RAG入门之数据导入
原创

LangChain 是什么
LangChain 是一个用于构建基于大语言模型(LLM)应用的开源框架。它提供了一套工具和抽象,让开发者能够轻松构建复杂的AI应用。
LangChain 的核心功能
- 文档加载和处理:支持多种格式(PDF、文本、网页等)
- 文本分割:将长文档切分成小块
- 向量存储:文档向量化和相似性搜索
- 链式调用:组合多个AI操作
- Agent:智能代理,能够使用工具
- RAG(检索增强生成):结合外部知识库
主要竞争对手和替代方案
1. LlamaIndex(原名 GPT Index)
# LlamaIndex 示例
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)特点:
- 专注于数据索引和检索
- 更简单的API
- 更好的RAG性能
2. Haystack
# Haystack 示例
from haystack import Pipeline
from haystack.nodes import BM25Retriever, FARMReader
retriever = BM25Retriever(document_store=document_store)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")特点:
- 企业级搜索和问答
- 强大的NLP流水线
- 生产环境优化
3. Semantic Kernel(微软)
// Semantic Kernel 示例 (C#)
var kernel = new KernelBuilder()
.WithOpenAIChatCompletionService("gpt-3.5-turbo", apiKey)
.Build();特点:
- 微软开发
- 支持多种编程语言
- 与Azure集成良好
4. AutoGPT / GPT-Engineer
特点:
- 自主AI代理
- 自动化任务执行
- 代码生成专门化
5. Chroma
# Chroma 示例
import chromadb
client = chromadb.Client()
collection = client.create_collection("my_collection")特点:
- 专注向量数据库
- 简单易用
- 轻量级
各框架对比
框架 | 专长 | 优势 | 适用场景 |
|---|---|---|---|
LangChain | 全栈LLM应用 | 生态丰富、社区活跃 | 原型开发、复杂应用 |
LlamaIndex | 数据索引检索 | API简洁、RAG性能好 | 知识库搜索 |
Haystack | 企业搜索 | 生产级稳定性 | 大规模部署 |
Semantic Kernel | 多语言支持 | 微软生态集成 | .NET环境 |
Chroma | 向量存储 | 轻量级、易部署 | 简单向量搜索 |
选择建议
- 初学者/原型:LangChain(生态丰富,文档全面)
- 专注RAG:LlamaIndex(性能更好)
- 生产环境:Haystack(稳定性强)
- 微软技术栈:Semantic Kernel
- 简单向量搜索:Chroma
如何使用数据加载器读取简单文本?
from langchain_community.document_loaders import TextLoader
loader = TextLoader("/Users/shuyixiao/PycharmProjects/RAGPracticalCourse/my.text")
document = loader.load()
print(document)my.text文件内容
生成式AI应用工程师(高级)认证 | 阿里云博客专家 | Java应用开发职业技能等级认证 境是人非叶落处,焕景深处已向春~ 代码是我的文字,程序是我的诗篇,我不是程序员,我是诗人。大浪淘沙,去伪存真,破后而立,否极泰来。 真正的有所成,只能是慢慢来...输出结果
/Users/shuyixiao/PycharmProjects/RAGPracticalCourse/.venv/bin/python /Users/shuyixiao/PycharmProjects/RAGPracticalCourse/testLangChain.py
[Document(metadata={'source': '/Users/shuyixiao/PycharmProjects/RAGPracticalCourse/my.text'}, page_content='生成式AI应用工程师(高级)认证 | 阿里云博客专家 | Java应用开发职业技能等级认证 境是人非叶落处,焕景深处已向春~ 代码是我的文字,程序是我的诗篇,我不是程序员,我是诗人。大浪淘沙,去伪存真,破后而立,否极泰来。 真正的有所成,只能是慢慢来...')]
进程已结束,退出代码为 0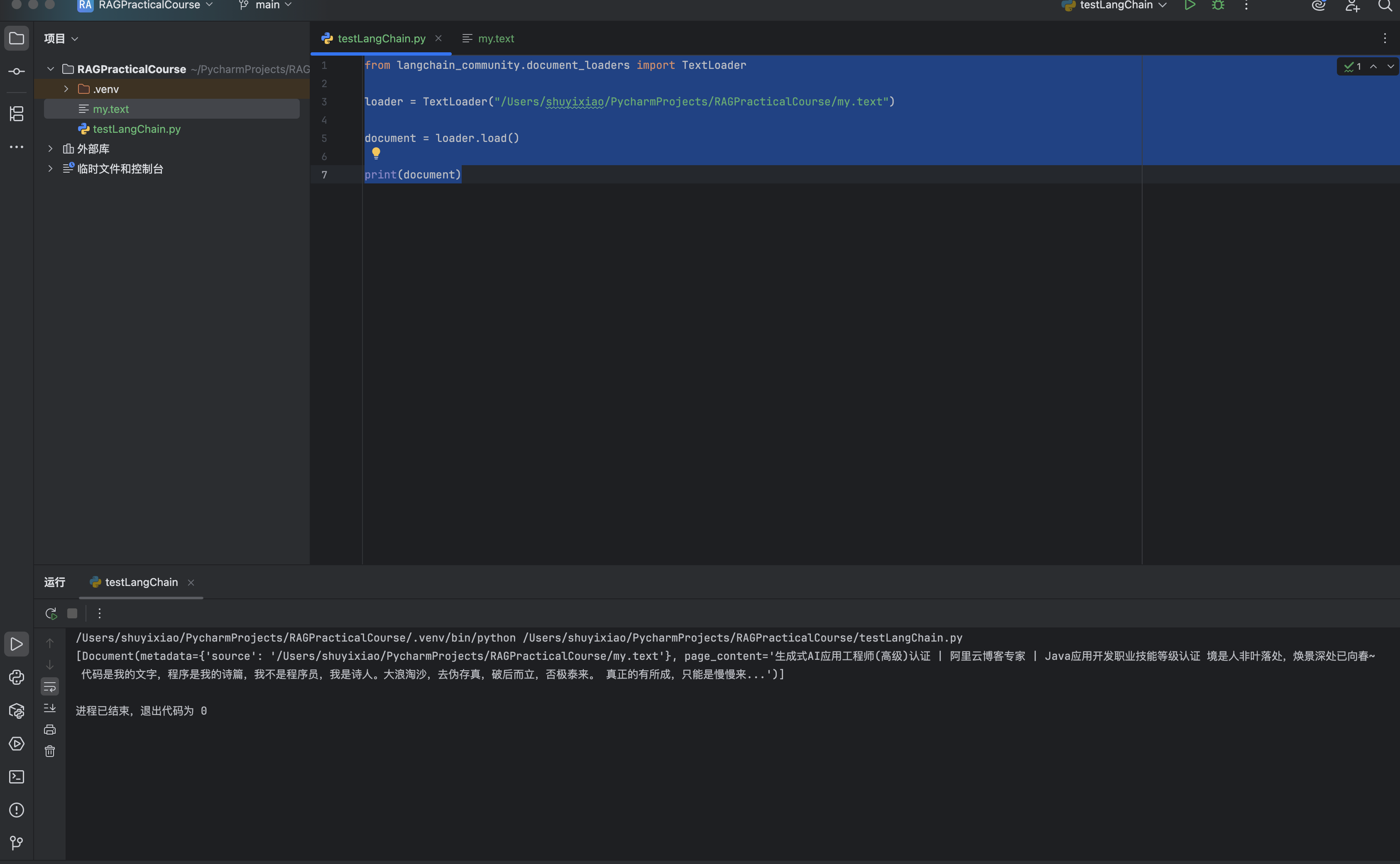
解释一下为什么是Document对象?
Document 是 LangChain 中的标准数据结构,用于统一处理各种文档格式。它包含两个主要部分:
page_content- 文档的实际内容metadata- 文档的元数据(如来源、创建时间等)
为什么使用 Document 对象?
# 统一的数据格式,便于后续处理
# 无论是文本、PDF、网页等,都统一为 Document 格原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号