2025 年 4 月 Apache Hudi 社区新闻

2025 年 4 月 Apache Hudi 社区新闻

ApacheHudi
发布于 2025-05-09 12:13:38
发布于 2025-05-09 12:13:38

Hudi Banner
Hudi Banner
欢迎阅读由 Onehouse.ai[1] 为您带来的2025年4月版Hudi通讯!本月,我们将为您带来另一轮令人兴奋的社区更新、技术深度探讨以及展示Apache Hudi如何推动现代数据湖仓架构边界的真实案例。
参加由Onehouse、Confluent、Databricks和DBT Labs于2025年5月21日主办的OpenXData[2] - 今年面向数据从业者的顶级开放数据架构教育活动。

OpenXData
OpenXData
社区博客/社交媒体
📙博客/视频
从沼泽到溪流:Apache Hudi如何改变现代数据湖[3] - Everton Gomede

数据湖转型图
数据湖转型图
在这篇文章中,Everton Gomede讨论了如何利用Apache Hudi解决传统数据湖的挑战,如数据质量问题、更新复杂性和性能下降。他强调了Hudi如何通过写时复制(Copy-on-Write)和合并读取(Merge-on-Read)存储、增量数据处理以及Spark生态系统内的事务能力等功能提供解决方案。
在Apache Hudi Lakehouse平台中引入二级索引[4] - Dipankar Mazumdar, Aditya Goenka

二级索引架构
二级索引架构
这篇博客介绍了Apache Hudi 1.0中的二级索引,实现了对非主键列的高效查询。通过维护二级键与记录位置之间的映射,Hudi减少了数据扫描并加速了查询性能。目前可用于Apache Spark,计划在未来版本中支持Flink、Presto和Trino。
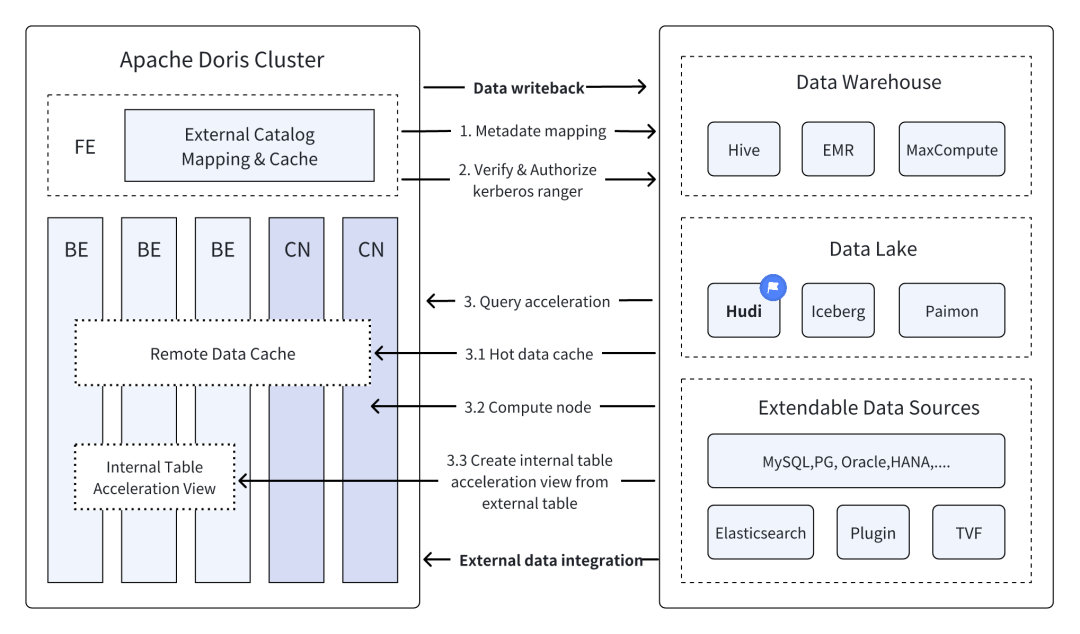
集成Apache Doris和Hudi进行数据查询和迁移[5] - Li YY
Doris和Hudi集成
Doris和Hudi集成
这篇博客探讨了如何集成Apache Doris和Apache Hudi,以实现大数据环境中的高效联邦查询、实时分析和无缝数据迁移。通过使用Doris的高性能查询引擎和Hudi的实时数据管理能力,组织可以实现灵活且经济高效的数据分析解决方案。
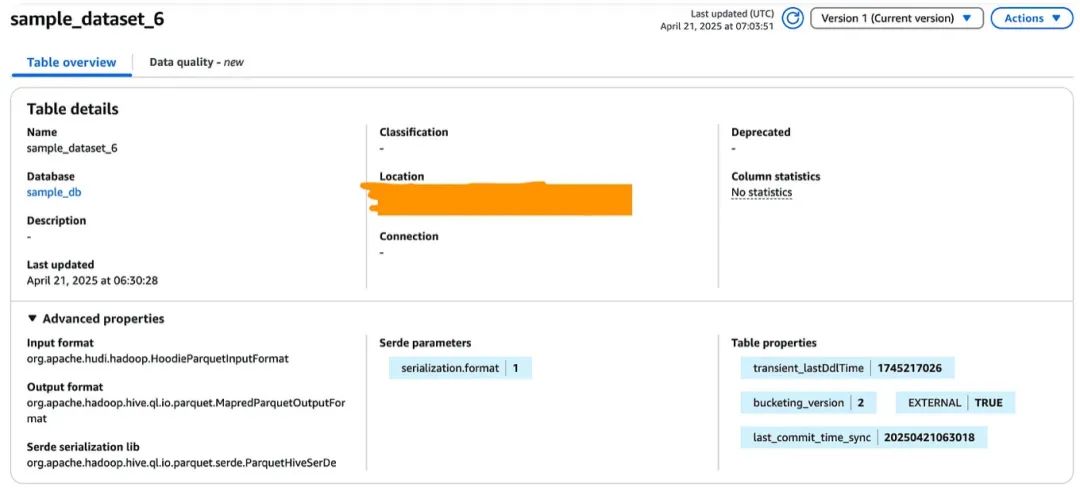
如何在AWS Glue中读取较旧版本的Hudi表[6] - Sagar Lakshmipathy
AWS Glue与Hudi
AWS Glue与Hudi
Sagar Lakshmipathy概述了如何在默认使用较新Hudi版本(例如v0.12.x)的AWS Glue环境中读取较旧版本的Apache Hudi表(例如v0.8.x)。通过在Hadoop设置中配置HoodieROTablePathFilter,用户可以确保兼容性并成功使用AWS Glue作业或笔记本查询旧版Hudi表。
📱社交媒体
现代数据架构:将数据库迁移到AWS上的可扩展数据湖仓[7]
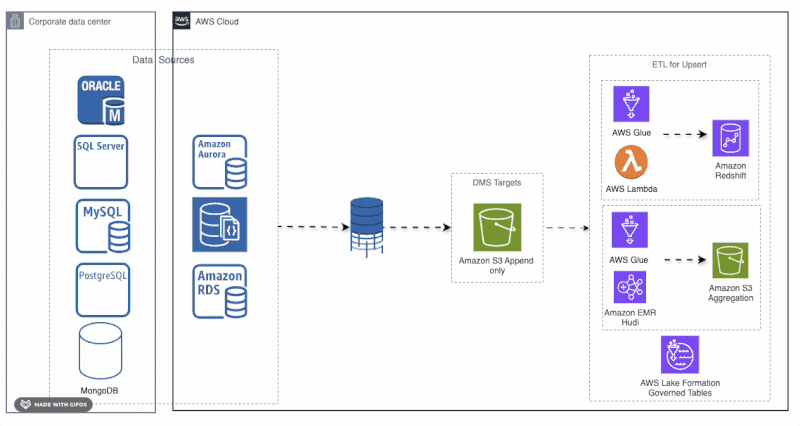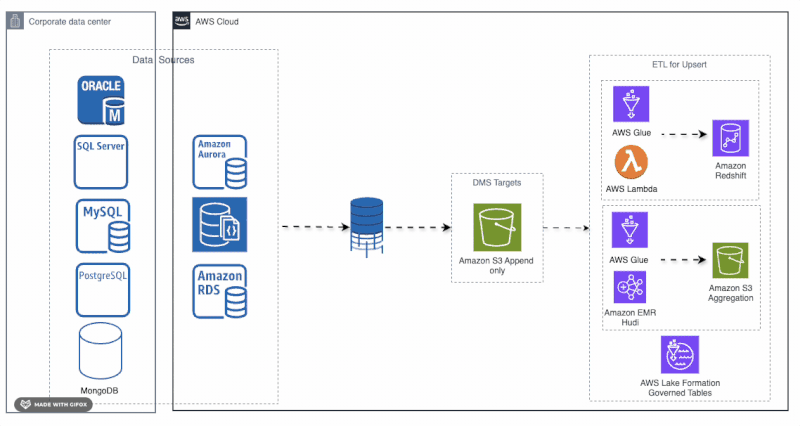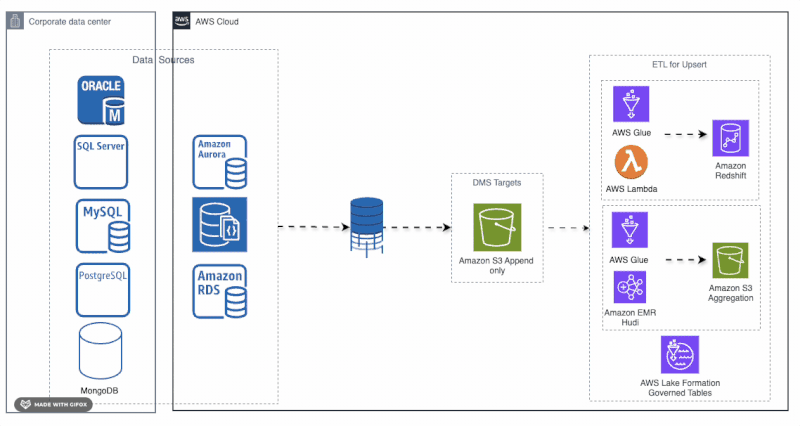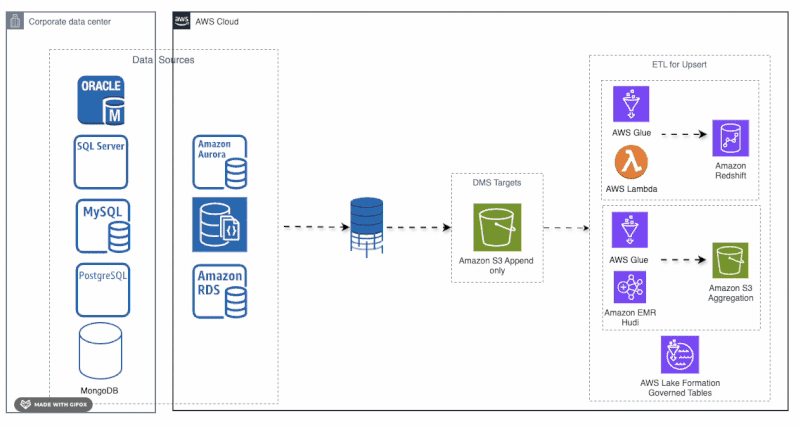
AWS数据迁移
AWS数据迁移
在这篇文章中,Roman展示了如何将传统数据库现代化为可扩展的基于AWS的数据湖仓。他详细介绍了使用AWS DMS、Glue、Lambda和带有Apache Hudi的EMR的管道,以启用增量更新、实时洞察和PB级分析——为AI、BI和治理数据湖仓用例解锁数据。
Apache Hudi Streamer[8]
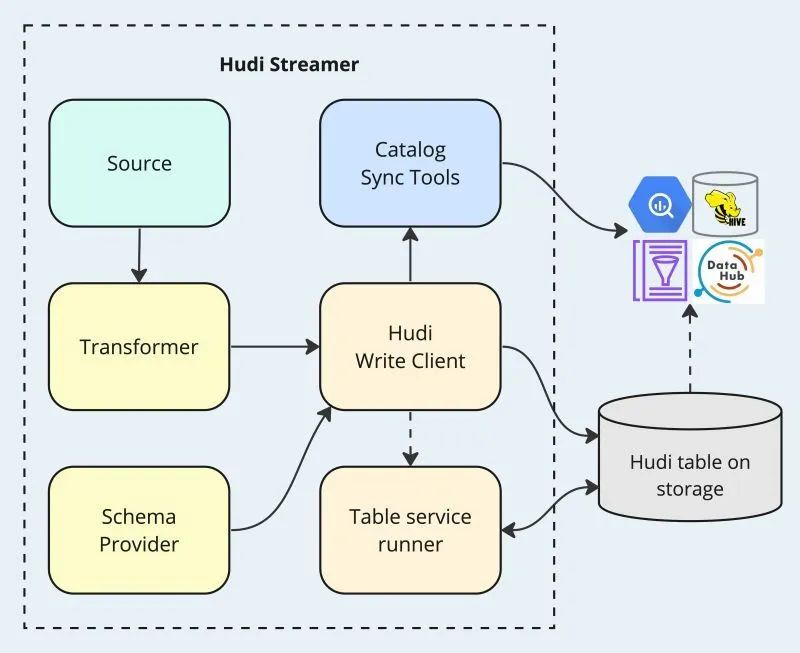
Hudi Streamer
Hudi Streamer
Shashank深入探讨了Apache Hudi Streamer,这是实时数据管道背后的工具。他解释了它如何支持低延迟摄取、upsert操作、模式演化和时间旅行 - 将批处理ETL转变为流式管道,用于欺诈检测和大规模个性化推荐等用例。
Apache Hudi优化[9]

Hudi优化策略
Hudi优化策略
Nishant分享了优化Apache Hudi以提高成本效益和性能的实用经验,涵盖智能压缩、高级索引、小文件调优、分区和Parquet优化 - 所有这些都旨在减少EMR、S3和Athena成本,同时保持管道快速和可靠。
为什么Apache Hudi在您的数据架构中值得一席之地[10]

Hudi数据架构
Hudi数据架构
这篇文章强调了Apache Hudi在现代数据架构中的突出地位,专注于其实时摄取、高效upsert/delete操作和灵活的存储模式(COW和MOR)。它强调了Hudi的开放设计、与流行引擎的集成以及简化CDC和数据重新处理的时间旅行和增量拉取等功能。
社区活动
Hudi团队参加VeloxCon 2025

VeloxCon 2025
VeloxCon 2025
Apache Hudi PMC成员Shiyan Xu代表Hudi参加了VeloxCon[11] 2025。他的演讲探讨了Hudi-rs(Apache Hudi的原生Rust实现)如何实现与Velox引擎的紧密集成,为查询性能带来重大改进。录像应该很快就会提供!
项目更新

Hudi项目
Hudi项目
GitHub ❤️⭐️ https://github.com/apache/hudi
- • PR#13176[12]、PR#13239[13]、PR#13110[14]: 这些增强改进了Spark Web UI的可见性,通过显示Hudi DELETE、MERGE INTO和UPDATE语句的完整DAG,使得跟踪、调试和优化查询执行计划变得更加容易。
- • PR#13129[15]: 通过使数据源读取器能够使用SparkHoodieTableFileIndex进行文件列表,绕过元数据表,从而增加了在Databricks Spark运行时上查询Hudi表的支持。
- • PR#13200[16]: 弃用对Flink 1.14的支持。
Hudi资源
入门指南 🏁
如果您刚开始使用Apache Hudi,以下是一些深入了解实际方面的快速指南。
- • Apache Spark[17]
- • Apache Flink[18]
- • Docker演示[19]
官方文档 📗
- • https://hudi.apache.org/docs/next/overview
加入Slack 🤝
讨论问题、帮助他人并向社区学习。我们的Slack频道是4000多名Hudi用户的家园。
- • https://join.slack.com/t/apache-hudi/shared_invite/zt-2ggm1fub8-_yt4Reu9djwqqVRFC7X49g
社交媒体 📱
加入我们的社交渠道,了解从深度技术概念到技巧和社区中发生的有趣事情。
- • LinkedIn: https://www.linkedin.com/company/apache-hudi/
- • Twitter/X: https://twitter.com/apachehudi
- • Youtube: https://www.youtube.com/@apachehudi/featured
每周办公时间 💼
Hudi PMC成员/提交者将举办办公时间,以帮助交互式回答问题,先到先得。这是提出任何疑问的绝佳机会。
- • https://hudi.apache.org/community/office_hours
有兴趣为Hudi做贡献?👨🏻💻
Apache Hudi社区欢迎任何人的贡献!以下是您可以参与的几种方式。
- • https://hudi.apache.org/contribute/how-to-contribute
数据生态系统其他动态
- • 无盘、无状态、无领导者 – 现代数据流的漫画指南[20] - Sijie Guo | StreamNative
- • 自定义Flink窗口的案例:扩展您的流用例[21] - Pedro Mazala | Evoura
- • Uber的Ray on Kubernetes之旅:资源管理[22] - Uber工程
- • 我们关闭了Snowflake - 这就是原因[23] - Arturas Tutkus | Kayak
- • 研究论文 - Lance:通过自适应结构编码实现列式存储中的高效随机访问[24]
引用链接
[1] Onehouse.ai:http://onehouse.ai/
[2]OpenXData:https://www.openxdata.ai/#details
[3]从沼泽到溪流:Apache Hudi如何改变现代数据湖:https://medium.com/aimonks/from-swamp-to-stream-how-apache-hudi-transforms-the-modern-data-lake-8a938f517ea1
[4]在Apache Hudi Lakehouse平台中引入二级索引:https://hudi.apache.org/blog/2025/04/02/secondary-index/
[5]集成Apache Doris和Hudi进行数据查询和迁移:https://dzone.com/articles/integrate-apache-doris-hudi-data-querying-migration
[6]如何在AWS Glue中读取较旧版本的Hudi表:https://medium.com/@sagarlakshmipathy/how-to-read-an-older-version-hudi-table-in-aws-glue-e26e8e87cc87
[7]现代数据架构:将数据库迁移到AWS上的可扩展数据湖仓:https://www.linkedin.com/posts/romanceresnak_aws-datamigration-lakehousearchitecture-activity-7323285299969597441-REpw?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAe2ProBHdAyUIZhBrUpAkbJdP0HvCi1uAU
[8]Apache Hudi Streamer:https://www.linkedin.com/posts/shashank219_dataengineering-activity-7320294522280636416-RVUS?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAe2ProBHdAyUIZhBrUpAkbJdP0HvCi1uAU
[9]Apache Hudi优化:https://www.linkedin.com/posts/nishant-panwar18_bigdata-costoptimization-etl-activity-7315351709516460034-oZ9h?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAe2ProBHdAyUIZhBrUpAkbJdP0HvCi1uAU
[10]为什么Apache Hudi在您的数据架构中值得一席之地:https://www.linkedin.com/posts/ehenein_dataengineering-apachehudi-bigdata-activity-7323548039623716864-CIGX?utm_source=share&utm_medium=member_desktop&rcm=ACoAAAe2ProBHdAyUIZhBrUpAkbJdP0HvCi1uAU
[11]VeloxCon:https://veloxcon.io/
[12]PR#13176:https://github.com/apache/hudi/pull/13176
[13]PR#13239:https://github.com/apache/hudi/pull/13239
[14]PR#13110:https://github.com/apache/hudi/pull/13110
[15]PR#13129:https://github.com/apache/hudi/pull/13129
[16]PR#13200:https://github.com/apache/hudi/pull/13200
[17]Apache Spark:https://hudi.apache.org/docs/next/quick-start-guide
[18]Apache Flink:https://hudi.apache.org/docs/next/flink-quick-start-guide
[19]Docker演示:https://hudi.apache.org/docs/next/docker_demo
[20]无盘、无状态、无领导者 – 现代数据流的漫画指南:https://streamnative.io/blog/diskless-stateless-leaderless---a-comic-guide-to-modern-data-streaming
[21]自定义Flink窗口的案例:扩展您的流用例:https://pedromazala.substack.com/p/the-case-for-a-custom-window-in-flink
[22]Uber的Ray on Kubernetes之旅:资源管理:https://www.uber.com/en-CA/blog/ubers-journey-to-ray-on-kubernetes-resource-management/
[23]我们关闭了Snowflake - 这就是原因:https://arturastutkus.substack.com/p/we-shut-down-snowflake-and-heres?r=3nzb0&utm_campaign=post&utm_medium=web&triedRedirect=true
[24]Lance:通过自适应结构编码实现列式存储中的高效随机访问:https://arxiv.org/abs/2504.15247
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号