州': {'time': 2.5, 'cost': 1.2},
'长沙': {'time': 4.0, 'cost': 2.2} # 中等距离,费用适中
},
'长沙': {
'韶关': {'time': 4.0, 'cost': 2.2},
'武汉': {'time': 3.0, 'cost': 1.8}, # 中等距离,费用适中
'郑州': {'time': 8.0, 'cost': 4.8} # 长距离,费用高
},
'武汉': {
'惠州': {'time': 8.0, 'cost': 5.0},
'长沙': {'time': 3.0, 'cost': 1.8},
'郑州': {'time': 4.5, 'cost': 2.5}, # 中等距离,费用适中
'西安': {'time': 10.0, 'cost': 6.0} # 长距离,费用高,但有特殊路线
},
'郑州': {
'长沙': {'time': 8.0, 'cost': 4.8},
'武汉': {'time': 4.5, 'cost': 2.5},
'洛阳': {'time': 2.0, 'cost': 1.0} # 短距离,费用低
},
'洛阳': {
'郑州': {'time': 2.0, 'cost': 1.0},
'西安': {'time': 5.0, 'cost': 2.8} # 中等距离,费用适中
},
'西安': {
'武汉': {'time': 10.0, 'cost': 6.0},
'洛阳': {'time': 5.0, 'cost': 2.8}
}
}修改后代码如下:
def weighted_dijkstra(graph, start, end, time_weight=0.5, cost_weight=0.5):
# 初始化距离字典,所有城市距离设为无穷大
distances = {city: float('infinity') for city in graph}
distances[start] = 0
# 优先队列,存储(加权距离, 当前城市, 路径, 总时间, 总费用)
heap = [(0, start, [start], 0, 0)]
heapq.heapify(heap)
while heap:
current_weighted_dist, current_city, path, total_time, total_cost = heapq.heappop(heap)
# 如果到达终点,返回结果
if current_city == end:
return current_weighted_dist, total_time, total_cost, path
# 如果当前加权距离大于已知距离,跳过
if current_weighted_dist > distances[current_city]:
continue
# 遍历邻居城市
for neighbor, edge_data in graph[current_city].items():
time = edge_data['time']
cost = edge_data['cost']
# 计算加权距离
weighted_dist = time_weight * time + cost_weight * cost
new_weighted_dist = current_weighted_dist + weighted_dist
new_total_time = total_time + time
new_total_cost = total_cost + cost
# 如果找到更优路径,更新距离并加入堆
if new_weighted_dist < distances[neighbor]:
distances[neighbor] = new_weighted_dist
heapq.heappush(heap, (new_weighted_dist, neighbor, path + [neighbor],
new_total_time, new_total_cost))
return float('infinity'), float('infinity'), float('infinity'), [] # 如果没有路径这是一个加权Dijkstra算法,同时考虑时间和费用
参数:
graph: 包含时间和费用的图
start: 起点城市
end: 终点城市
time_weight: 时间权重 (0-1)
cost_weight: 费用权重 (0-1)
返回:
(总加权值, 总时间, 总费用, 路径)
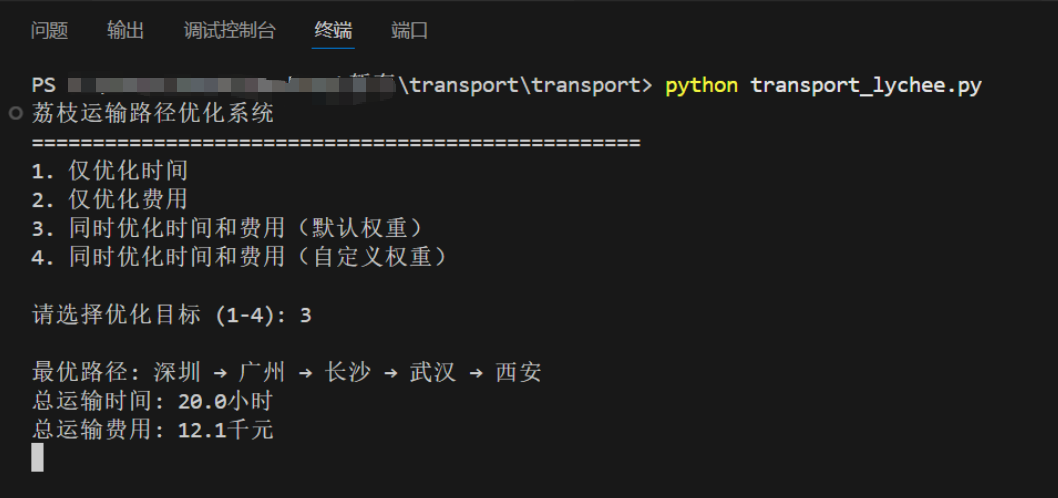
运行结果如下:
输出:
4. 断路与重生
实现"断路模拟"功能时:
def remove_edge(graph, city1, city2):
"""
从图中临时删除一条边(城市之间的连接)
参数:
graph: 城市图数据结构
city1: 第一个城市
city2: 第二个城市
返回:
修改后的图(深拷贝)
"""
import copy
# 创建图的深拷贝,避免修改原始图
modified_graph = copy.deepcopy(graph)
# 检查边是否存在,然后删除
if city2 in modified_graph.get(city1, {}):
del modified_graph[city1][city2]
print(f"已删除边: {city1} → {city2}")
# 删除反向边(如果存在)
if city1 in modified_graph.get(city2, {}):
del modified_graph[city2][city1]
print(f"已删除边: {city2} → {city1}")
return modified_graph这让我想到2020年疫情时的航线中断。系统能自动重新规划路线,人生不也该如此?
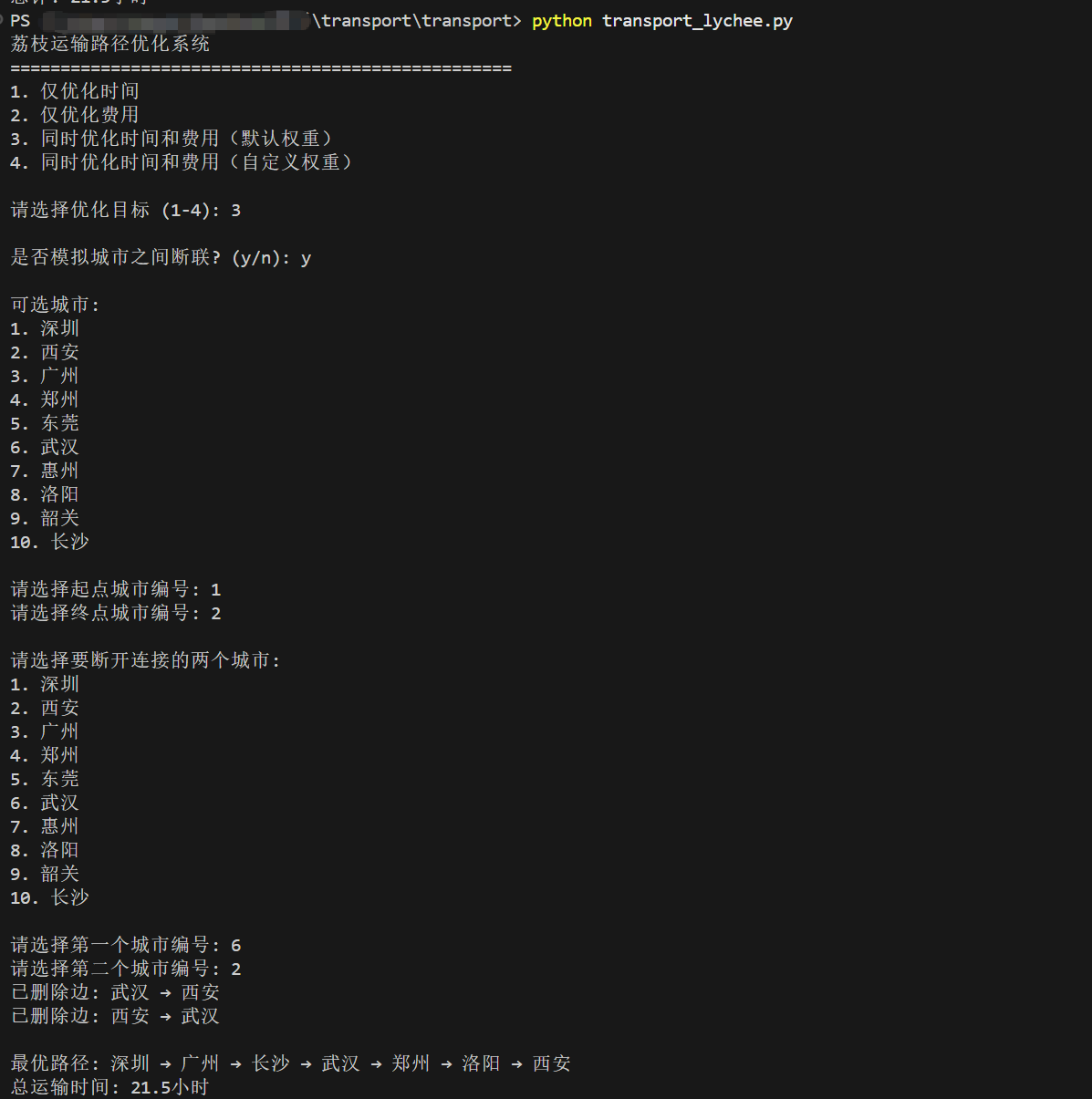
断边模拟功能:添加了模拟城市之间断联的功能,允许用户:
选择是否模拟断边情况
选择要断开连接的两个城市
在断边后的图上计算最优路径。
这其实并不复杂,只是简单在修改图后,把Dijkstra再运行了一遍。
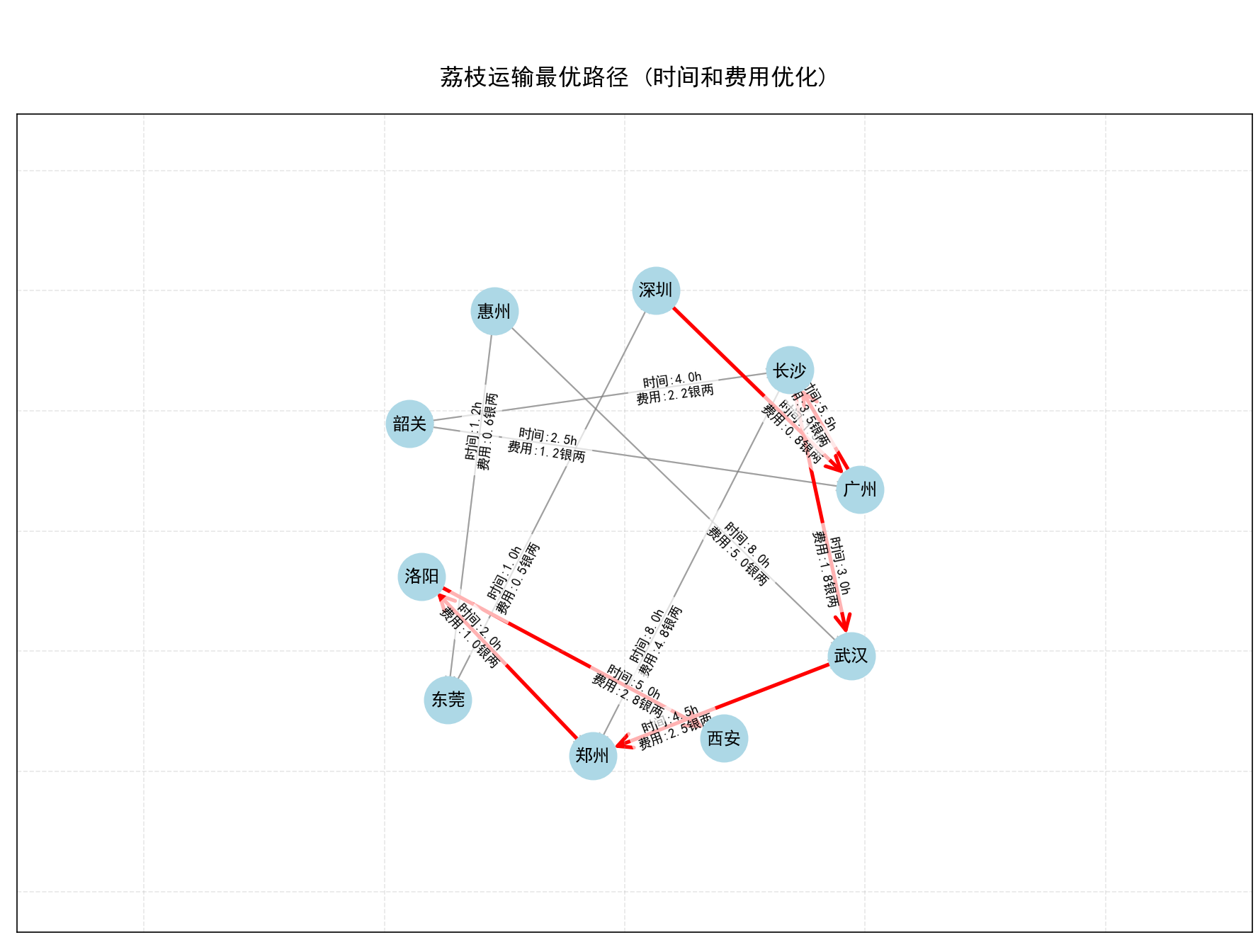
结语:代码如诗
本项目圆满完成了荔枝运输任务,并实现了两个进阶任务:
- 加入费用优化✅ 比如每段路程有个运输费用字段,你可以做双目标选择(费用 vs 时间),甚至加入权重因子。
- 加入断路逻辑✅ 如果城市之间突然“断联”,你可以在图中临时删除某条边再重新运行算法,模拟现实变化。
完成这个项目后,我重新理解了杜牧的诗句。如今:
- "一骑红尘"变成了红色高亮路径
- "妃子笑"化作控制台的输出笑脸
- "无人知"的艰辛藏在算法复杂度里
或许,每个程序员都是数字时代的驿站使者,用代码传递着另类的"荔枝"。

"代码写久了,看什么都像对象;算法想深了,看什么都像图。" —— 某程序员在调试时的顿悟
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号