脚本分享—根据序列ID从fasta文件提取特定的序列


hello,hello!小伙伴们大家好,我是小编豆豆,今天小编继续来给小伙伴们分享免费好用的脚本。之前有公司将小编以前开发拿来贩卖,为了杜绝万恶的资本家
薅小伙伴羊毛,小伙伴们现在只需关注公众号,后台回复关键字即可免费获取该脚本,不需要任何费用。等这段时间忙完,小编会将这些脚本和示例数据上传到GitHub上,持续关注公众号,获取GitHub网址。
脚本简介:
本脚本旨在根据指定ID从FASTA文件中提取对应的序列,并输出为新的FASTA格式。是一个常用的序列筛选工具,适用于各种生物信息学数据处理场景
主要用途:
- 快速从FASTA文件中提取多个特定ID的序列;
- 使用
-i参数直接输入多个ID; - 或使用
-l参数指定一个ID列表文件。
- 使用
- 支持FASTA压缩格式(.gz)自动识别,无需手动解压;
- 可选输出到文件(使用
-o),否则默认打印到终端,也可以使用>重定向到文件中; - 支持是否保留原FASTA注释(description),用于记录更详细的序列信息。
应用场景:
- 从基因组或宏基因组拼装结果中提取特定contig或scoffold;
- 根据功能注释或聚类结果筛选目标ORF序列;
- 准备用于BLAST比对或结构预测的目标蛋白序列;
- 批量提取候选基因用于二次注释或序列比对。
安装biopython模块:
# 使用pip安装
pip install biopython
# 使用conda安装
conda install -c bioconda biopython查看脚本帮助文档:

脚本使用方法:
1)fasta文件
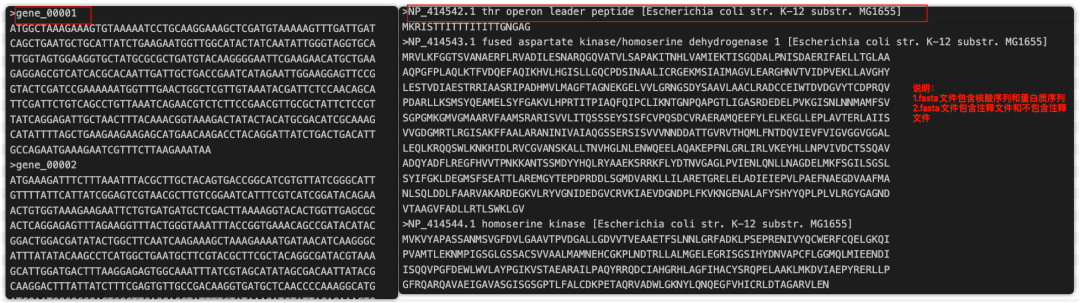
2)list文件
实战演习:
# 如果提取的序列较少,可以使用-i参数
python Extract_fasta_by_id.py -a SMA684v2_nucleotide.ffn -i gene_00001 gene_00004 gene_00006
# 如果提取的序列较多,可以将待提取的ID存入文件中,每一行是一个序列id
python Extract_fasta_by_id.py -a ASM584v2_protein.faa -l ASM584v2_list.tsv
# 脚本默认只提取序列和序列ID,不包含序列后的注释信息,可以使用
python Extract_fasta_by_id.py -a ASM584v2_protein.faa -l ASM584v2_list.tsv -description
# 脚本默认将提取结果输出到屏幕上,可以使用-o参数或者>重定向到文件
python Extract_fasta_by_id.py -a SMA684v2_nucleotide.ffn -i gene_00001 gene_00004 gene_00006 -o output_result.fasta
python Extract_fasta_by_id.py -a SMA684v2_nucleotide.ffn -i gene_00001 gene_00004 gene_00006 > output_result.fasta
# 脚本支撑gizp压缩文件,无需解压,直接提取
python Extract_fasta_by_id.py -a ASM584v2_protein.faa.gz -l ASM584v2_list.tsv
# 如果提供的序列ID fasta文件中没有,脚本会给出警告,方便进行结果核对
python Extract_fasta_by_id.py -a SMA684v2_nucleotide.ffn -i gene_00001 gene_00004 gene_0000X结果展示:

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号