Apache Flink快速入门-什么是Apache Flink

Apache Flink快速入门-什么是Apache Flink

jack.yang
发布于 2025-04-05 11:02:58
发布于 2025-04-05 11:02:58
前言
在数字化时代,企业每天都在面对持续不断增长的数据需要处理,这些数据可能来自IOT、移动或 Web 应用程序生成的采集温度、流量、定位、跟踪、监管、日志文件、网上购物数据、游戏玩家活动、社交网站信息或者是金融交易等。能够及时地处理并分析这些流数据对企业来说至关重要。传统的批处理拥有巨大吞吐量的优势,但是随之而来的是极其高延迟的缺陷。随着大数据系统的不断发展,传统的批处理已然无法全部满足对 时效性 要求愈加严苛的业务需求。为了适应逐渐变得实时的年代,大数据系统架构也由简单的批处理转向批流混合的Lambda架构,最后可能会逐渐演变成只有流计算的高精准高时效的Kappa架构。
无论是看起来像是过渡期产物的批流混合,还是感觉像是终结者的纯流式计算,都离不开最核心的计算组件:流式计算系统。做为当今最火热的流式计算引擎,Flink以其卓越的性能、高度可信的正确性等种种特性收获了大量粉丝。
Apache Flink简介
Apache Flink一款处理数据流的流行框架及分布式处理引擎,用于对无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。它具有真正的流模型,不会将输入数据作为批处理或微批处理。Apache Flink 由 Data Artisans 公司创立,现在由 Apache Flink 社区在 Apache License 下开发。
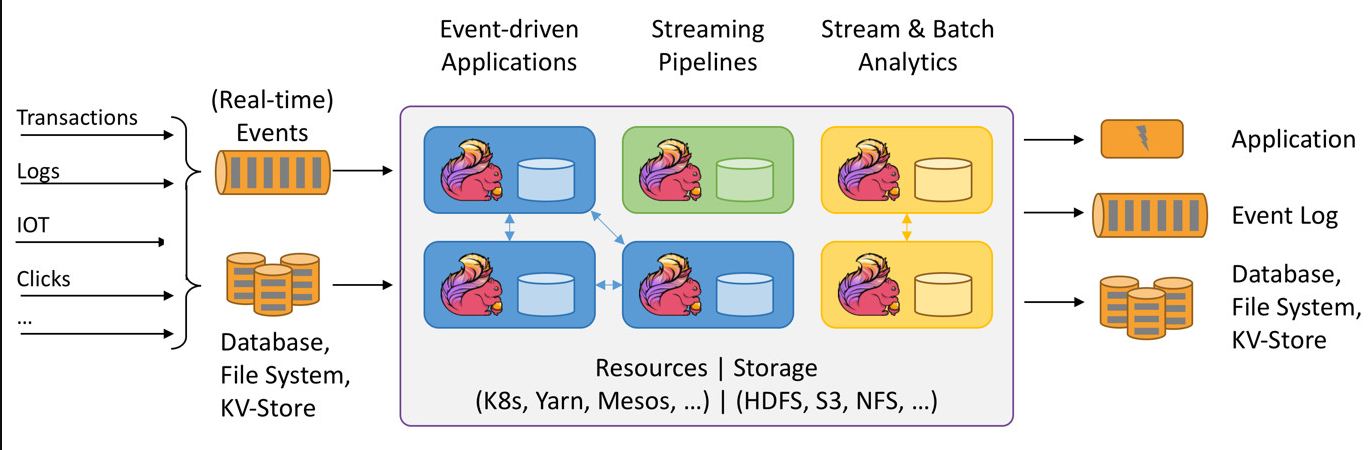
Flink 架构的重要方面
Apache Flink 擅长处理无界和有界数据集。对时间和状态的精确控制使 Flink 的运行时能够在无界流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部进行处理,从而产生出色的性能。
处理无界和有界数据
任何类型的数据都是作为事件流产生的。信用卡交易、传感器测量、机器日志或用户在网站或移动应用程序上的交互,所有这些数据都是作为流生成的。
数据可以作为无界或有界流进行处理。
- 无界流有一个开始但没有定义的结束。它们不会在生成数据时终止并提供数据。必须连续处理无界流,即事件在被摄取后必须立即处理。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常需要以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果完整性。
- 有界流具有定义的开始和结束。可以通过在执行任何计算之前摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为始终可以对有界数据集进行排序。有界流的处理也称为批处理。
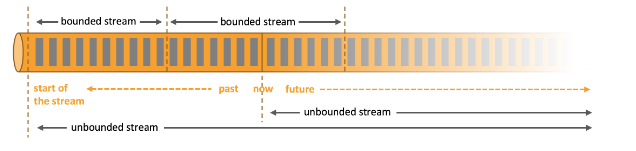
以任何规模运行应用程序
Flink 旨在以任何规模运行有状态的流应用程序。应用程序被并行化为可能在集群中分布式和并发执行的数千个任务。因此,应用程序可以利用几乎无限量的 CPU、主内存、磁盘和网络 IO。而且,Flink 很容易维护非常大的应用状态。其异步和增量检查点算法可确保对处理延迟的影响最小,同时保证恰好一次的状态一致性。
用户报告了在其生产环境中运行的 Flink 应用程序的可扩展性数字令人印象深刻,例如
- 每天处理数万亿个事件的应用程序,
- 维护数 TB 状态的应用程序,以及
- 在数千个内核上运行的应用程序。
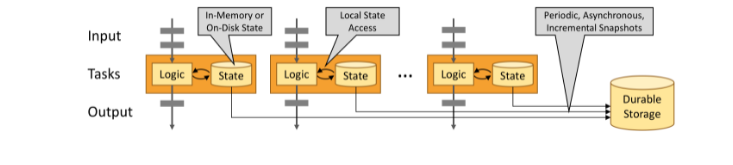
利用内存性能
有状态 Flink 应用程序针对本地状态访问进行了优化。任务状态始终保存在内存中,或者如果状态大小超过可用内存,则保存在访问高效的磁盘数据结构中。因此,任务通过访问本地的、通常在内存中的状态来执行所有计算,从而产生非常低的处理延迟。Flink 通过定期和异步地将本地状态检查点到持久存储来保证在发生故障时的一次性状态一致性。
随处部署应用程序
Apache Flink 是一个分布式系统,需要计算资源才能执行应用程序。Flink 集成了所有常见的集群资源管理器,例如Hadoop YARN、Apache Mesos和Kubernetes,但也可以设置为作为独立集群运行。
Flink 被设计为可以很好地运行前面列出的每个资源管理器。这是通过特定于资源管理器的部署模式来实现的,该模式允许 Flink 以其惯用的方式与每个资源管理器进行交互。
在部署 Flink 应用程序时,Flink 会根据应用程序配置的并行度自动识别所需的资源,并向资源管理器请求。如果发生故障,Flink 会通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都通过 REST 调用发生。这简化了 Flink 在许多环境中的集成
逻辑架构图
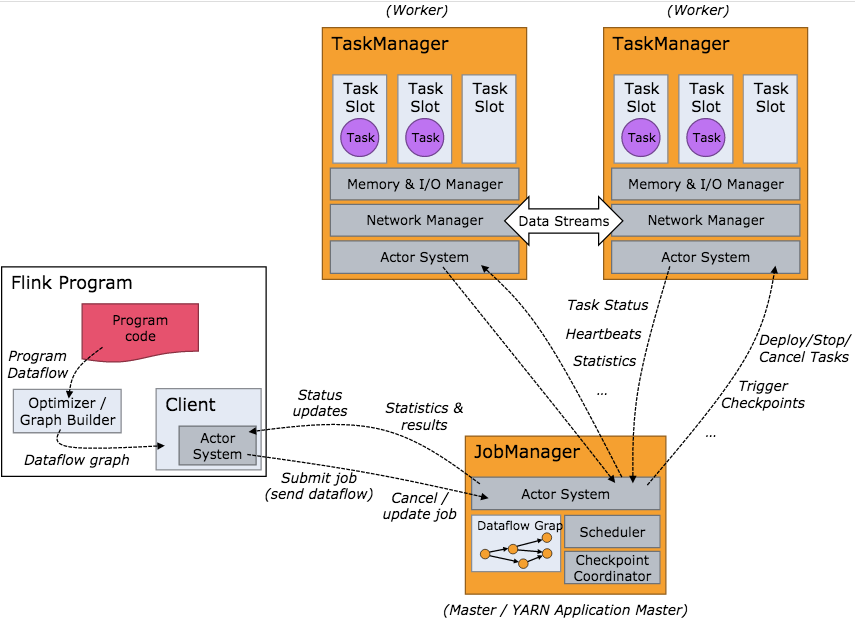
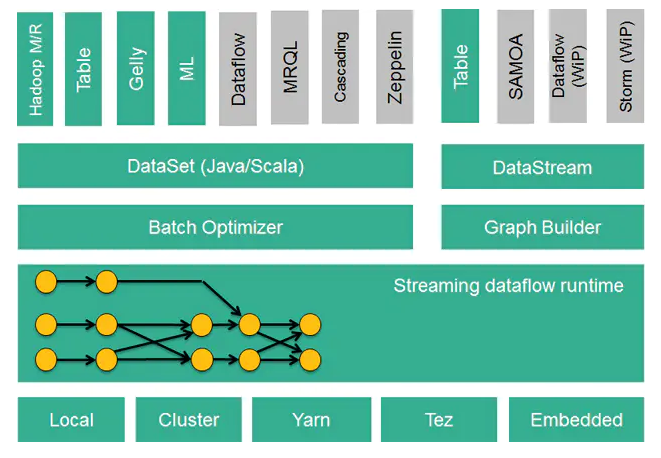
Flink的技术栈
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2021-08-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号