spark 操作 hive
原创

1、操作内置hive
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, num: bigint ... 1 more field]
scala> df.createOrReplaceTempView("user")
scala> spark.sql("show tables").show
+---------+-----------+
|tableName|isTemporary|
+---------+-----------+
| | |
| user | true |
+---------+-----------+
scala> spark.sql("create table wuheqian(id int)")
res2: org.apache.spark.sql.DataFrame = []
#进行此操作之前需要在spark-local/data下创建id.txt(内容为一列1234)
scala> spark.sql("load data local inpath 'data/id.txt' into table wuheqian")
res3: org.apache.spark.sql.DataFrame = []
scala> spark.sql("select * from wuheqian").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+2、操作外置hive
2.1、配置外置hive
参考该文章:https://cloud.tencent.com/developer/article/2443534
2.2、引入外置hive
#如果想连接外部已经部署好的Hive,需要通过以下几个步骤:
1.Spark要接管Hive需要把hive-site.xml拷贝到conf/目录下
2.把Mysql的驱动copy到spark的jars/目录下
3.如果访问不到hdfs,则需要把core-site.xml和hdfs-site.xml拷贝到spark的conf/目录下
4.重启spark-shell
scala> :quit
#重启spark-shell
[root@node1 spark-local]# bin/spark-shell
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel).
22/10/13 00:05:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your
platform... using builtin-java classes where applicable
22/10/13 00:06:00 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port
4041.
22/10/13 00:06:00 WARN SparkContext: Use an existing SparkContext, some configuration may not
take effect.
Spark context Web UI available at http://192.168.234.129:4041
Spark context available as 'sc' (master = local[*], app id = local-1665633960126).
Spark session available as 'spark'.
Welcome to
__
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_79)
Type in expressions to have them evaluated.
Type :help for more information.
#展示外置hive的表
scala> spark.sql("show tables").show
+----------+-----------+
| tableName|isTemporary|
+----------+-----------+
|spark_test| false |
|wuheqian | false |
+----------+-----------+代码操作外置hive
- 先将hive-site.xml放到IDE的maven项目如下位置:
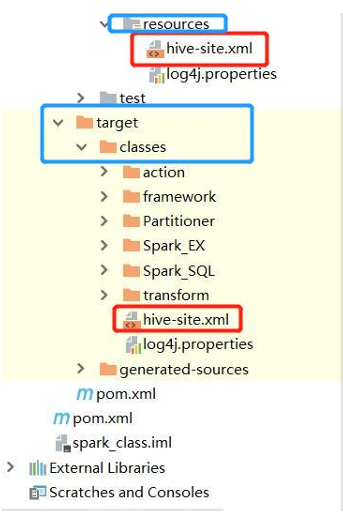
//idea操作
//在pom.xml文件添加如下依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency> //IDEA操作
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SparkSession, _}
object spark_sql_hive {
def main(args: Array[String]): Unit = {
//TODO 创建spark_sql的运行环境
val sparkconf = new SparkConf().setMaster("local[*]").setAppName("spark_sql")
val spark = SparkSession.builder().enableHiveSupport().config(sparkconf).getOrCreate()
import spark.implicits._
//TODO 执行逻辑
spark.sql("show tables").show
//TODO 关闭环境
spark.stop()
}
}
//运行结果
D:\bigdata\java\jdk.1.8.0_251\bin\java.exe......
+--------+----------+-----------+
|database| tableName|isTemporary|
+--------+----------+-----------+
| default|saprk_test| false |
+--------+----------+-----------+原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号