如何快速掌握Python语言--完整学习指南

如何快速掌握Python语言--完整学习指南

TechVision大咖圈
发布于 2025-06-13 12:08:53
发布于 2025-06-13 12:08:53
1. 为什么选择Python
Python是当今最受欢迎的编程语言之一,被广泛应用于各个领域。选择Python的理由包括:
🌟 Python的核心优势
简洁易学
- 语法接近自然语言,易于理解
- 代码简洁,开发效率高
- 学习曲线平缓,适合初学者
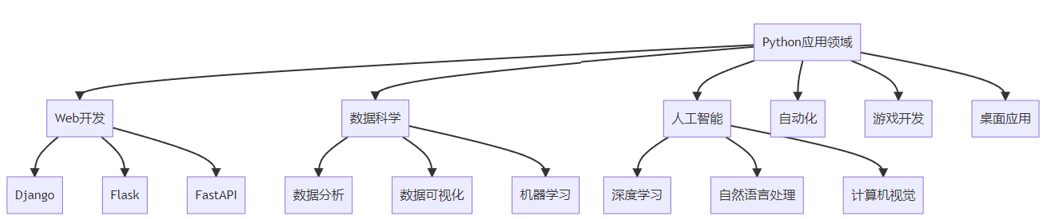
应用广泛
- Web开发:Django、Flask框架
- 数据科学:pandas、numpy、matplotlib
- 人工智能:TensorFlow、PyTorch
- 自动化脚本:系统管理、测试自动化
- 游戏开发:pygame
- 桌面应用:tkinter、PyQt
强大生态
- 丰富的第三方库
- 活跃的开源社区
- 完善的文档支持
2. 环境搭建与工具准备
🔧 Python安装
Windows系统
- 访问 https://python.org 下载最新版本
- 勾选"Add Python to PATH"
- 选择"Customize installation"
- 安装pip和IDLE
macOS系统
# 使用Homebrew安装
brew install python3
# 验证安装
python3 --versionLinux系统
# Ubuntu/Debian
sudo apt update
sudo apt install python3 python3-pip
# CentOS/RHEL
sudo yum install python3 python3-pip🛠️ 开发环境推荐
集成开发环境(IDE)
工具 | 特点 | 适用场景 |
|---|---|---|
PyCharm | 功能强大,智能提示 | 大型项目开发 |
VS Code | 轻量级,插件丰富 | 日常开发 |
Jupyter Notebook | 交互式编程 | 数据科学 |
Sublime Text | 快速响应 | 简单脚本 |
推荐插件配置
- Python扩展
- Code Runner
- GitLens
- Bracket Pair Colorizer
📦 包管理工具
pip基础命令
# 安装包
pip install package_name
# 安装指定版本
pip install package_name==1.2.3
# 批量安装
pip install -r requirements.txt
# 升级包
pip install --upgrade package_name
# 卸载包
pip uninstall package_name
# 查看已安装包
pip list虚拟环境管理
# 创建虚拟环境
python -m venv myenv
# 激活虚拟环境
# Windows
myenv\Scripts\activate
# macOS/Linux
source myenv/bin/activate
# 退出虚拟环境
deactivate3. Python基础语法速成
📝 变量与数据类型
基本数据类型
# 数字类型
age = 25 # 整数
height = 175.5 # 浮点数
complex_num = 3 + 4j # 复数
# 字符串
name = "Python"
description = '''这是一个
多行字符串'''
# 布尔值
is_active = True
is_completed = False
# 列表(可变)
fruits = ["apple", "banana", "orange"]
numbers = [1, 2, 3, 4, 5]
# 元组(不可变)
coordinates = (10, 20)
colors = ("red", "green", "blue")
# 字典
person = {
"name": "Alice",
"age": 30,
"city": "Beijing"
}
# 集合
unique_numbers = {1, 2, 3, 4, 5}🔄 控制流程
条件语句
score = 85
if score >= 90:
grade = "A"
elif score >= 80:
grade = "B"
elif score >= 70:
grade = "C"
else:
grade = "D"
print(f"成绩等级: {grade}")循环语句
# for循环
fruits = ["apple", "banana", "orange"]
for fruit in fruits:
print(f"我喜欢{fruit}")
# range()函数
for i in range(1, 6): # 1到5
print(f"数字: {i}")
# while循环
count = 0
while count < 5:
print(f"计数: {count}")
count += 1
# 列表推导式
squares = [x**2 for x in range(1, 6)]
print(squares) # [1, 4, 9, 16, 25]🔧 函数定义
基础函数
def greet(name, age=18):
"""问候函数"""
return f"你好,{name}!你今年{age}岁。"
# 调用函数
message = greet("小明", 25)
print(message)
# 默认参数
message2 = greet("小红") # 使用默认年龄
print(message2)高级函数特性
# 可变参数
def calculate_sum(*args):
return sum(args)
result = calculate_sum(1, 2, 3, 4, 5)
print(result) # 15
# 关键字参数
def create_profile(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
create_profile(name="Alice", age=30, city="Shanghai")
# lambda函数
square = lambda x: x**2
print(square(5)) # 25
# map和filter
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
evens = list(filter(lambda x: x % 2 == 0, numbers))4. 核心概念深度学习
🏗️ 面向对象编程
类与对象
class Student:
# 类变量
school = "Python大学"
def __init__(self, name, age):
# 实例变量
self.name = name
self.age = age
self.courses = []
def add_course(self, course):
"""添加课程"""
self.courses.append(course)
print(f"{self.name}选择了{course}课程")
def display_info(self):
"""显示学生信息"""
print(f"姓名: {self.name}")
print(f"年龄: {self.age}")
print(f"学校: {self.school}")
print(f"课程: {', '.join(self.courses)}")
def __str__(self):
return f"Student({self.name}, {self.age})"
# 创建对象
student1 = Student("小明", 20)
student1.add_course("Python编程")
student1.add_course("数据结构")
student1.display_info()继承与多态
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
pass
class Dog(Animal):
def speak(self):
return f"{self.name}说: 汪汪!"
class Cat(Animal):
def speak(self):
return f"{self.name}说: 喵喵!"
# 多态演示
animals = [Dog("旺财"), Cat("咪咪")]
for animal in animals:
print(animal.speak())📂 文件操作
文件读写
# 写入文件
data = ["Python", "Java", "C++", "JavaScript"]
with open("languages.txt", "w", encoding="utf-8") as file:
for lang in data:
file.write(lang + "\n")
# 读取文件
with open("languages.txt", "r", encoding="utf-8") as file:
content = file.read()
print(content)
# 逐行读取
with open("languages.txt", "r", encoding="utf-8") as file:
lines = file.readlines()
for line in lines:
print(line.strip())JSON处理
import json
# 字典转JSON
data = {
"name": "Python学习指南",
"author": "AI助手",
"chapters": 10,
"published": True
}
# 写入JSON文件
with open("book.json", "w", encoding="utf-8") as file:
json.dump(data, file, ensure_ascii=False, indent=2)
# 读取JSON文件
with open("book.json", "r", encoding="utf-8") as file:
loaded_data = json.load(file)
print(loaded_data)⚠️ 异常处理
def divide_numbers(a, b):
try:
result = a / b
return result
except ZeroDivisionError:
print("错误:除数不能为零!")
return None
except TypeError:
print("错误:输入必须是数字!")
return None
except Exception as e:
print(f"未知错误:{e}")
return None
finally:
print("计算完成")
# 测试异常处理
print(divide_numbers(10, 2)) # 5.0
print(divide_numbers(10, 0)) # 错误处理
print(divide_numbers("10", 2)) # 类型错误5. Python学习路径规划
🗺️ 学习阶段划分
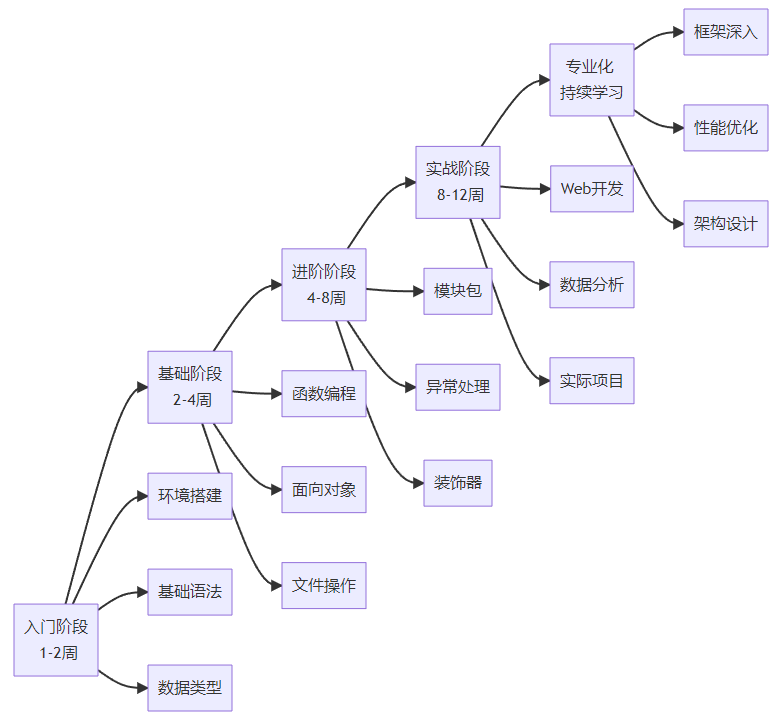
📅 详细学习计划
第1-2周:Python入门
- 目标:熟悉Python基础语法
- 内容:
- 环境搭建与工具使用
- 变量、数据类型、运算符
- 字符串操作
- 列表、元组、字典操作
- 练习:完成50道基础语法题
第3-4周:控制流程与函数
- 目标:掌握程序控制和函数编程
- 内容:
- if/elif/else条件语句
- for/while循环
- 函数定义与调用
- 参数传递机制
- 练习:编写10个小程序
第5-6周:面向对象编程
- 目标:理解OOP核心概念
- 内容:
- 类与对象
- 继承与多态
- 封装与抽象
- 特殊方法
- 练习:设计简单的类层次结构
第7-8周:模块与包
- 目标:学会代码组织和重用
- 内容:
- 模块导入机制
- 包的创建与使用
- 标准库介绍
- 第三方库安装
- 练习:创建自己的工具包
第9-12周:实战项目
- 目标:通过项目巩固知识
- 项目选择:
- 计算器程序
- 文件管理工具
- 简单爬虫
- 数据分析项目
🎯 学习里程碑
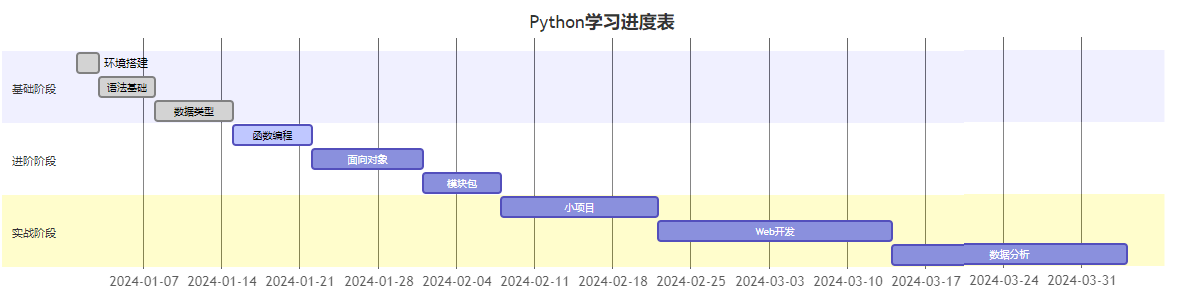
6. 实战项目推荐
🚀 初级项目
1. 个人理财管理器
class FinanceManager:
def __init__(self):
self.transactions = []
def add_income(self, amount, description):
"""添加收入"""
self.transactions.append({
'type': 'income',
'amount': amount,
'description': description,
'date': datetime.now().strftime('%Y-%m-%d')
})
print(f"添加收入: {amount}元 - {description}")
def add_expense(self, amount, description):
"""添加支出"""
self.transactions.append({
'type': 'expense',
'amount': amount,
'description': description,
'date': datetime.now().strftime('%Y-%m-%d')
})
print(f"添加支出: {amount}元 - {description}")
def get_balance(self):
"""计算余额"""
income = sum(t['amount'] for t in self.transactions if t['type'] == 'income')
expense = sum(t['amount'] for t in self.transactions if t['type'] == 'expense')
return income - expense
def generate_report(self):
"""生成报告"""
balance = self.get_balance()
print(f"\n=== 财务报告 ===")
print(f"当前余额: {balance}元")
print(f"交易记录数: {len(self.transactions)}")
# 使用示例
fm = FinanceManager()
fm.add_income(5000, "工资")
fm.add_expense(1500, "房租")
fm.add_expense(800, "生活费")
fm.generate_report()2. 简单网络爬虫
import requests
from bs4 import BeautifulSoup
import csv
class NewsSpider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
def get_news(self, url):
"""获取新闻列表"""
try:
response = requests.get(url, headers=self.headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
news_list = []
# 根据实际网站结构调整选择器
articles = soup.find_all('article', class_='news-item')
for article in articles:
title = article.find('h2').text.strip()
link = article.find('a')['href']
time = article.find('time').text.strip()
news_list.append({
'title': title,
'link': link,
'time': time
})
return news_list
except Exception as e:
print(f"爬取失败: {e}")
return []
def save_to_csv(self, news_list, filename):
"""保存到CSV文件"""
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=['title', 'link', 'time'])
writer.writeheader()
writer.writerows(news_list)
print(f"新闻已保存到 {filename}")
# 使用示例
spider = NewsSpider()
news = spider.get_news("https://example-news-site.com")
spider.save_to_csv(news, "latest_news.csv")🌟 中级项目
3. Flask Web应用
from flask import Flask, render_template, request, jsonify
import sqlite3
app = Flask(__name__)
class TaskManager:
def __init__(self):
self.init_db()
def init_db(self):
"""初始化数据库"""
conn = sqlite3.connect('tasks.db')
c = conn.cursor()
c.execute('''
CREATE TABLE IF NOT EXISTS tasks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT,
completed BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
conn.commit()
conn.close()
def add_task(self, title, description):
"""添加任务"""
conn = sqlite3.connect('tasks.db')
c = conn.cursor()
c.execute(
"INSERT INTO tasks (title, description) VALUES (?, ?)",
(title, description)
)
conn.commit()
conn.close()
def get_all_tasks(self):
"""获取所有任务"""
conn = sqlite3.connect('tasks.db')
c = conn.cursor()
c.execute("SELECT * FROM tasks ORDER BY created_at DESC")
tasks = c.fetchall()
conn.close()
return tasks
task_manager = TaskManager()
@app.route('/')
def index():
tasks = task_manager.get_all_tasks()
return render_template('index.html', tasks=tasks)
@app.route('/add_task', methods=['POST'])
def add_task():
title = request.form['title']
description = request.form['description']
task_manager.add_task(title, description)
return jsonify({'status': 'success'})
if __name__ == '__main__':
app.run(debug=True)🎖️ 高级项目
4. 数据分析仪表板
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime, timedelta
import numpy as np
class DataAnalyzer:
def __init__(self):
self.data = None
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体
plt.rcParams['axes.unicode_minus'] = False
def load_data(self, file_path):
"""加载数据"""
try:
if file_path.endswith('.csv'):
self.data = pd.read_csv(file_path)
elif file_path.endswith('.xlsx'):
self.data = pd.read_excel(file_path)
print(f"数据加载成功,共{len(self.data)}行{len(self.data.columns)}列")
return True
except Exception as e:
print(f"数据加载失败: {e}")
return False
def basic_statistics(self):
"""基础统计分析"""
if self.data is None:
print("请先加载数据")
return
print("=== 数据基本信息 ===")
print(self.data.info())
print("\n=== 描述性统计 ===")
print(self.data.describe())
print("\n=== 缺失值统计 ===")
print(self.data.isnull().sum())
def create_visualizations(self):
"""创建可视化图表"""
if self.data is None:
print("请先加载数据")
return
fig, axes = plt.subplots(2, 2, figsize=(15, 12))
# 数值列分布
numeric_columns = self.data.select_dtypes(include=[np.number]).columns
if len(numeric_columns) > 0:
self.data[numeric_columns[0]].hist(bins=30, ax=axes[0,0])
axes[0,0].set_title(f'{numeric_columns[0]} 分布')
# 相关性热力图
if len(numeric_columns) > 1:
correlation = self.data[numeric_columns].corr()
sns.heatmap(correlation, annot=True, ax=axes[0,1])
axes[0,1].set_title('相关性热力图')
# 箱线图
if len(numeric_columns) > 0:
self.data[numeric_columns].boxplot(ax=axes[1,0])
axes[1,0].set_title('箱线图')
# 数据趋势
if len(numeric_columns) > 1:
axes[1,1].plot(self.data[numeric_columns[0]],
self.data[numeric_columns[1]], 'o-')
axes[1,1].set_title('数据趋势')
plt.tight_layout()
plt.savefig('data_analysis_report.png', dpi=300, bbox_inches='tight')
plt.show()
def generate_report(self):
"""生成分析报告"""
if self.data is None:
print("请先加载数据")
return
report = f"""
# 数据分析报告
## 数据概览
- **数据行数**: {len(self.data)}
- **数据列数**: {len(self.data.columns)}
- **生成时间**: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
## 数据质量
- **完整率**: {(1 - self.data.isnull().sum().sum() / (len(self.data) * len(self.data.columns))) * 100:.2f}%
- **重复行数**: {self.data.duplicated().sum()}
## 主要发现
{self._generate_insights()}
## 建议
{self._generate_recommendations()}
"""
with open('analysis_report.md', 'w', encoding='utf-8') as f:
f.write(report)
print("分析报告已生成: analysis_report.md")
def _generate_insights(self):
"""生成数据洞察"""
insights = []
numeric_columns = self.data.select_dtypes(include=[np.number]).columns
for col in numeric_columns:
mean_val = self.data[col].mean()
std_val = self.data[col].std()
insights.append(f"- {col}: 平均值 {mean_val:.2f}, 标准差 {std_val:.2f}")
return '\n'.join(insights)
def _generate_recommendations(self):
"""生成建议"""
recommendations = [
"- 定期更新数据以确保分析结果的时效性",
"- 关注异常值,它们可能包含重要信息",
"- 考虑使用更多维度的数据进行深入分析"
]
return '\n'.join(recommendations)
# 使用示例
analyzer = DataAnalyzer()
if analyzer.load_data('sample_data.csv'):
analyzer.basic_statistics()
analyzer.create_visualizations()
analyzer.generate_report()7. 进阶学习方向
🌐 Web开发路线
Framework选择对比
框架 | 特点 | 学习难度 | 适用场景 |
|---|---|---|---|
Django | 功能完整,ORM强大 | 中等 | 大型Web应用 |
Flask | 轻量级,灵活性高 | 简单 | 小型应用,API |
FastAPI | 现代化,自动文档 | 中等 | API开发 |
Tornado | 异步处理 | 较高 | 实时应用 |
Django学习路径
# 1. 项目创建
django-admin startproject myproject
cd myproject
python manage.py startapp myapp
# 2. 模型定义
# models.py
from django.db import models
class Article(models.Model):
title = models.CharField(max_length=200)
content = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
def __str__(self):
return self.title
# 3. 视图编写
# views.py
from django.shortcuts import render
from .models import Article
def article_list(request):
articles = Article.objects.all()
return render(request, 'articles/list.html', {'articles': articles})
# 4. URL配置
# urls.py
from django.urls import path
from . import views
urlpatterns = [
path('articles/', views.article_list, name='article_list'),
]📊 数据科学路线
核心库学习顺序
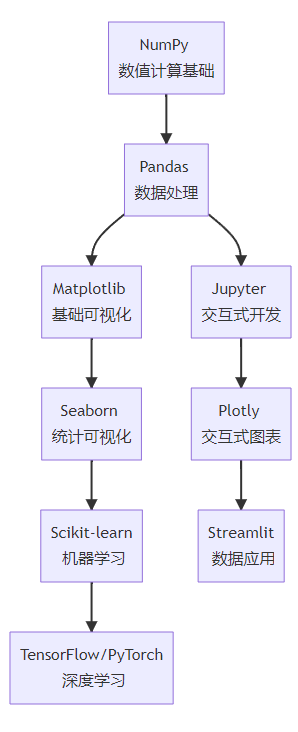
数据科学项目示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
class HousePricePrediction:
def __init__(self):
self.model = LinearRegression()
self.is_trained = False
def load_and_explore_data(self, file_path):
"""加载和探索数据"""
self.data = pd.read_csv(file_path)
print("=== 数据基本信息 ===")
print(f"数据形状: {self.data.shape}")
print(f"列名: {list(self.data.columns)}")
print("\n=== 前5行数据 ===")
print(self.data.head())
print("\n=== 缺失值统计 ===")
print(self.data.isnull().sum())
print("\n=== 数值列统计 ===")
print(self.data.describe())
def preprocess_data(self):
"""数据预处理"""
# 处理缺失值
self.data = self.data.dropna()
# 选择特征列
feature_columns = ['size', 'bedrooms', 'bathrooms', 'age']
self.X = self.data[feature_columns]
self.y = self.data['price']
print(f"特征矩阵形状: {self.X.shape}")
print(f"目标变量形状: {self.y.shape}")
def train_model(self, test_size=0.2):
"""训练模型"""
# 划分训练集和测试集
self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(
self.X, self.y, test_size=test_size, random_state=42
)
# 训练模型
self.model.fit(self.X_train, self.y_train)
self.is_trained = True
print("模型训练完成!")
# 预测
self.y_pred = self.model.predict(self.X_test)
# 评估
mse = mean_squared_error(self.y_test, self.y_pred)
r2 = r2_score(self.y_test, self.y_pred)
print(f"均方误差: {mse:.2f}")
print(f"R²得分: {r2:.4f}")
def visualize_results(self):
"""可视化结果"""
if not self.is_trained:
print("请先训练模型")
return
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# 实际值 vs 预测值
axes[0].scatter(self.y_test, self.y_pred, alpha=0.6)
axes[0].plot([self.y_test.min(), self.y_test.max()],
[self.y_test.min(), self.y_test.max()], 'r--', lw=2)
axes[0].set_xlabel('实际价格')
axes[0].set_ylabel('预测价格')
axes[0].set_title('实际价格 vs 预测价格')
# 残差图
residuals = self.y_test - self.y_pred
axes[1].scatter(self.y_pred, residuals, alpha=0.6)
axes[1].axhline(y=0, color='r', linestyle='--')
axes[1].set_xlabel('预测价格')
axes[1].set_ylabel('残差')
axes[1].set_title('残差分布图')
plt.tight_layout()
plt.savefig('prediction_results.png', dpi=300)
plt.show()
def predict_new_house(self, size, bedrooms, bathrooms, age):
"""预测新房价格"""
if not self.is_trained:
print("请先训练模型")
return None
new_data = np.array([[size, bedrooms, bathrooms, age]])
predicted_price = self.model.predict(new_data)[0]
print(f"房屋信息:")
print(f" 面积: {size}平方米")
print(f" 卧室: {bedrooms}间")
print(f" 浴室: {bathrooms}间")
print(f" 房龄: {age}年")
print(f"预测价格: {predicted_price:.2f}万元")
return predicted_price
# 使用示例
predictor = HousePricePrediction()
predictor.load_and_explore_data('house_prices.csv')
predictor.preprocess_data()
predictor.train_model()
predictor.visualize_results()
predictor.predict_new_house(120, 3, 2, 5)🤖 人工智能路线
AI学习路径
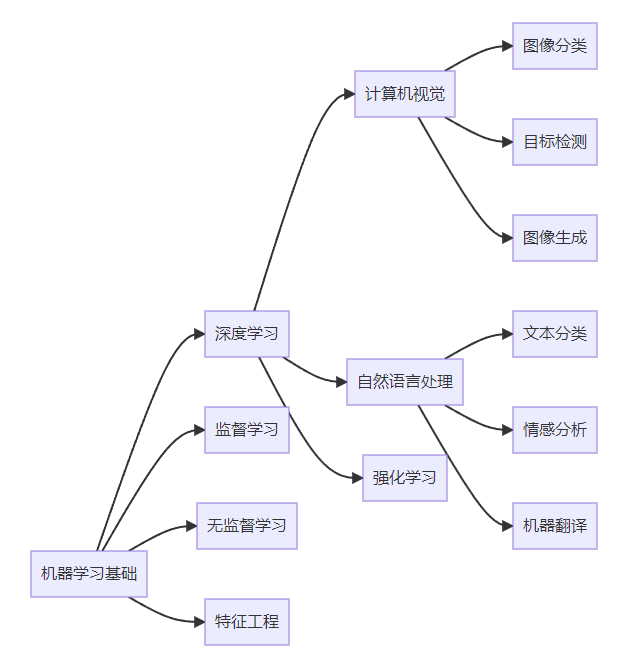
8. 学习资源与工具
📚 优质学习资源
官方文档
在线学习平台
平台 | 特色 | 适合人群 | 价格 |
|---|---|---|---|
Coursera | 大学课程,证书权威 | 系统学习 | 付费 |
edX | 免费课程丰富 | 自学者 | 免费/付费 |
Udemy | 实战项目多 | 技能提升 | 付费 |
菜鸟教程 | 中文友好 | 初学者 | 免费 |
实验楼 | 在线实验环境 | 实践学习 | 付费 |
书籍推荐
入门级
- 《Python编程:从入门到实践》- Eric Matthes
- 《笨办法学Python》- Zed Shaw
- 《Python核心编程》- Wesley Chun
进阶级
- 《流畅的Python》- Luciano Ramalho
- 《Effective Python》- Brett Slatkin
- 《Python Tricks》- Dan Bader
专业方向
- Web开发:《Django实战》
- 数据科学:《利用Python进行数据分析》
- 机器学习:《Python机器学习实战》
🛠️ 开发工具链
代码编辑器插件
VS Code推荐插件
{
"extensions": [
"ms-python.python",
"ms-python.vscode-pylance",
"ms-toolsai.jupyter",
"ms-vscode.vscode-json",
"formulahendry.code-runner",
"donjayamanne.githistory"
]
}调试工具
# 使用pdb调试
import pdb
def problematic_function(x, y):
pdb.set_trace() # 设置断点
result = x / y
return result
# 使用logging记录
import logging
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
def my_function():
logger.debug("开始执行函数")
logger.info("处理中...")
logger.warning("注意事项")
logger.error("出现错误")性能分析工具
# 使用timeit测量执行时间
import timeit
def test_function():
return sum(range(1000))
# 测量执行时间
time_taken = timeit.timeit(test_function, number=10000)
print(f"执行时间: {time_taken:.6f}秒")
# 使用cProfile分析性能
import cProfile
import pstats
def profile_function():
# 你的代码
pass
cProfile.run('profile_function()', 'profile_stats')
p = pstats.Stats('profile_stats')
p.sort_stats('cumulative').print_stats(10)🌟 实用库推荐
数据处理
# pandas - 数据分析
import pandas as pd
# numpy - 数值计算
import numpy as np
# matplotlib - 绘图
import matplotlib.pyplot as plt
# requests - HTTP请求
import requests
# beautifulsoup4 - 网页解析
from bs4 import BeautifulSoupWeb开发
# flask - 轻量级Web框架
from flask import Flask
# django - 全功能Web框架
import django
# fastapi - 现代API框架
from fastapi import FastAPI
# sqlalchemy - ORM
from sqlalchemy import create_engine工具库
# pathlib - 路径操作
from pathlib import Path
# datetime - 日期时间
from datetime import datetime
# json - JSON处理
import json
# os - 系统操作
import os
# sys - 系统参数
import sys9. 常见问题与解决方案
❓ 学习过程中的常见问题
Q1: Python2还是Python3? A: 强烈建议学习Python3。Python2已于2020年停止支持,Python3是未来的方向。
Q2: 如何选择IDE? A:
- 初学者:VS Code(免费、插件丰富)
- 专业开发:PyCharm(功能强大)
- 数据科学:Jupyter Notebook(交互式)
Q3: 学习多久可以找工作? A:
- 基础掌握:3-6个月
- 能做项目:6-12个月
- 就业水平:根据目标岗位而定
Q4: 如何提高编程思维? A:
- 多做算法题(LeetCode、牛客网)
- 参与开源项目
- 阅读优秀代码
- 实践项目开发
🐛 常见技术问题
编码问题
# 错误示例
with open('file.txt', 'r') as f: # 可能出现编码错误
content = f.read()
# 正确做法
with open('file.txt', 'r', encoding='utf-8') as f:
content = f.read()路径问题
# 错误示例
file_path = "data\test.txt" # Windows路径分隔符问题
# 正确做法
from pathlib import Path
file_path = Path("data") / "test.txt" # 跨平台兼容
# 或使用os.path
import os
file_path = os.path.join("data", "test.txt")内存问题
# 大文件处理 - 错误示例
with open('large_file.txt', 'r') as f:
content = f.read() # 可能内存不足
# 正确做法 - 逐行处理
with open('large_file.txt', 'r') as f:
for line in f:
process_line(line) # 逐行处理异常处理最佳实践
# 避免裸露的except
try:
risky_operation()
except: # 不好的做法
pass
# 推荐做法
try:
risky_operation()
except SpecificException as e:
logger.error(f"具体错误: {e}")
handle_error(e)
except Exception as e:
logger.error(f"未预期错误: {e}")
raise # 重新抛出异常💡 性能优化技巧
列表推导式 vs 循环
# 慢速方法
result = []
for i in range(1000):
if i % 2 == 0:
result.append(i ** 2)
# 快速方法
result = [i ** 2 for i in range(1000) if i % 2 == 0]
# 内存友好的生成器
result = (i ** 2 for i in range(1000) if i % 2 == 0)字符串连接优化
# 慢速方法
result = ""
for item in items:
result += str(item)
# 快速方法
result = "".join(str(item) for item in items)
# 格式化字符串(Python 3.6+)
name = "Python"
version = 3.9
message = f"欢迎使用{name} {version}"10. 总结与建议
🎯 学习要点总结
核心知识点回顾
mindmap
root((Python核心))
基础语法
变量类型
控制流程
函数定义
面向对象
类与对象
继承多态
特殊方法
标准库
文件操作
网络请求
数据处理
第三方库
Web框架
数据科学
机器学习
实战项目
爬虫程序
Web应用
数据分析📈 持续学习建议
1. 建立学习习惯
- 每天至少编码1小时
- 定期复习和总结
- 参与技术社区讨论
- 关注Python官方动态
2. 项目驱动学习
- 从小项目开始
- 逐步增加复杂度
- 关注代码质量
- 学会版本控制(Git)
3. 深度与广度并重
- 选择一个方向深入(Web/数据/AI)
- 了解相关技术栈
- 保持技术敏感度
- 培养解决问题的能力
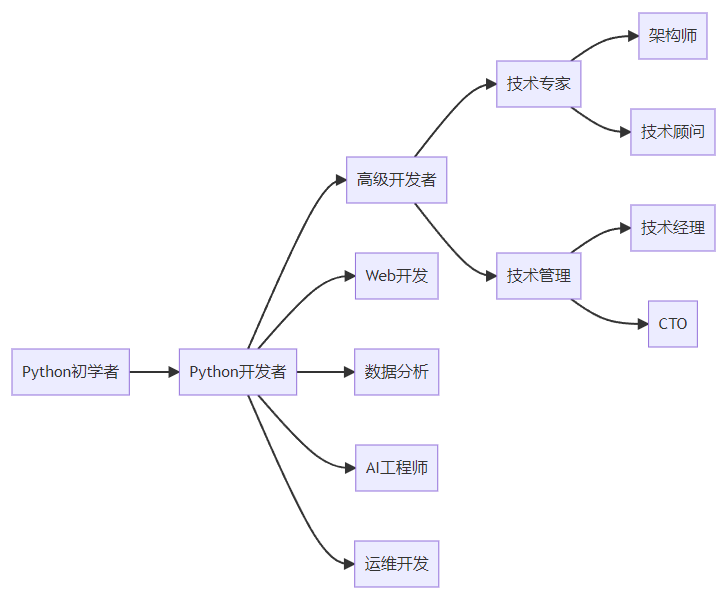
4. 职业发展路径
🚀 最后的话
Python学习是一个持续的过程,关键在于:
坚持实践 - 理论知识必须通过实践来巩固 保持好奇 - 对新技术保持敏感和兴趣 乐于分享 - 与他人交流能够加深理解 持续改进 - 不断优化代码质量和编程思维
记住,成为优秀的Python开发者不是一蹴而就的,需要时间、耐心和大量的练习。相信通过系统的学习和不断的实践,你一定能够掌握这门强大的编程语言!
📝 学习笔记模板
"""
Python学习日志
日期: ___________
学习内容: ___________
代码练习: ___________
遇到问题: ___________
解决方案: ___________
心得体会: ___________
明日计划: ___________
"""🔗 有用的链接
祝你在Python学习之路上取得成功!🐍✨
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号