FXCM福汇官网:LLMs serving 面临的一些挑战

FXCM福汇官网:LLMs serving 面临的一些挑战

用户9550247
发布于 2025-05-29 12:17:29
发布于 2025-05-29 12:17:29
如果您正在开发 AI 解决方案,并托管基于大语言模型(LLMs)的基础模型,那么您就应该关注模型服务的成本。然而,资金并非唯一的考量因素。请相信,如果无法解决模型性能的难题,即便预算充足,LLMs serving 的实际效果仍会大打折扣。本文将探讨如何将 LLM 的推理过程从「烧钱的无底洞」转变为「高性能的生产力引擎」。

FXCM福汇官网:fx-aisa.com
01 LLMs serving 面临的一些挑战
LLMs 非常强大,但它们的特性使其难以高效服务。LLM 的推理过程包含两个阶段:
1) 预填充阶段:当你输入提示词(上下文、对话历史、问题等)时,模型会一次性处理所有 token。
2) 解码阶段:在初始的提示词后,模型逐 token 生成内容,每个新 token 依赖于之前生成的 token。
举一个易懂的类比: 预填充阶段如同下棋时摆棋盘(耗时较长),而解码阶段则像摆好棋后逐步下棋(每一步都很快)。
然而,LLMs serving(译者注:将训练好的大语言模型部署到实际应用中,以低延迟、高吞吐、资源高效的方式处理用户请求的技术过程。) 并非轻而易举,必须考虑以下问题:
Sparsity
在神经网络(尤其是 FFN 模块)中,大量神经元的激活值为零。跳过这些零激活值的神经元、仅计算非零元素可以大大节省运算时间。
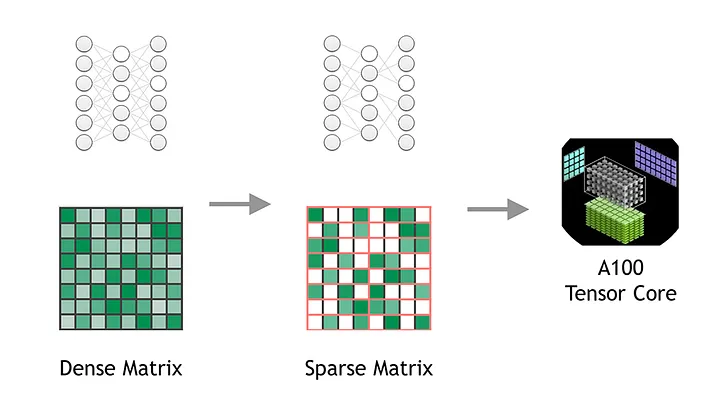
LLM 中大量神经元的激活值为零,导致矩阵运算中存在大量零值。图片来源[1]
内存带宽限制与内存瓶颈
在 GPU 上传输数据往往超过数据计算的耗时。此外,大型模型(例如传闻参数量达万亿的 ChatGPT)无法单卡装载。
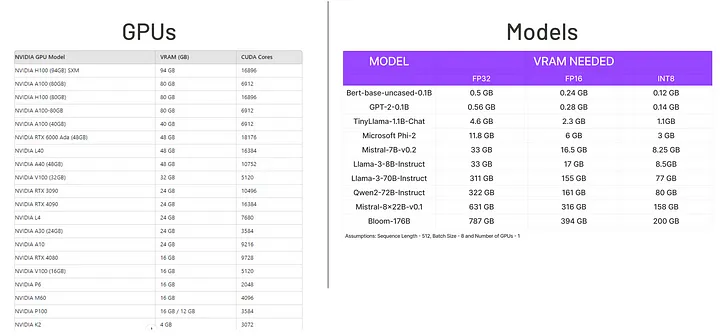
将当前最 先进 LLM 的内存需求,与 GPU 的显存容量进行对比。图片来源:ChatGPT
低效调度——先到先得
LLM 通常需要同时处理多个请求。这会导致短请求(例如询问天气、时间或简短的回答)被迫等待长请求完成。那么,平均响应时间几乎完全由等待时间主导,而非实际计算时间。

你更快,但必须等待之前的请求先处理完。图片来源:ChatGPT
Sequential Decoding(按顺序进行解码)
生成 token 时无法轻松实现并行处理。每次前向传播只能产生一个 token(或一个小 batch)。当我们向 ChatGPT 请求长回复时,输出内容往往是逐词生成的。这就是为什么“流式输出”(streaming output)的用户体验并不比等待完整答案一次性输出更差。
逐步进行解码。图片来源:ChatGPT
KV Cache 增长
注意力机制需对整个序列的所有文本进行计算,这是 LLM 的推理过程中最核心且最耗时的操作。有趣的是,每当序列中生成新 token 时,系统会对过去的 token 重复大量相同的计算。键值缓存(KV Cache)技术通过存储前几步的关键信息来加速此过程(使用 KV Cache 可使 T4 GPU 上的 GPT2 推理速度提升 5 倍)。下图展示了使用缓存与不使用的区别,但使用缓存也会额外占用内存。
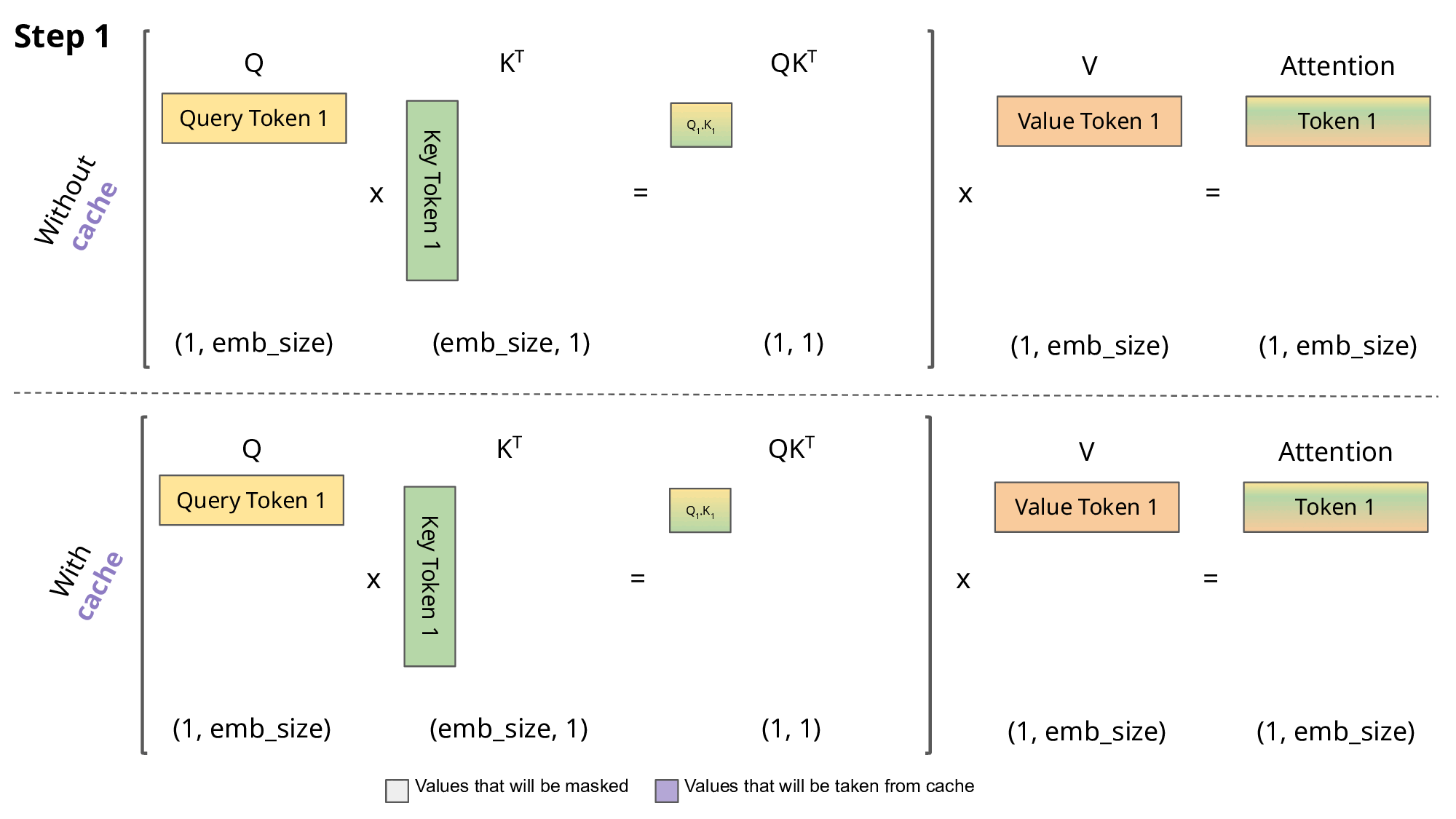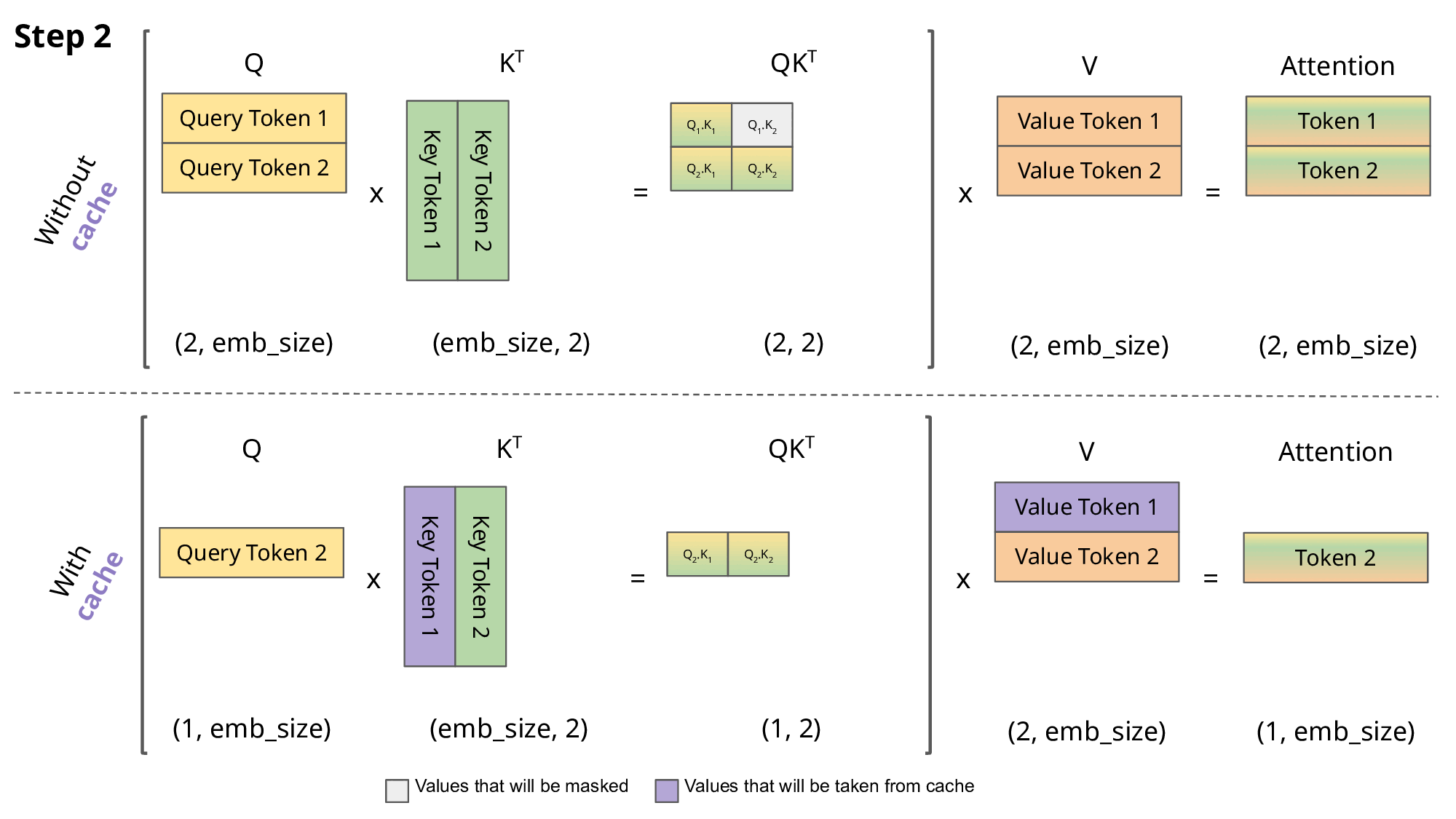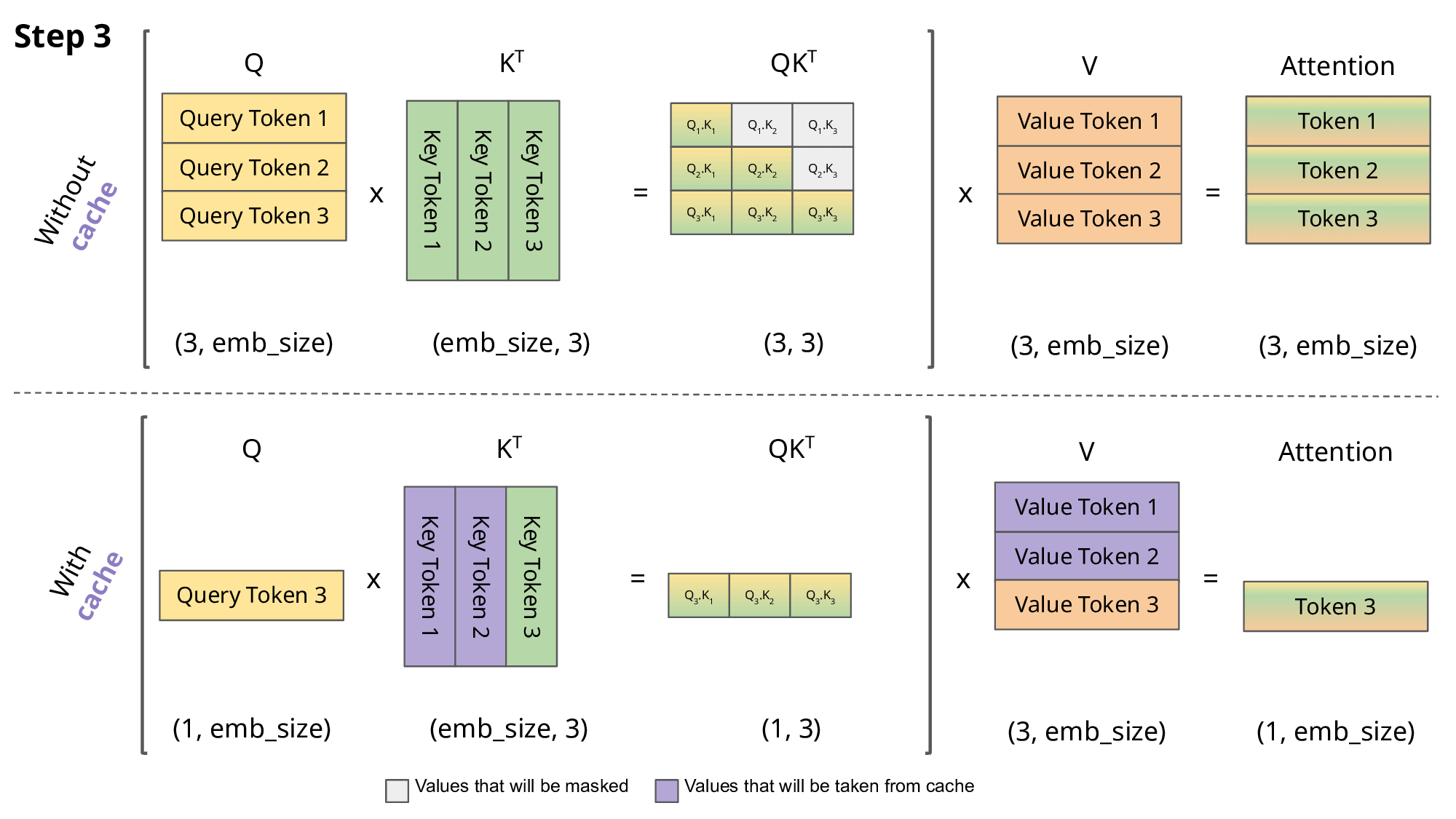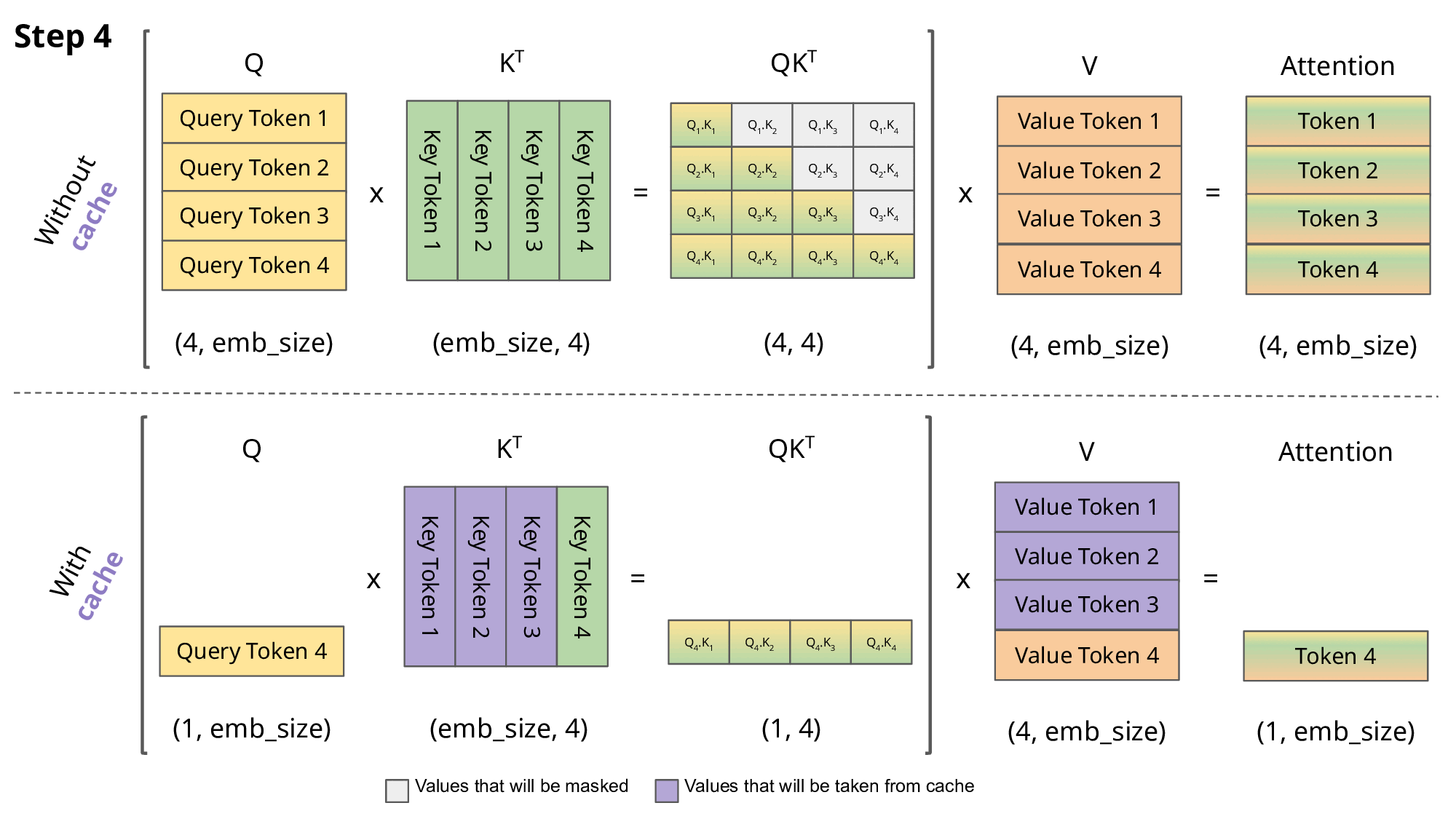
解码序列 [token 1, token 2, token 3, token 4] 时的 KV Cache 操作步骤。图片来源[2]
实验表明,KV(Key-Value)缓存的使用率在 20.4% 到 38.2% 之间。我用 Qwen-VL 2.0 模型对约 1 万张图片生成简短描述(要求回答少于20字),发现速度比未使用 KV 缓存的版本快 20%。
这些特性看似棘手,但通过巧妙的工程化手段,反而能转化为优势。
02 主题 1:巧妙的 KV 缓存管理
Page attention
KV 缓存会占用大量内存。 上下文越长,KV 缓存占用的内存越大。 例如,若某 LLM 的输入长度为 2048 个 token,则需预留 2048 个词槽(slots)。下图说明了我提到的情况。

在图中,2048 个词槽被一个包含 7 个单词的提示词(“four, score, and, seven, years, ago, our”)占用了,后续生成的 4 个单词(“fathers, brought, forth, ”)占用了第 8-11 个词槽。这意味着仍有 2038 个词槽被保留,但从未被使用过,这就产生了内存的内部碎片(internal fragmentation)。
每个推理步骤都会生成键值对(KV pairs),在使用注意力机制时必须缓存这些数据。KV 缓存通常以连续的块(chunks)或页(pages)的形式分配在内存中。当序列生成完成并释放内存页后,已释放的页可能不再连续。后续序列所需的内存大小可能无法恰好匹配现有空闲块,导致内存中散布小型的空闲块——即外部碎片(external fragmentation)。
受操作系统的内存管理启发,Page Attention 机制也将数据组织为逻辑内存块(logical memory block),并通过页表(page table)进行监控,再将合适的页(page)映射到物理内存中。具体实现如下:
1) Fixed-size Blocks(固定大小的内存块) :PagedAttention 分配固定大小且相对较小的内存块(称为“页(pages)”)来存储 KV 缓存。
2) Shared Blocks(共享内存块) :这些固定大小的内存块可在不同请求间共享。
3) On-demand Allocation(按需进行分配) :随着生成过程逐步分配内存块,无需根据最大序列长度的估算预先分配。
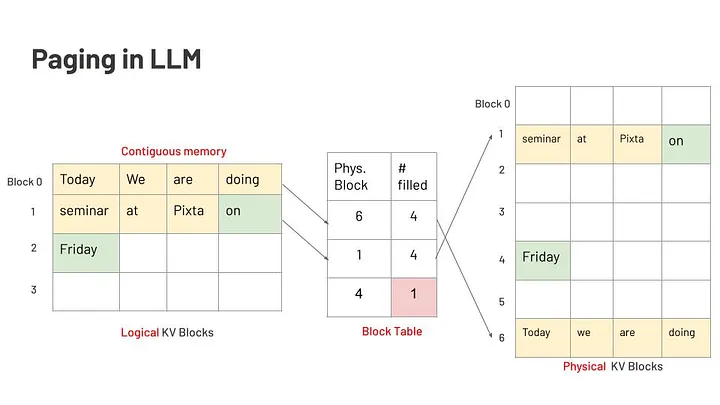
LLM 中的分页机制示意图。Image by the author
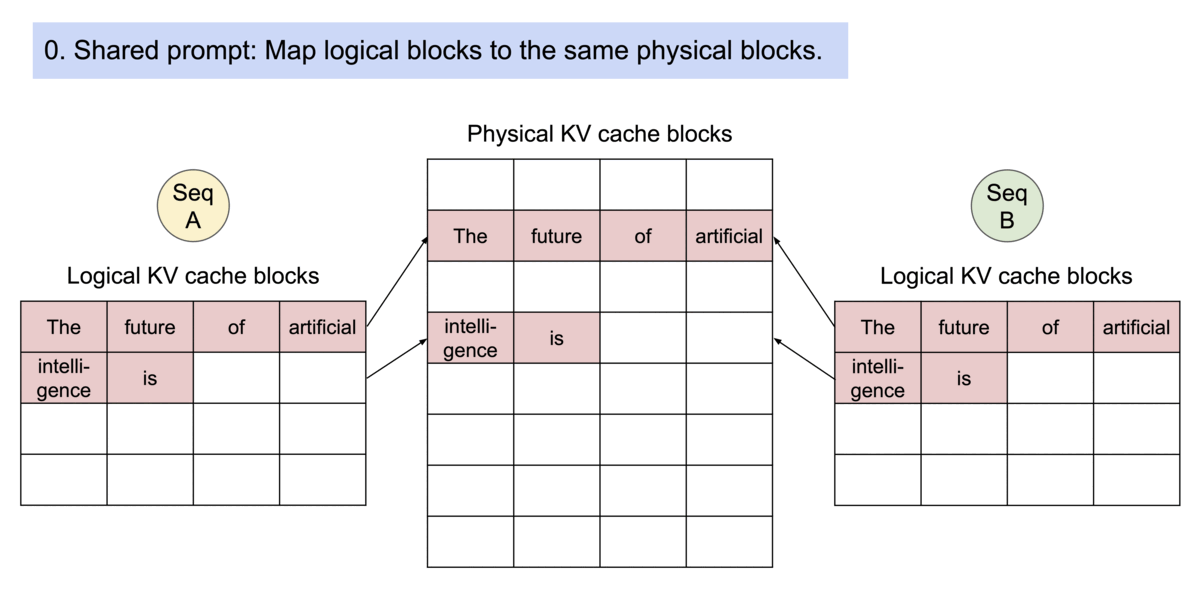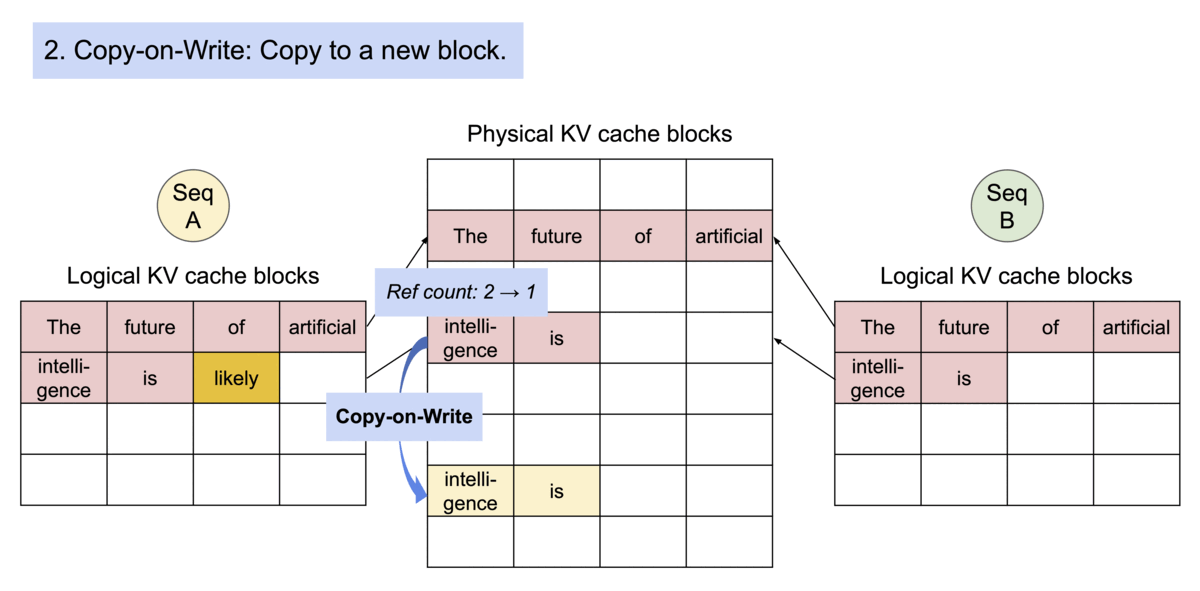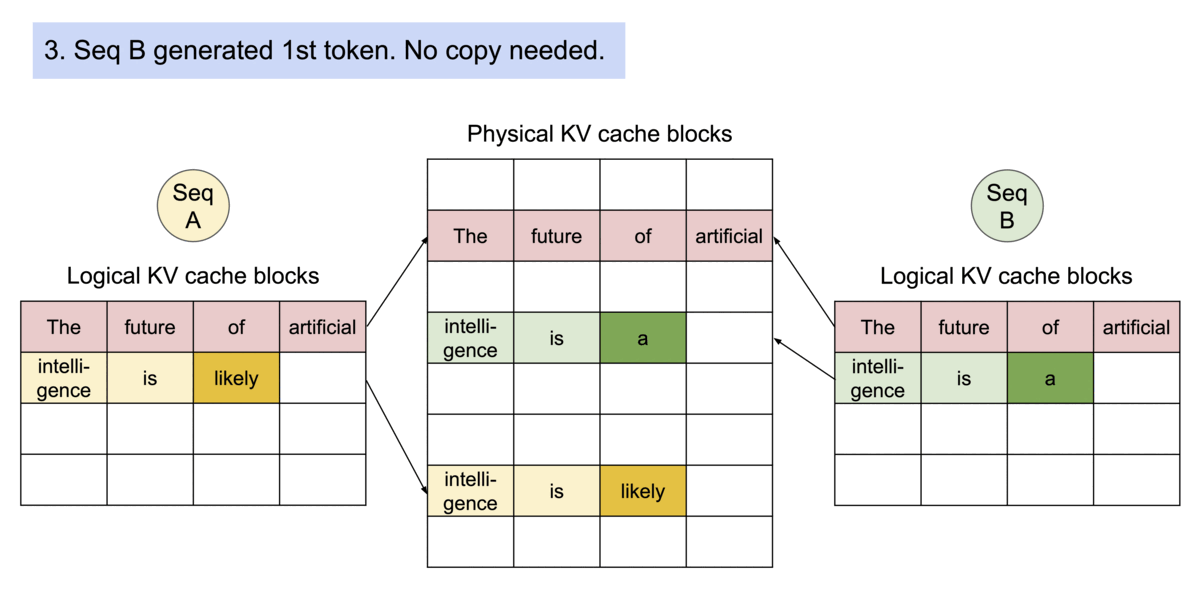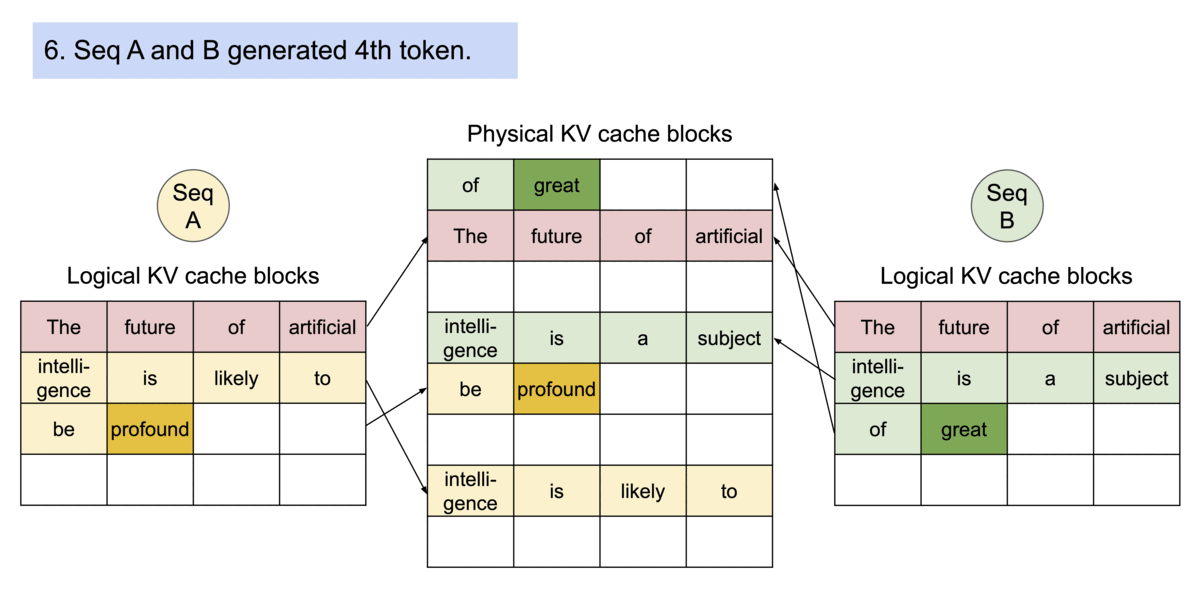
支持多请求间共享内存块的 LLM 分页机制示意图。Image by the author
Raddix tree KV cache
在计算机科学中,基数树(radix tree,亦称 radix trie、compact prefix tree 或 compressed trie)是一种优化了空间效率的字典树(前缀树),其将每个唯一的子节点与其父节点合并。
Raddix tree KV cache 是一种支持跨不同推理请求高效复用键值(KV)缓存的技术,尤其适用于多个请求共享共同前缀的场景。 通过将 KV 缓存组织为 Raddix 树结构,可高效检索缓存数据并在请求间共享。在下面的例子中,三个请求共享相同的前缀 "ABC"(存储于父节点中),每个请求中的最后一个单词则分别存储在三个叶子节点。需注意:树结构的运行时间复杂度为 O(nlogn),远低于注意力计算的 O(n²)。
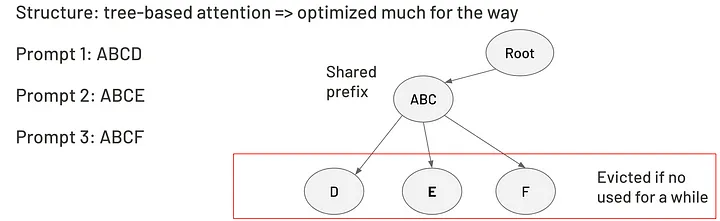
Raddix tree KV cache 示例
Compressed attention
多头注意力机制(Multi-head Attention)[3]是 Transformer 模型(LLMs 的基石)的核心机制。每个注意力头从不同视角分析文本:其中一个注意力头关注主谓关系,另一个注意力头解析词汇特征,第三个注意力头分析句子结构。这种多头机制虽增强了模型的理解能力,但也导致每个注意力头需要独立的 KV 对。在实时文本处理或长序列场景中,这些独立的 Key 和 Value 会占用大量内存。
分组查询注意力机制(Group Query Attention, GQA)允许多个查询(queries)共享同一组 Key 和 Value,从而减少所需 KV 对数量。多查询注意力机制(Multi Query Attention, MQA) 则更为激进,仅用一组 KV 对服务所有查询(queries)。
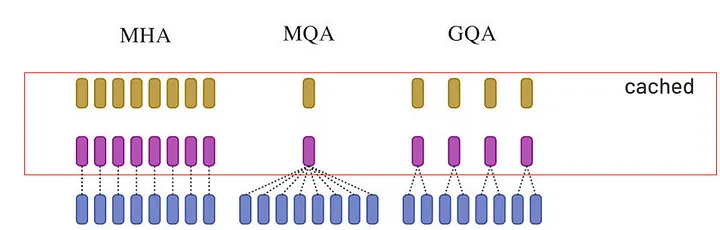
多头注意力、多查询注意力、分组查询注意力对比图
中国 AI 初创公司深度求索(DeepSeek)今年初发布了其 chatbot。该产品以高效、开源著称,人们传言他们的成功源于对 ChatGPT 生成数据的分析工作。然而,阅读了他们的技术报告后,我发现其技术突破不仅仅局限于数据提取操作。DeepSeek 提出的 Flash Multi Latent Attention(Flash MLA) 通过低秩压缩将 Key 和 Value 向下投影到更小维度的 latent vector 中,大幅减小了缓存体积。计算注意力时再将 latent vector 向上投影,且上投影矩阵权重与查询矩阵权重"折叠"融合,进一步加速了注意力的计算。
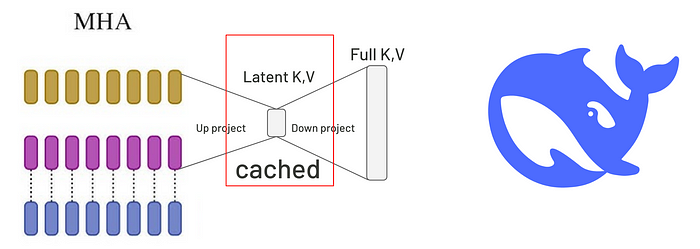
多头潜在注意力机制(MLA)示意图。Image by the author
03 主题 2:Query-sparsity attention
QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference
从 MIT 研究人员撰写的论文《QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference》[4]中,我们得知 Transformer 模型在推理过程中(尤其是注意力计算环节)常存在高稀疏性「译者注:high sparsity,大部分神经元或注意力权重在计算过程中未被激活(值为零或接近零)」。这意味着大模型中并非全部的神经节点被激活。通过将高稀疏性(high sparsity)的特性应用于剪枝机制(pruning mechanism),我们能够发现一种高效运行大模型的方法。下图展示了 Transformer 模型各层的稀疏性统计数据。遗憾的是,第 3 层之后的模型层通常非常稀疏。极端情况下,某些模型层(如第 10 层)甚至达到了 100% 稀疏,这种现象等同于在运行大语言模型时多次乘以 0,从而产生零值输出。
出现这种现象的原因很简单:并非每个单词都对当前上下文有贡献。
例如,给定提示词:"A is B. C is D. A is",模型应生成 "B"。这意味着只需要最关键的 token,而这很大程度上取决于查询(queries)。因此该技术被命名为查询感知的稀疏性算法(query-aware sparsity)。
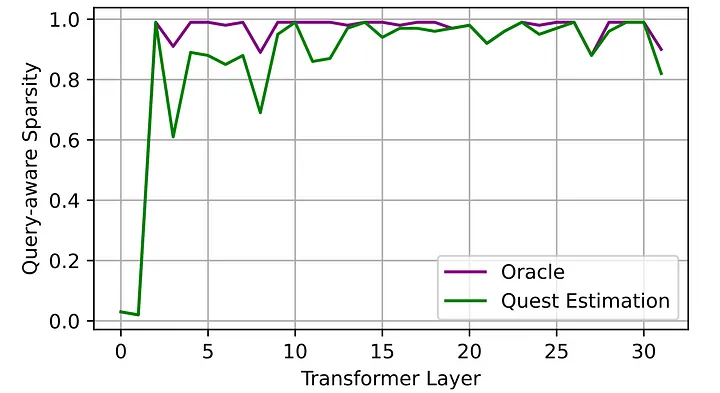
Transformer 模型推理中的稀疏性估算。图片来源[5]
了解这一特性后,QUEST 的核心策略就是定位对注意力计算最关键的数据块。QUEST 将找出前 K 个数据块。其算法流程直观清晰(见下图):
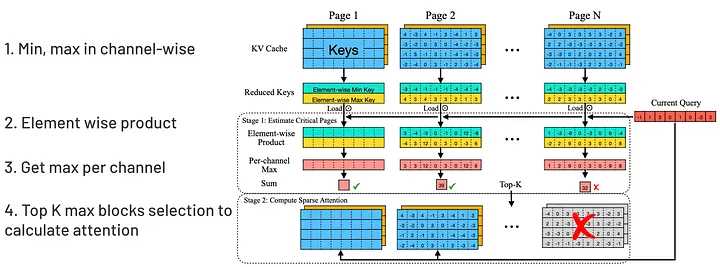
QUEST 获取 top K 个关键数据块进行注意力计算的流程
首先,对于每个数据块,QUEST 会找出最小和最大键值(minimum and maximum keys)及其通道尺度上的数值(channel-wise values)。接着,query 会逐个元素地生成最大和最小键值。这种方法能够大大减少所需的计算量 —— 即使 query 的符号(sign)变化,后续的乘积运算通常仍能得到最大值:当 query 符号为负时,乘以最小值必然得到最大输出值,反之亦然。在获取每个数据块的最大值后,QUEST 仅筛选出与 query 最相关的 K 个关键 KV 块。通过这一 流程,计算量得以大幅降低。
最后一个关键问题是选择恰当的 K 值,以避免模型性能下降。K 是一个需要通过实验才能确定的超参数(hyperparameter)。在论文中,作者建议选择 K=4096,可使模型性能保持在接近 100% 的水平。
以下是 K=4096 时的数据:
- PG19(一种教科书数据集)上的准确率 ≈ 完全达到了全局注意力(Full Attention)的基准准确率
- passkey retrieval 数据集上准确率 ≈ 100%
- LongBench 任务上的准确率 ≈ 在多数数据集上等效于全缓存(full cache)
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号