进程优先级介绍,详解环境变量,详解进程地址空间


一、介绍进程优先级
1.什么是优先级
简单来说优先级是一种约定,进程都有优先级,优先级决定一个进程何时运行和接收多少 CPU 时间——优先级高的先做,优先级低的后做。
往简单说,优先级就是进程PCB中存储的一个数字,越小的优先级越高(跟成绩排名一样)
注意:

2.为什么会有优先级
系统中运行的进程可由用户决定多少,但硬件的数目却是电脑出厂后就决定的。
简单来说就是内存中的进程数目远多于硬件等资源的数目,导致的资源不足。所以引入了优先级这个概念以确保计算机的顺利运行
3.Linux中的优先级是怎么确定的

1)查看Linux中的优先级
ps -la指令可以查看目前所有用户的进程的信息,如优先级等。

2)计算优先级和更改优先级
优先级= PRI + NI
系统中的优先级是看pri决定的,pri越小越先被执行,但用户可以通过更改ni的值来改变进程的优先级。
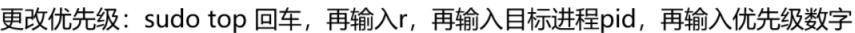
你可以输入任意大小的数字,但操作系统只允许ni的值位于[ -20,19],多出的部分舍弃。

所以Linux中进程的优先级共有40个等级:[ 60 ,99]
二、环境变量
1.什么是环境变量

具有全局属性,就是可以被子进程继承下去(有些类似于C中的局部变量与全局变量的关系)
每当用户登录时,操作系统便会默认初始化系统中的环境变量,环境变量本质上就是一串字符串。
2.环境变量有什么作用

如环境变量HOME,当用户登录上Linux后,系统便通过识别用户名以初始化HOME环境变量,进而导致不同身份的用户登录家目录不同:
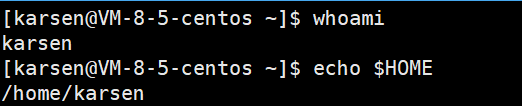
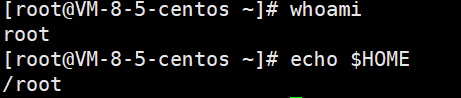
3.环境变量怎么做到的
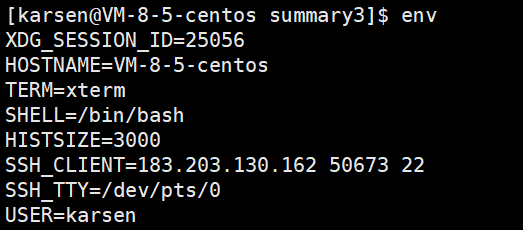
1)查看系统已有的环境变量
env指令:在屏幕上打印出系统已有的环境变量
节选的一些
2)以PATH具体认识环境变量
引入
通过file pwd等指令,再file 我们自己写的程序,发现都是x86_64可执行程序(是的,指令也就是写好的程序),可为什么我们的程序不能像系统指令一样执行,而是得加" ./ "呢?


①PATH环境变量的作用


②查看PATH中的存储的地址
echo $PATH

如果我们将自己写的程序的地址加入PATH后,是不是就可以像使用指令一样在任何目录都可以调用我们的程序?
注意:


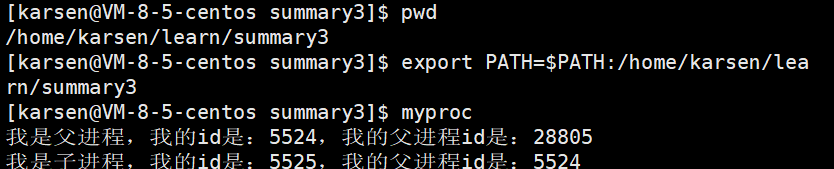
猜想是正确的!
此时再查看PATH中记录的地址发现有myproc程序的地址:

当我们重新登入Linux后,发现PATH的值又恢复初始状态:


3)介绍一些其他的环境变量

4)set

这里的全局变量就是C语言中的局部变量,环境变量就是全局变量,区别是这个全局变量只能在创建它的程序中使用,如下图中的hello,而环境变量可以继承给子进程。
①普通全局变量与环境变量的区别
在shell中定义一个普通全局变量hello=10,在set中可以看到hello。

但在环境变量中查找不到hello

通过export将hello变为全局变量后即可查找

②删除环境变量或者普通全局变量



关于环境变量相关的一些指令总结:
① echo: 显示某个环境变量值,如echo $PATH
② export: 设置一个新的环境变量,如export hello(自定义的)
③ env: 显示所有环境变量
④ unset: 清除环境变量
⑤ set: 显示本地定义的shell变量和环境变量

4.如何通过代码获取环境变量
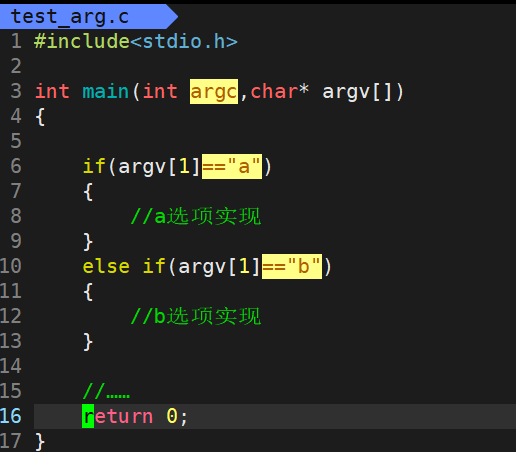
1)main函数的命令行参数
不知你是否曾在某些书本当中见过main函数是带参数的,如下:

现在让我们来详细了解这些参数
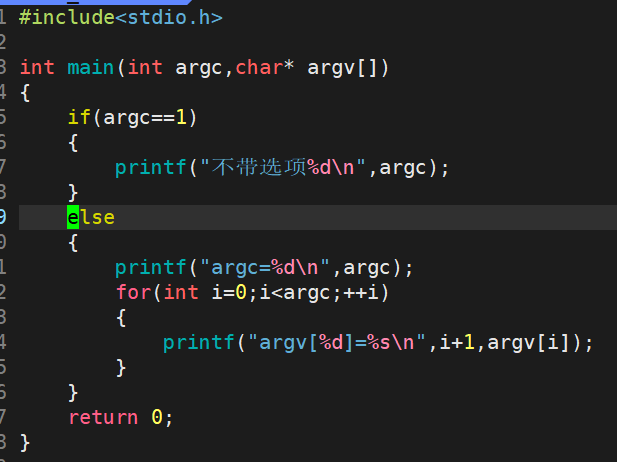
①int argc和 char *argv[ ]
int argc的作用是存储在调用该程序时的选项数目;
而char *argv存储的则是每一个额外选项。
比如我们常用的ls -al—>ls -a -l,在包括ls指令本身后argc=ls + a + l ==3,而char *argv[ ]则存储着这些选项。
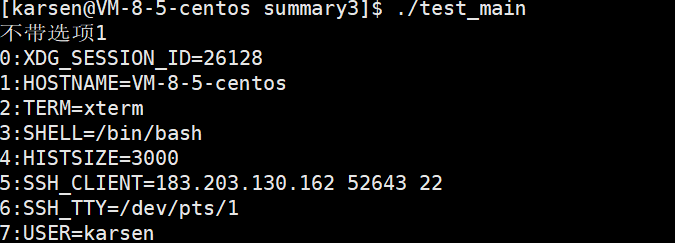
我们用自定义的test_main.c来观察argc和argv[ ]。
若gcc编译不通过,则按提示在gcc后添加-std=c99:

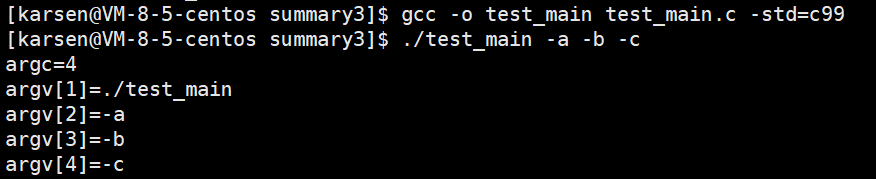
在调用test_main时我们附加了-a -b -c三个选项,如上图。可以看到被成功打印出。
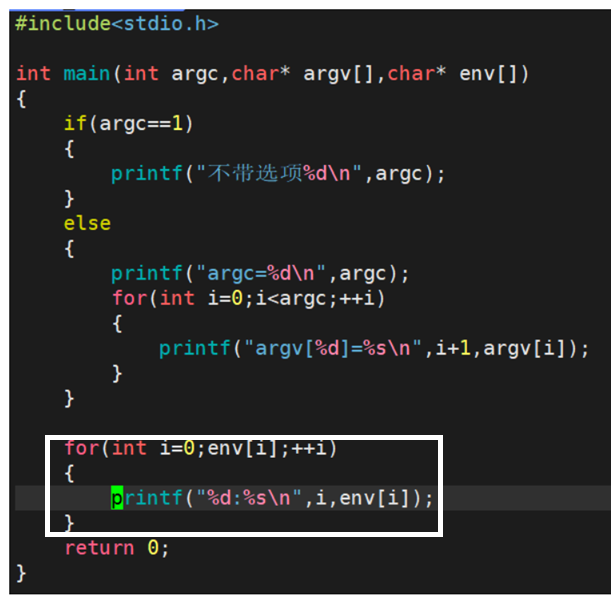
②char *env[ ]
在有了对argc和argv[ ]的理解后,再来理解env[ ],便容易的多。
首先要明确的是:每个程序在运行时都会收到操作系统给的一张环境表,环境表是一个字符指针数组,每个指针指向一个以’\0’结尾的环境字符串。而char * env[ ],便是那张环境表。
③main函数命令行参数对编程的另一种启发
由于环境变量可以被子进程继承,这为我们编写代码提供了另一种思路:在运行进程之前就将对应的选项输入,如我们在使用ls指令时输入的选项一样,ls -al。
比如:
你编写了个程序,其中有诸多功能选项,但是用户得先将程序运行后再输入选项才能实现想要的功能,如果将这些选项在运行之前就给出,使用户输入后就能直接运行,如ls -a -l等指令一样,或许在某些场景能提高用户使用效率。
如以下代码:
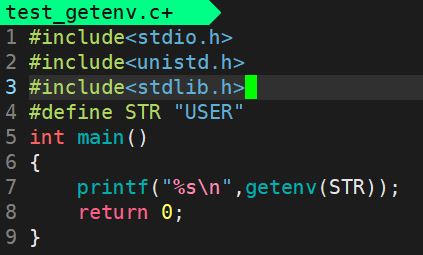
2)getenv接口获取
作用:在程序内通过代码获取环境变量。


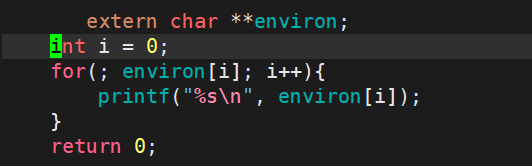
3)extern char ** environ
直接在代码中额外声明char ** environ环境变量表,依然可以打印出环境变量。
小结:
在程序中获取环境变量有三种方式
①getenv;
②char *env[ ];
③extern char ** environ;
5)一些奇怪的问题
①操作系统是如何得知你是否有某文件权限的?


②我们说非环境变量不能被子程序获取,那shell里定义的全局变量为什么能被echo读取并打印?

如上图中所示:
已知:myenv是个shell定义的普通全局变量,echo是一个指令(本质上也是一种程序),当在shell运行echo时本质创建了一个子进程,但按照环境变量的定义这应该是不被允许的。
echo能读取非环境变量的本质:

三、进程地址空间
1.引出问题
我们编写一段代码,定义一个全局变量glo_x=100,再通过fork调用生成一个子程序。
我们尝试在子进程中修改glo_x,而父进程什么都不做,两个再打印glo_x会有什么现象。
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<unistd.h>
4 int glo_x=100;
5 int main()
6 {
7 pid_t id=fork();
8 int cnt=1;
9 if(id<0)
10 {
11 printf("创建子进程失败\n");
12 exit(1);
13 }
14 else if(id>0)
15 {
16 //父进程
17 while(1)
18 {
19 printf("我是父进程,我的id是:%d,glo_x=%d,&glo_x=%p\n",getpid(),glo_x,&glo_x);
20 sleep(1);
21 }
22 }
23 else
24 {
25 //子进程
26 while(2)
27 {
28 printf("我是子进程,我的id是:%d,glo_x=%d,&glo_x=%p\n",getpid(),glo_x,&glo_x);
29 cnt++;
30 if(cnt==3)
31 {
32 glo_x=700;
33 printf("子进程已经修改了glo_x的值…\n");
34 }
35 sleep(2);
36 }
37 }
38 return 0;
39 }结果如图:
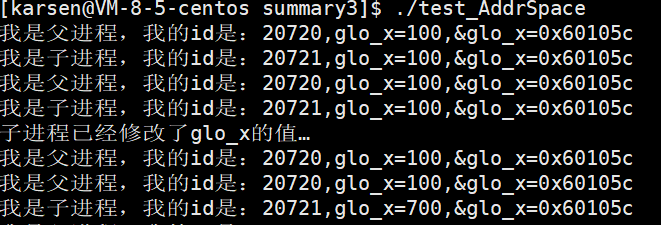
此时,同一个地址的glo_x变量居然有两个值!!
2.逻辑地址、虚拟地址、物理地址的概念
在学习C语言时,我们认为内存划分为这么几个区域:代码段、数据段、堆区、栈区,如下图所示
上面的理解是正确的但不完全正确,真正理解进程地址空间还需要理解:逻辑地址、虚拟地址、物理地址这三种地址之间的区别与联系。
1)逻辑地址
①逻辑地址是程序视角下的地址空间;
②编译器编译的时候是从0开始编址的;
③代码中的指针值就是就是逻辑地址;
④逻辑地址空间存在于进程当中,每个进程都有自己的逻辑地址空间。换言之,每个进程认为自己独享整个系统的资源。
2)虚拟地址
①虚拟地址是站在cpu的视角的地址空间
②经过分段机制转换后的地址,是分页机制的输入。
由于技术的进步,在现代操作系统中,逻辑地址几乎等同于虚拟地址。
3)物理地址
真实内存硬件上的地址,CPU 最终通过总线访问的地址,内存访问的最终目标。

所以不管是在编译器中调试看到的逻辑(虚拟)地址,还是物理地址,都是用32位二进制来描述这2^32个地址。
从程序到物理内存的地址转换分为两个阶段: 逻辑地址 → 虚拟地址 → 物理地址,由于现在的操作系统中逻辑地址几乎等同于虚拟地址,为方便理解,我们暂时认为是从虚拟地址→ 物理地址。
3.内核数据结构mm_struct
通过上面三种地址空间的描述,我们可以得出一个信息:就是进程都认为自己独占整个系统资源,并且编译器在编译时也是从地址0开始编译。但是内存中的进程不只一个,肯定不可能让一个进程独占,且物理地址只有一条,让所有进程都从0地址开始编址也显然不可能,并且各个进程中代码段需要多少内存,数据段需要多少内存,堆栈又各自需要多少内存又是不尽相同。
于是,操作系统为了方便管理,创建了另一种内核数据结构mm_struct。
操作系统管理的核心思路是:先整理,在管理。
先整理:mm_struct中的数据成员正是代码段、数据段、堆栈的起始地址与终止地址。
再管理:通过为每一个进程创建一个mm_struct对象,直接管理各个进程所需的内存。

所以,在代码中的malloc 或者 new其实就是mm_struct中的数据更改变动,本质上就是start 或者end的更改。
注意:

故下图其实描述的是进程的虚拟(逻辑)地址空间,也就是说进程地址空间本质上是一种数据结构,其中数据结构的各个成员决定了每个区域的划分。
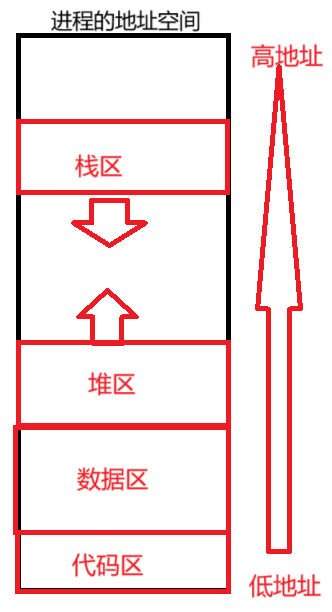
4.页表:虚拟地址到物理地址的映射
在已经知道虚拟地址的概念即如何通过mm_struct存储后,那么操作系统是如何通过虚拟地址精确找到物理地址的呢?

这里笔者画了个草图以帮助读者理解从虚拟地址——>物理地址的转换。
同样的从物理地址到虚拟地址也要经过页表的转换。
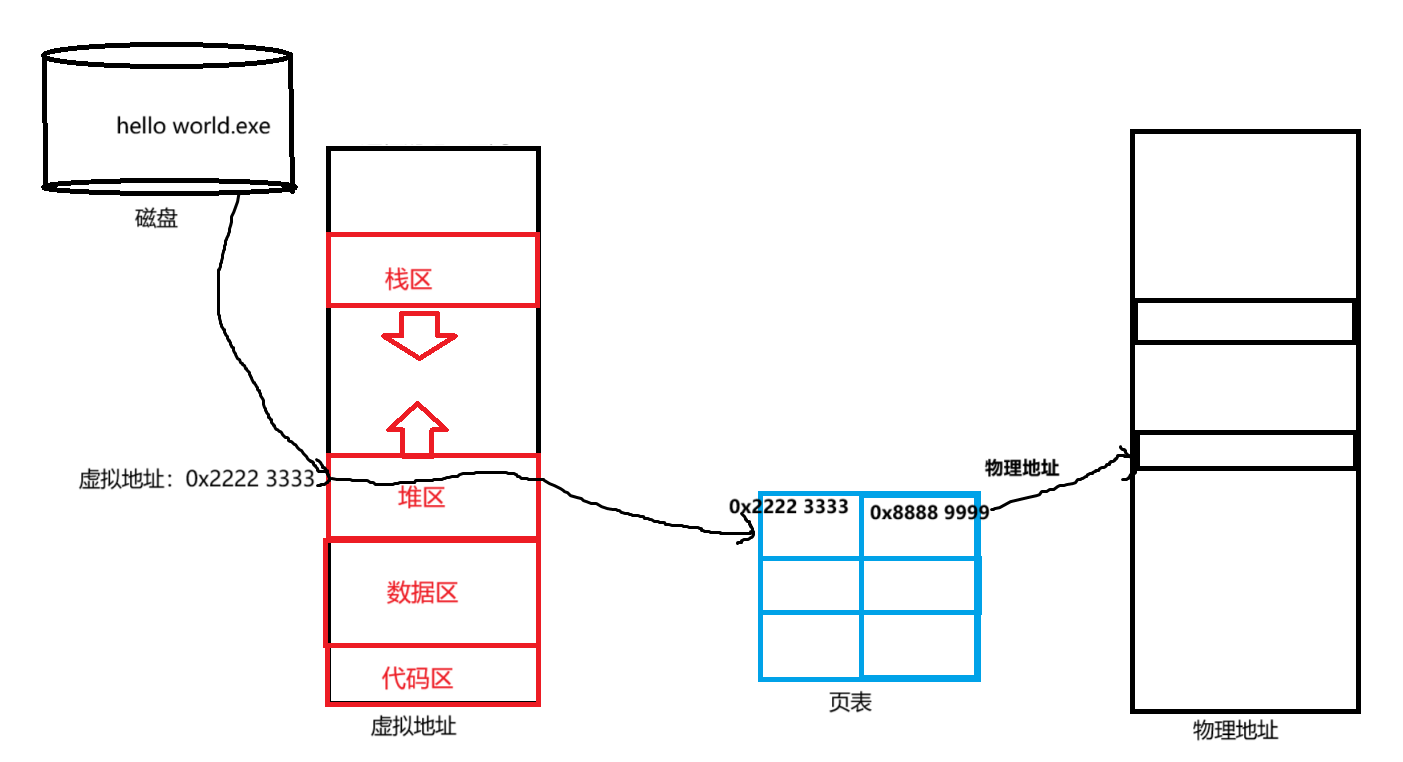
值得注意的是:

5.写时拷贝
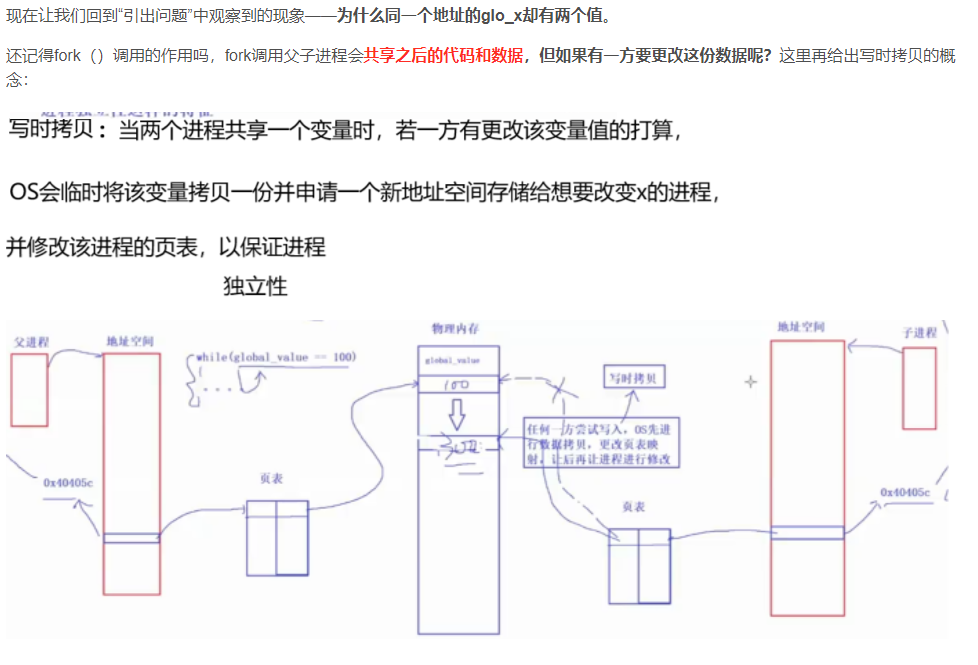
现在让我们回到“引出问题”中观察到的现象——为什么同一个地址的glo_x却有两个值。
还记得fork()调用的作用吗,fork调用父子进程会共享之后的代码和数据,但如果有一方要更改这份数据呢?这里再给出写时拷贝的概念:
6.再一次理解虚拟地址:从编译到执行
1)编译器从0地址开始编址逻辑(虚拟地址)地址,若是32位环境下则每一位地址由32位二进制表示。64位同理;
2)当编译好的程序加载到内存后又获得物理地址;

3)操作系统将进程的虚拟地址与物理地址填入页表中;
4)当调用该进程的执行代码时:
①cpu通过查看task_struct(PCB)中的mm_struc,得到虚拟地址,然后前往页表查询物理地址;
②得到物理地址后,再前往物理地址中寻找该进程的代码和数据;
③得到具体的可执行代码和数据后再带回cpu内计算。

7.进程的两套地址
也就是说,一个进程其实是有两套地址的:
①物理存在于内存中的代码和数据的地址;
②在程序内部相互跳转时(如函数调用函数)用的虚拟地址。
7.总结进程地址空间
1)进程地址空间是什么
进程地址空间 是指一个进程在运行时所能“看到”和使用的所有内存地址的集合。其核心内容就是虚拟地址。操作系统通过让每个进程都认为自己独占整个内存资源,实际物理内存由操作系统动态分配和管理。
2)为什么会存在逻辑地址、虚拟地址、物理地址三个地址而不是一步到位?
如果只存在一个地址,也就是让进程直接访问物理内存会有诸多隐患:
①防止进程越界非法操作(野指针),保证操作系统的安全;
——使用页表进行映射能有效拦截进程的非法请求
②防止恶意程序扫描内存而导致的数据泄露;
③减少内存碎片化,如果进程必须占用连续的物理内存,会是内存碎片化加剧:
比如:若物理内存剩余 1GB 但碎片化为多个 100MB 块,则无法运行需要 500MB 的程序。
整体是以空间换安全的设计思想。
3)虚拟地址是如何做到的
操作系统通过页表映射,将进程的虚拟地址与物理地址联系起来,以实现每个进程的虚拟地址空间。
四、一些问题
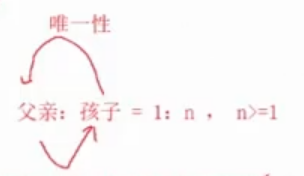
1.如何理解fork函数为父进程返回子进程id,给子进程返回0?
一个孩子只能有一个父亲或者母亲,而父母却可能有多个孩子。
同理,一个子进程只能有一个父进程,故仅通过getppid函数就能知道谁是父进程;但一个父进程可能有多个子进程,所以需要每个子进程的id来区分他们,所以要求创建完子进程后向父进程返回其id。
2.如何理解fork函数会有两个返回值?
函数返回值只能通过return返回,且一次只能返回一个值。
通过上述“进程地址空间”我们已知:fork调用的效果是创建一个子进程,并将父进程的task_struct(PCB)和代码数据等拷贝一份给子进程,并共享之后的代码。那么当父进程中的fork函数运行到return语句时,其核心语句已经运行完成了,此时子进程已经被创建出来甚至可能已经在cpu的运行队列中了。
由于父子进程共享之后的代码,故父子进程都会执行return语句,不过父进程返回的是子进程id,子进程返回的是0。
所以fork函数的两个返回值分别是两个进程的fork函数return结果。
3.如何理解在“进程地址空间”引言代码中的同一个id变量,怎么会使if和else if同时执行?
由“进程地址空间”已知,此时子进程已经创建完毕并准备运行。

总结
本文先介绍了进程的优先级,以及Linux中的优先级是如何确定的,之后介绍了什么是环境变量及其作用,最后介绍了什么是地址进程地址空间、mm_struct,以及为什么要使用虚拟地址。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-05-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号