第九章 源码分析(三)
原创

压缩列表 - zipList
ZipList是一种特殊的"双端链表",由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作,并且该操作的时间复杂度为O(1) (oxff:11111111)
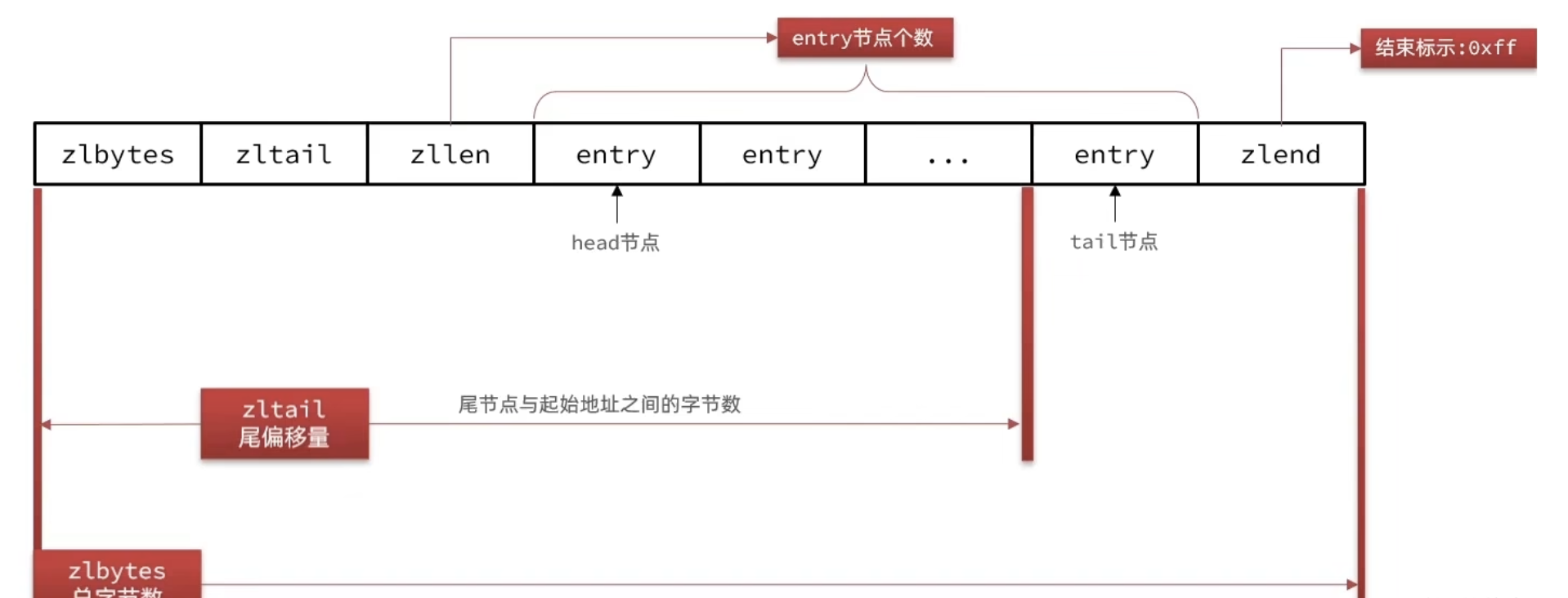
zipList结构
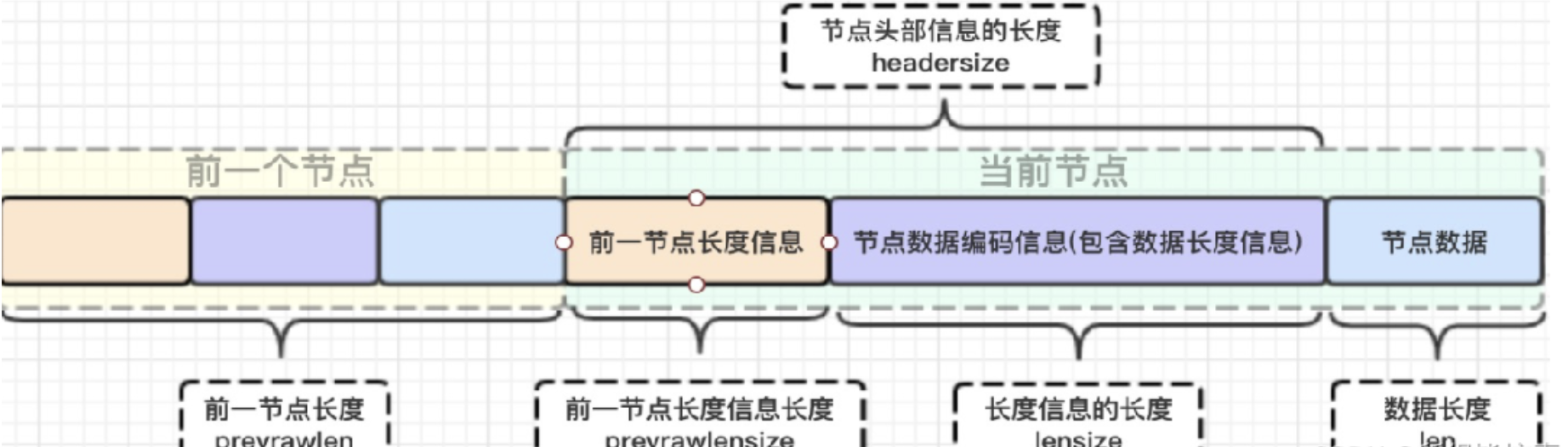
typedef struct zlentry {
unsigned int prevrawlensize; /* 上一个链表节点占用的长度*/
unsigned int prevrawlen; /* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数*/
unsigned int len; /* 当前链表节点所占用长度 */
unsigned int headersize; /* 当前链表节点的头部大小:prevrawlensize + lensize. */
unsigned char encoding; /* 编码方式*/
unsigned char *p; /* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
} zlentry;
ZipList中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构
1、previous_entry_length:前一节点的长度,占1个或5个字节
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
2、encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
3、contents:负责保存节点的数据,可以是字符串或整数
4、ZipListEntry中的encoding编码分为字符串和整数两种:如下所示④⑤所示
5、 字符串:如果encoding是以"00"、"01"或者"10"开头,则证明content是字符串
例如,我们要保存字符串:"ab"和 “bc”

存储ab和bc
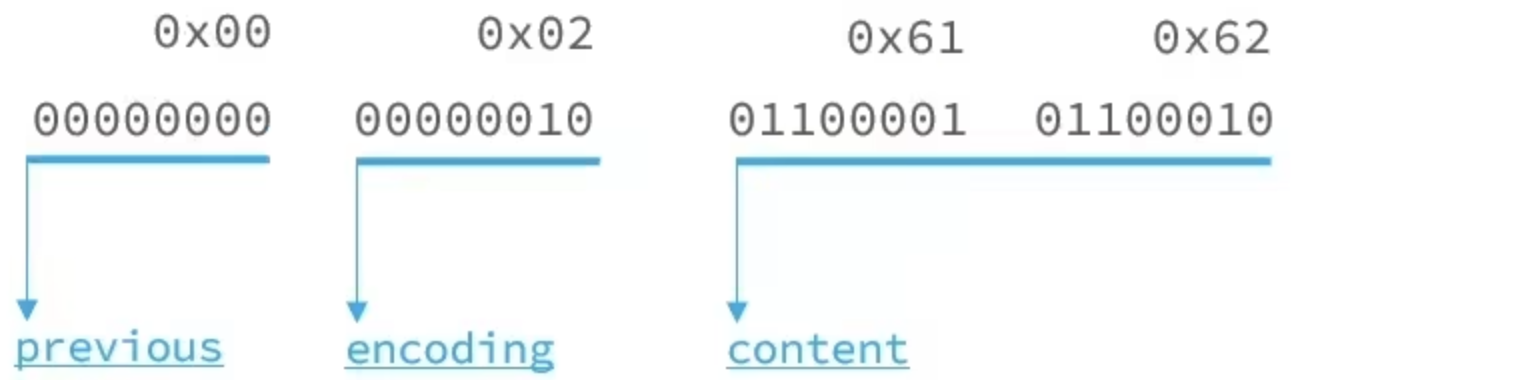
存储结构

存储结构说明
整数:如果encoding是以"11"开始,则证明content是整数,且encoding固定只占用1个字节
ZipList的连锁更新问题
1、ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
2、现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示: 这个时候在头节点插入一个254byte的entry

图1

图2
ZipList特性:
- 压缩列表的可以看做一种连续内存空间的"双向链表"
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
ziplist
明明有链表了,为什么出来一个压缩链表?
- 普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失。ziplist是一个特殊的双向链表没有维护双向指针: prev next;而是存储上一个entry的长度和当前entry的长度,通过长度推算下一个元素在什么地方
- 链表在内存中一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题
- 头节点里有头节点里同时还有一个参数len,和string类型提到的SDS 类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到len值就可以了,这个时间复杂度是 O(1)
快递列表 - QuickList
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
我们可以创建多个ZipList来分片存储数据
③. 数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?

quickList
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制
- 如果值为正,则代表ZipList的允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:(其默认值为 -2)
-1:每个ZipList的内存占用不能超过4kb
-2:每个ZipList的内存占用不能超过8kb
-3:每个ZipList的内存占用不能超过16kb
-4:每个ZipList的内存占用不能超过32kb
-5:每个ZipList的内存占用不能超过64kbziplist压缩配置:list-compress-depth 0:表示一个quicklist两端不被压缩的节点个数。这里的节点是指quicklist双向链表的节点,而不是指ziplist里面的数据项个数,参数list-compress-depth的取值含义如下:
0: 是个特殊值,表示都不压缩。这是Redis的默认值
1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩
2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩
3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩
依此类推…以下是QuickList的和QuickListNode的结构源码:
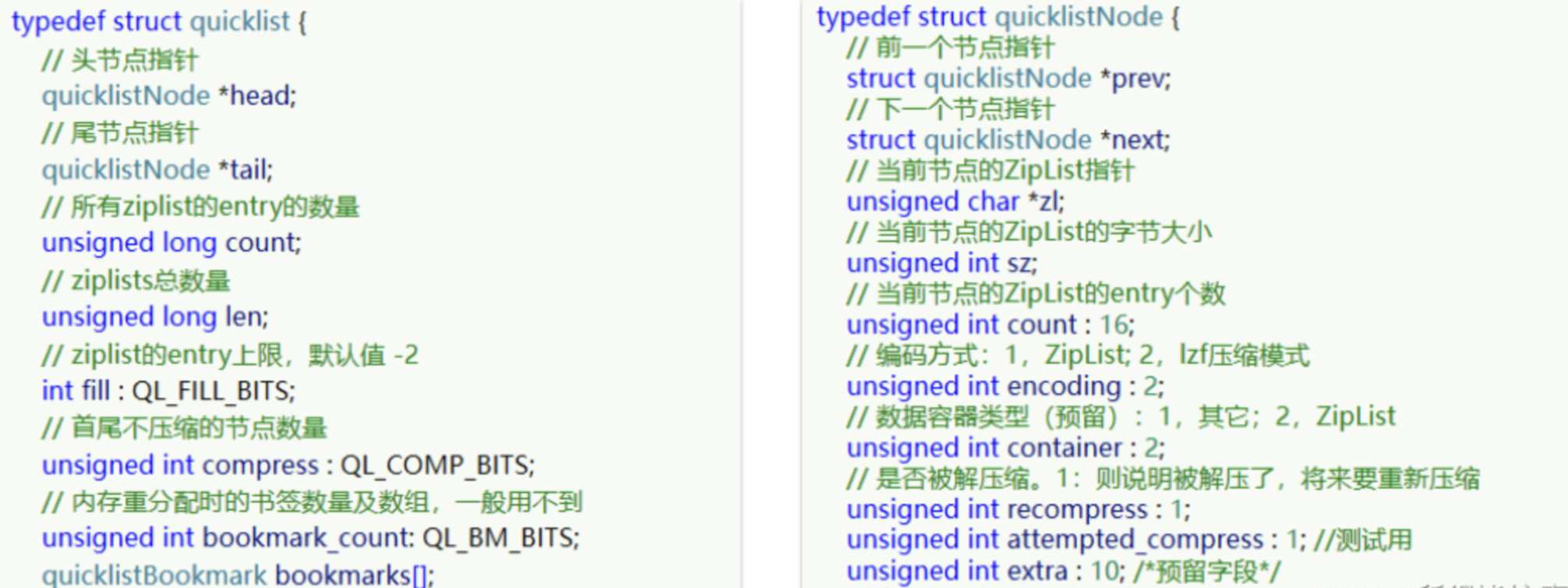
quickList结构
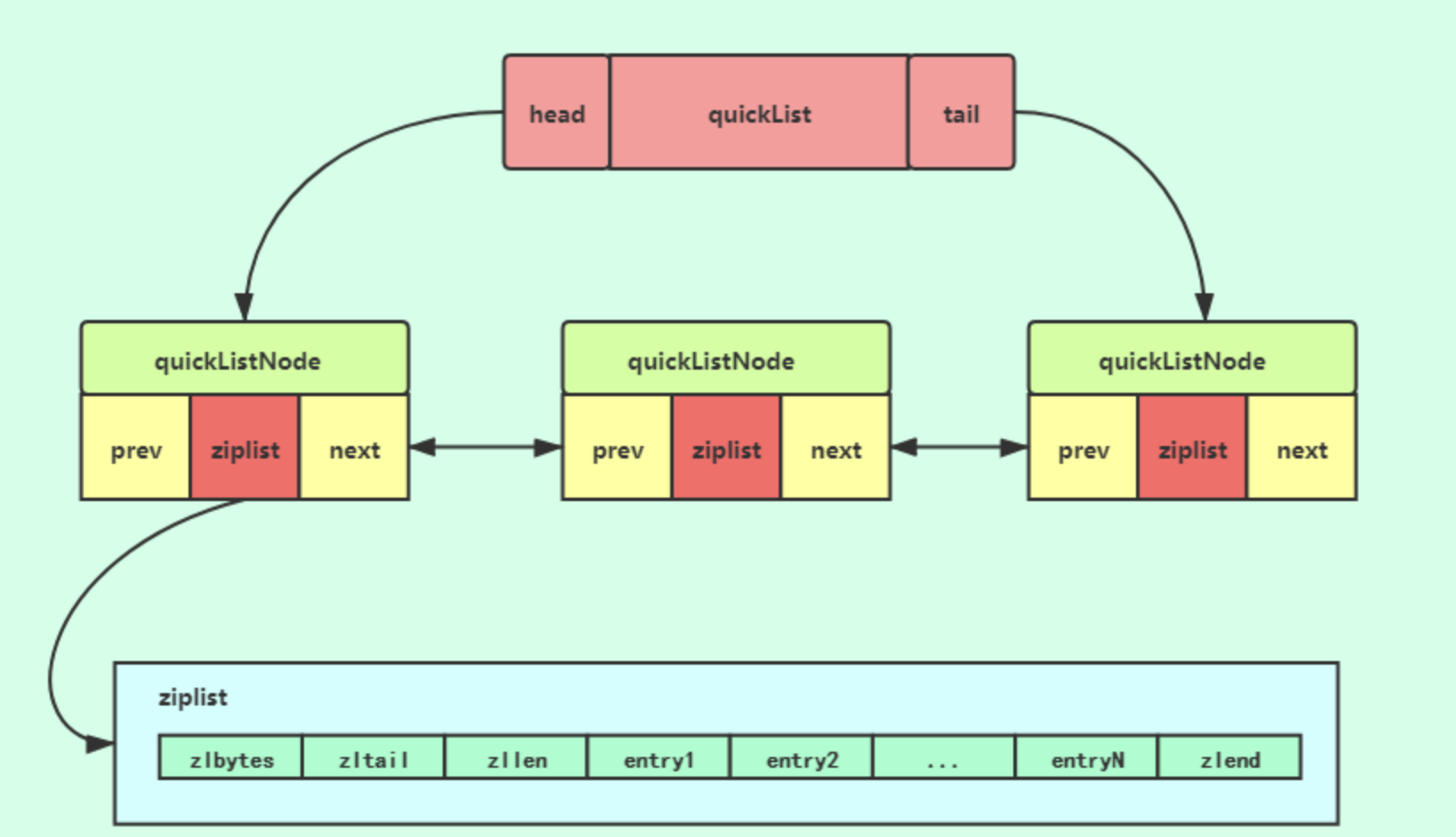
quickList结构说明1
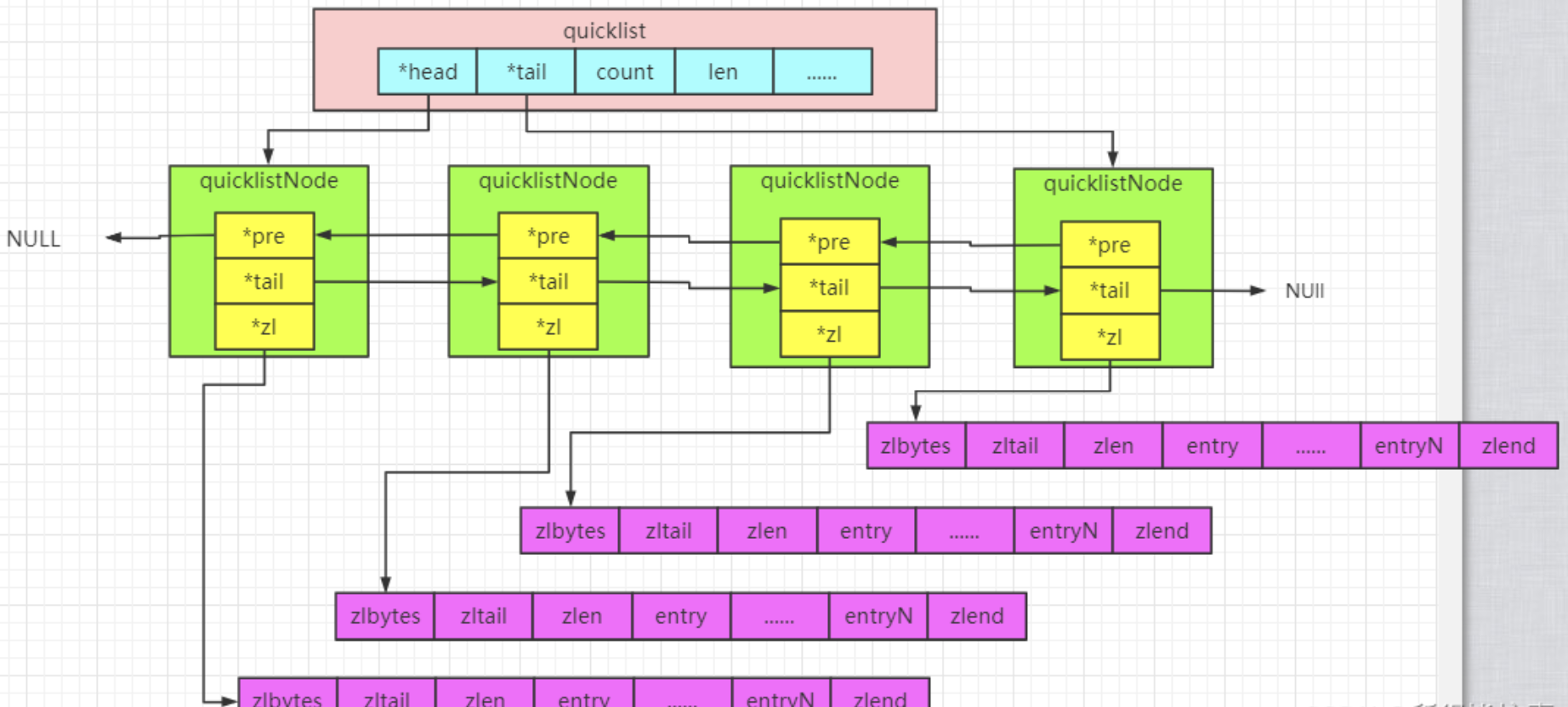
quickList结构说明2
我们接下来用一段流程图来描述当前的这个结构
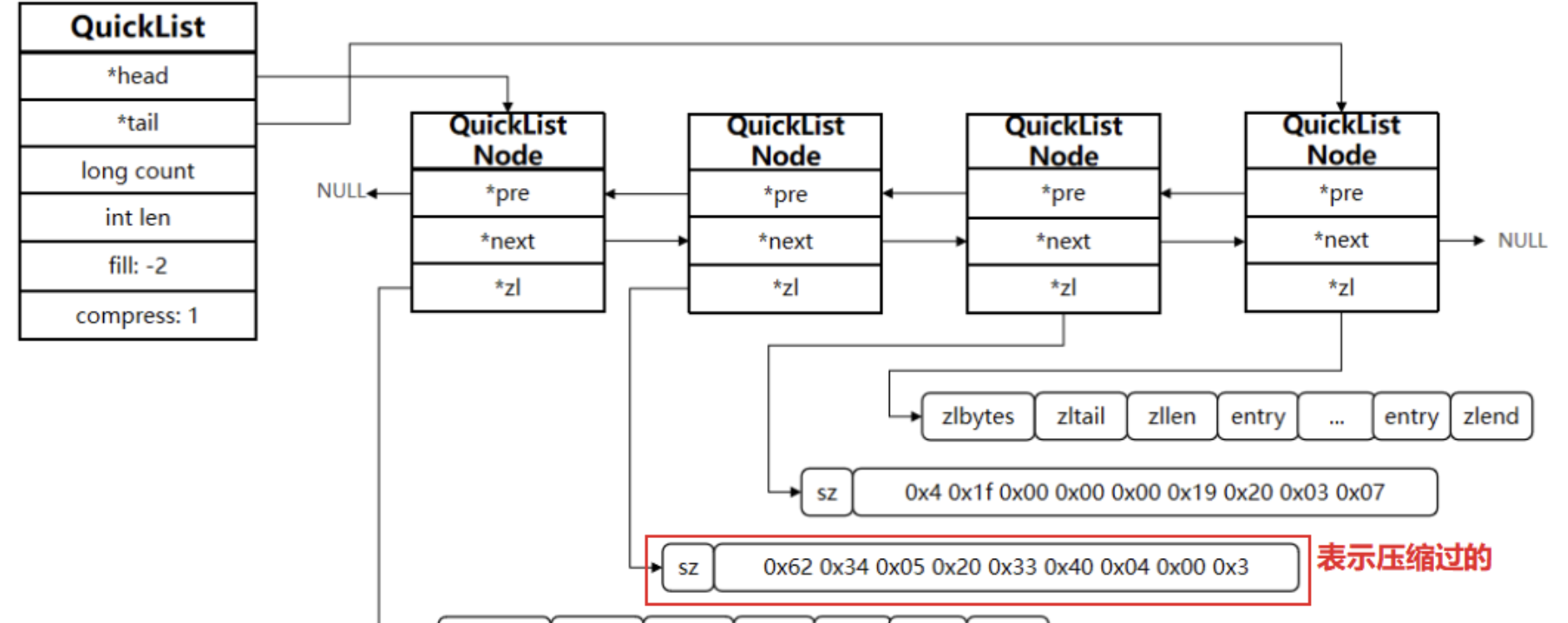
quickList结构说明3
QuickList的特点:
- 是一个节点为ZipList的双端链表
- 节点采用ZipList,解决了传统链表的内存占用问题
- 控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号