WD:适配GPU DAS的存储系统设计

WD:适配GPU DAS的存储系统设计

数据存储前沿技术
发布于 2025-02-11 19:18:47
发布于 2025-02-11 19:18:47
要点速览
- 加速计算系统下数据中心服务器的架构变化,关注存储/内存解耦,访问时延分级、单机能耗(Fig1);
- 节点本地PCIe 存储难扩展的原因(Fig3)与存储解耦部署的优势分析(Fig4);
- WD 适配GPU DAS的存储系统网络拓扑(Fig5/6);
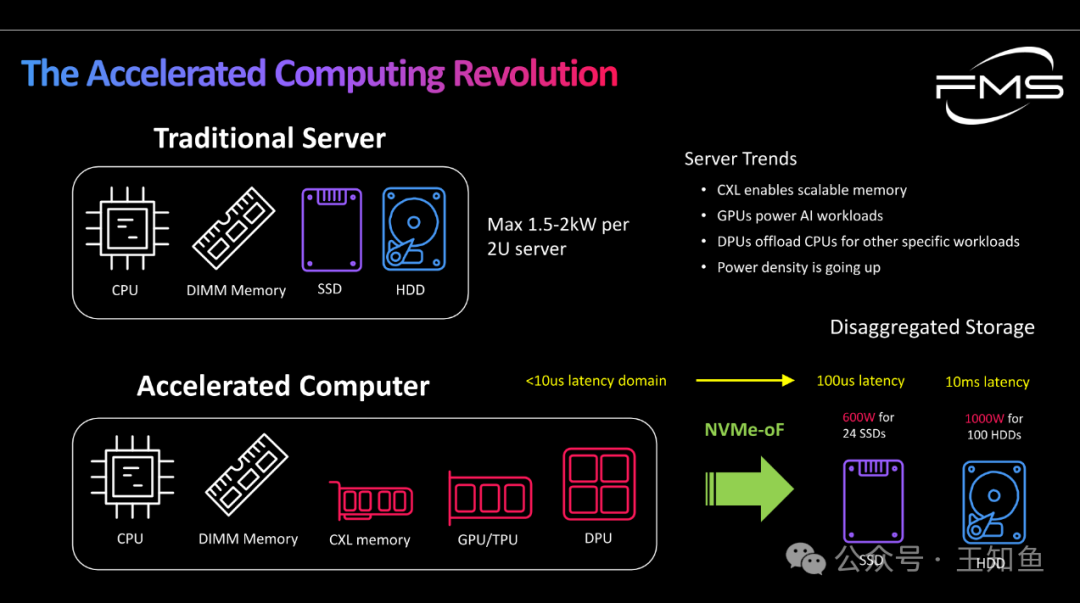
WD:适配GPU DAS的存储系统设计-Fig-1
传统计算与加速计算的服务器架构差异比较
上(传统计算)下(加速计算),有两个重要趋势:
- IO组件的解耦,原基于本地存储,现数据中心存储资源已充分解耦,演变为分布式基础设施,内存DRAM 因CXL技术,有进一步解耦,以实现扩展的可能;
- 专用计算硬件的兴起,GPU/TPU等在新计算架构中发挥重要作用;
分级存储延迟阈:
- <10微秒(us)的数据延迟是本地数据访问的范围;
- 100微秒延迟 -> NVMe-oF连接SSD,功耗:600W(24个SSD)
- 10毫秒延迟 -> NVMe-oF连接HDD,功耗:1000W(100个HDD)
加速计算的功耗将快速上升。
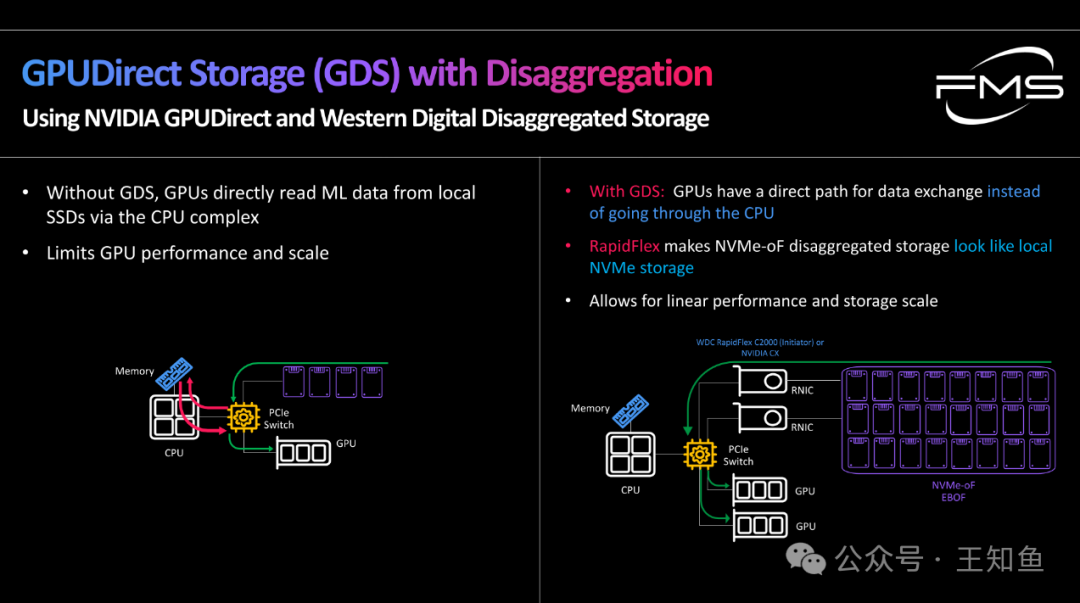
WD:适配GPU DAS的存储系统设计-Fig-2
使用NVIDIA GPUDirect和Western Digital解耦存储技术
左侧:没有GDS的情况下
- GPU需通过CPU复杂路径从本地SSD读取机器学习数据。
- 这种方式限制了GPU性能和扩展能力。
数据链路:
- 数据流:CPU -> PCIe交换机 -> GPU
- SSD通过CPU间接连接GPU,增加延迟。
右侧:使用GDS的情况下
- 数据路径优化:
- GPU可以直接进行数据交换,而无需通过CPU路径。
- RapidFlex优势:
- 使NVMe-oF解耦存储看起来就像本地NVMe存储。
- 性能与扩展性:
- 支持线性性能增长和存储扩展。
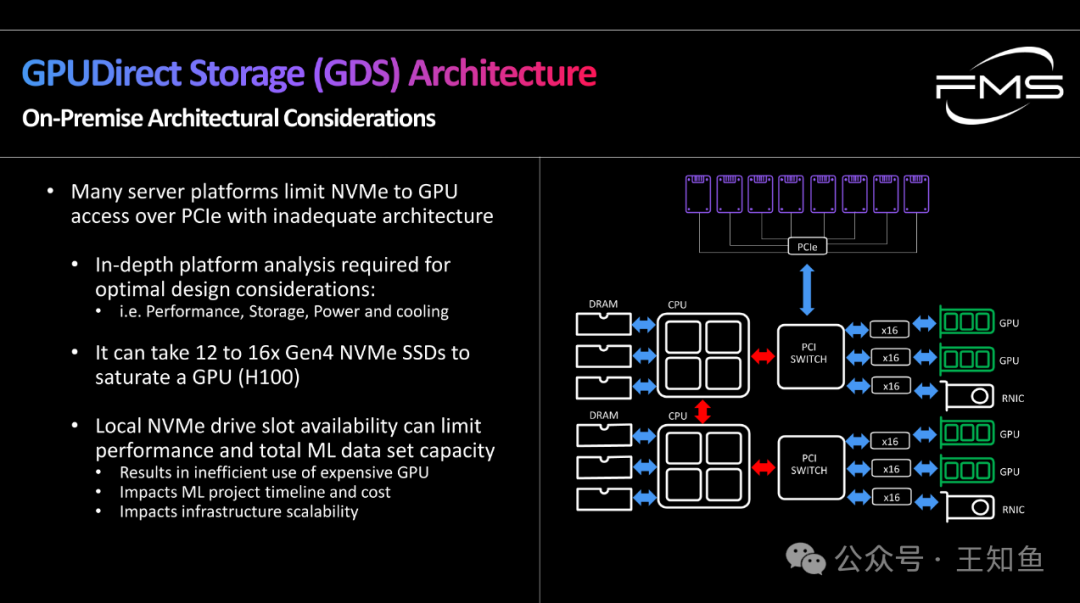
WD:适配GPU DAS的存储系统设计-Fig-3
GPU 直连存储架构-本地存储的考量点
左侧内容:
- 许多服务器平台由于架构不完善,限制了 NVMe 通过 PCIe 访问 GPU 的能力。
- 如性能、存储、电源和散热等方面。
- 需要进行深入的设计分析以优化平台:
- 为了充分利用 GPU(如 H100),可能需要 12 到 16 个 Gen4 NVMe SSD(服务器上集成这么多SSD,功耗优化是个大问题)。
- 本地 NVMe 驱动器插槽的可用性可能限制性能和机器学习数据集的总容量:
- 导致昂贵 GPU 的低效使用。
- 影响机器学习项目的时间和成本。
- 影响基础设施的可扩展性。
图片强调了 GPUDirect Storage(GDS)架构在本地部署时需要注意的关键点:
- 架构限制:许多服务器平台的架构无法高效支持 NVMe 到 GPU 的直接访问。
- 设计优化:需要从性能、存储、电源和散热等角度进行深入分析。
- 硬件需求:一个高性能 GPU(如 H100)可能需要 12 到 16 个 Gen4 NVMe SSD 才能达到满负荷。
- 资源限制的影响:NVMe 插槽不足会导致 GPU 性能浪费,增加项目成本,并限制系统可扩展性。
总体来看,GDS 的实施需要高效的硬件架构支持,以确保性能和扩展能力。
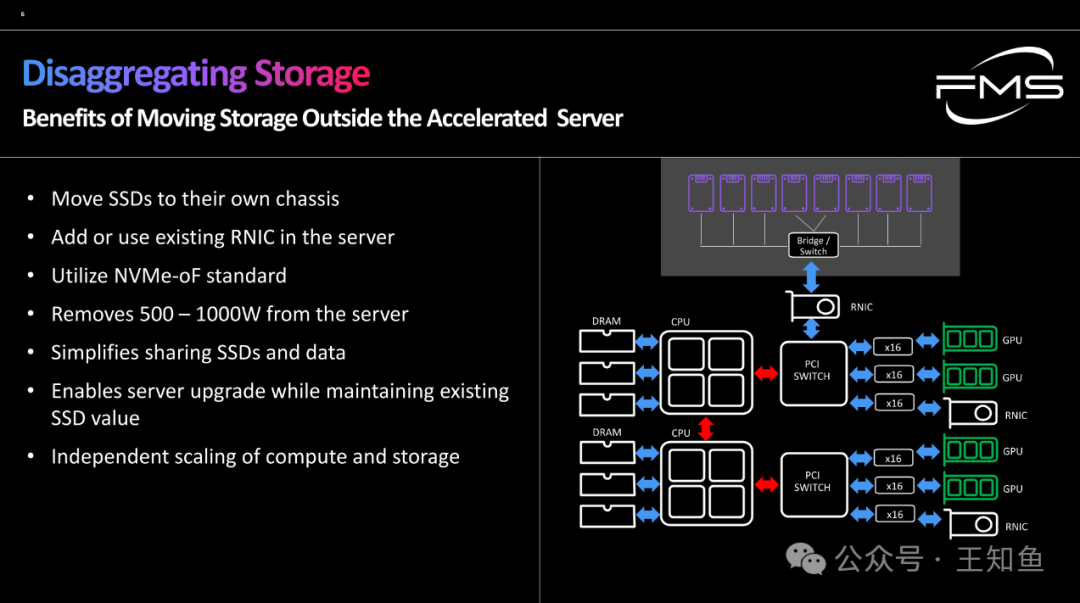
WD:适配GPU DAS的存储系统设计-Fig-4
存储解耦-将磁盘置于加速节点外的好处
- 将SSD移动到它们自己的机箱
- 在服务器中添加或使用现有的RNIC
- 利用NVMe-oF标准
- 从服务器中移除500至1000瓦的功率
- 简化SSD和数据的共享
- 在保持现有SSD价值的同时,启用服务器升级
- 计算和存储的独立扩展
右图示意通过RNIC连接解耦的NVMe-SSD存储资源池,以充分优化加速计算架构。
RNIC 是 "Remote Network Interface Card"(远程网络接口卡)的缩写,但更具体地,它通常指的是 "RDMA-enabled Network Interface Card"(支持远程直接内存存取的网络接口卡)。RDMA (Remote Direct Memory Access) 技术允许网络中的计算机直接从一台计算机的内存读取或写入另一台计算机的内存中,而无需通过操作系统内核,从而减少延迟和CPU负载。
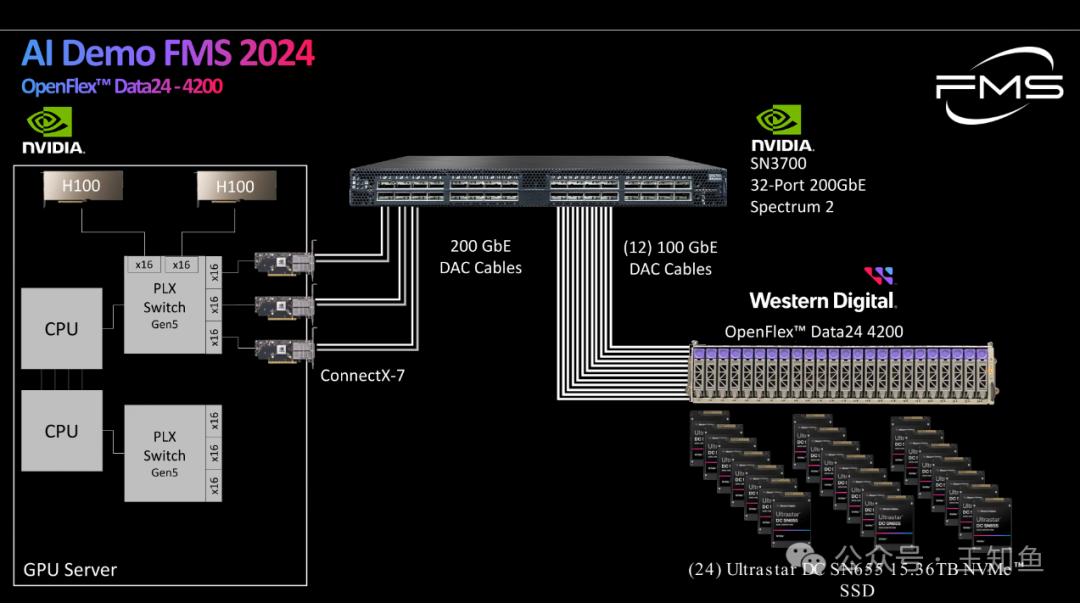
WD:适配GPU DAS的存储系统设计-Fig-5
图示 Nvidia 基于WD SN655系列 NVMe-SSD 构建的GDS 直连存储AI加速服务器,主要特征如下(从左往右):
- CPU/GPU服务器: 包含2个CPU、2个PLX Switch Gen5 交换机,扩展2块 H100 GPU和3张ConnectX-7网络接口卡。
- NVIDIA SN3700交换机: 提供32个200GbE端口,支持Spectrum 2技术。
- 存储解决方案: 使用Western Digital的OpenFlex™ Data24 4200存储系统,包含24个Ultrastar DC SN655 NVMe SSD,每个容量为15.36TB。
Note:左图下方的PLX交换机只有3个x16 PCIe扩展槽?
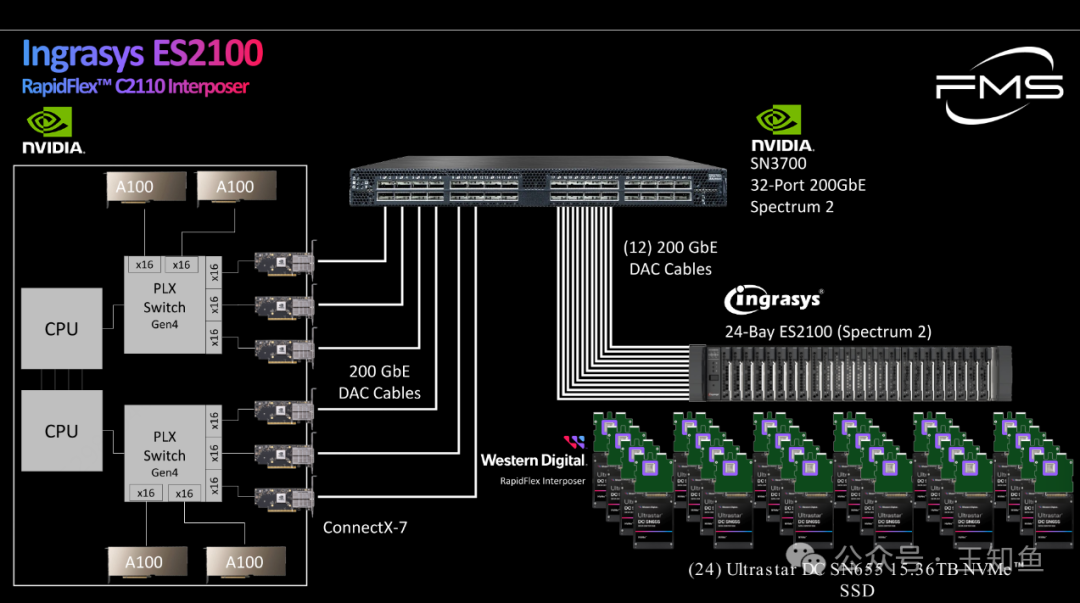
WD:适配GPU DAS的存储系统设计-Fig-6
适配A100 的 Ingrasys ES2100 存储系统
与H100 的差异是:计算单元使用的是PCIe Gen4 的PLX 交换机,存储节点支持12个200GbE接口

WD:适配GPU DAS的存储系统设计-Fig-7
Ingrasys ES2100 存储节点主要参数:
- 12个200GbE外部端口
- 24个U.2 SSD,每个SSD通过2x50GbE WDC主板连接——使用32TB SSD时总容量为770TB
- 支持NVMe-oF/RDMA或IP协议
- 性能 = 计算层 + SSD + 600ns延迟
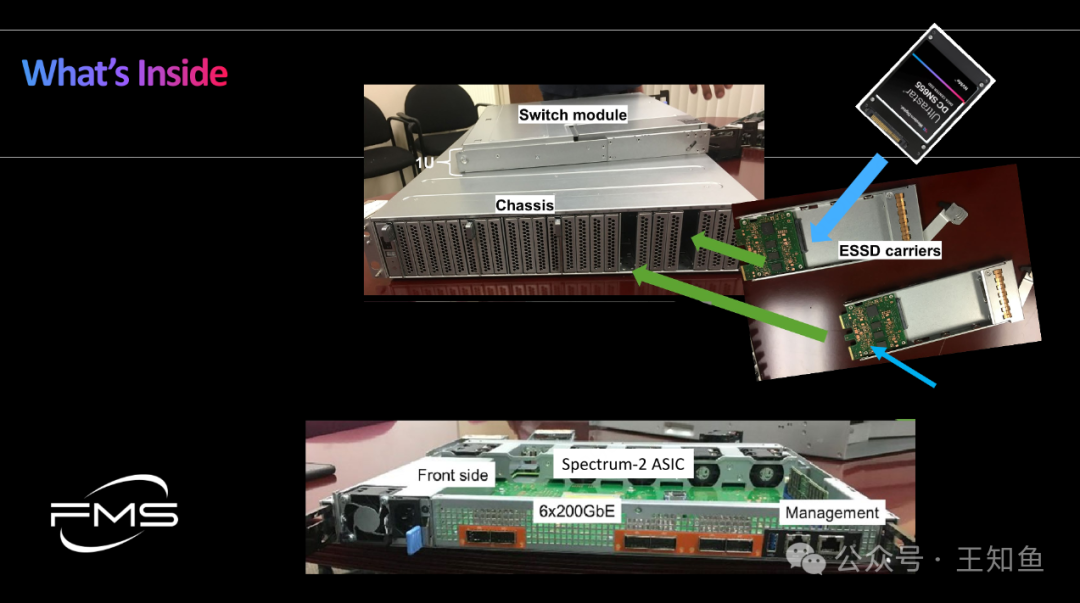
WD:适配GPU DAS的存储系统设计-Fig-8
ES2100 内部视图
与现有数据中心U.2 SSD/HDD 接口不同的是,基于E3.s 的NVMe SSD,需要插槽内集成ESSD 载板。
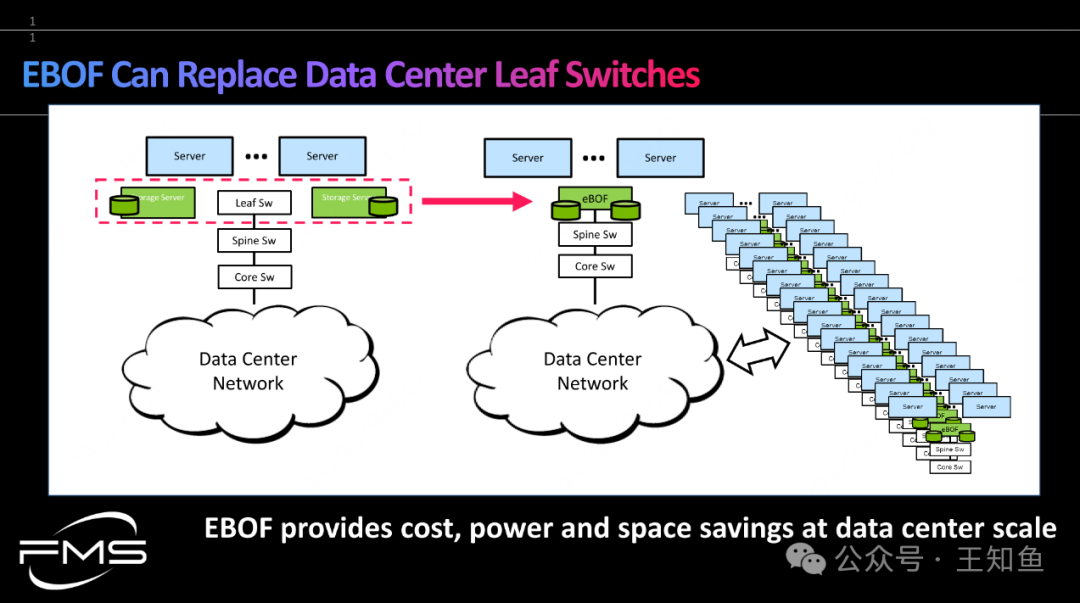
WD:适配GPU DAS的存储系统设计-Fig-9
基于NVMe的直接访问协议,EBOF存储系统内部集成了强大的通信系统,在新型数据中心设计中,可省去原架构中独立的存储接入网络。
Note:这一套系统做下来,说节约能耗和占用空间(相对HDD系统)还是有说服力的,但要说节约成本,估计自己这一关都不去。
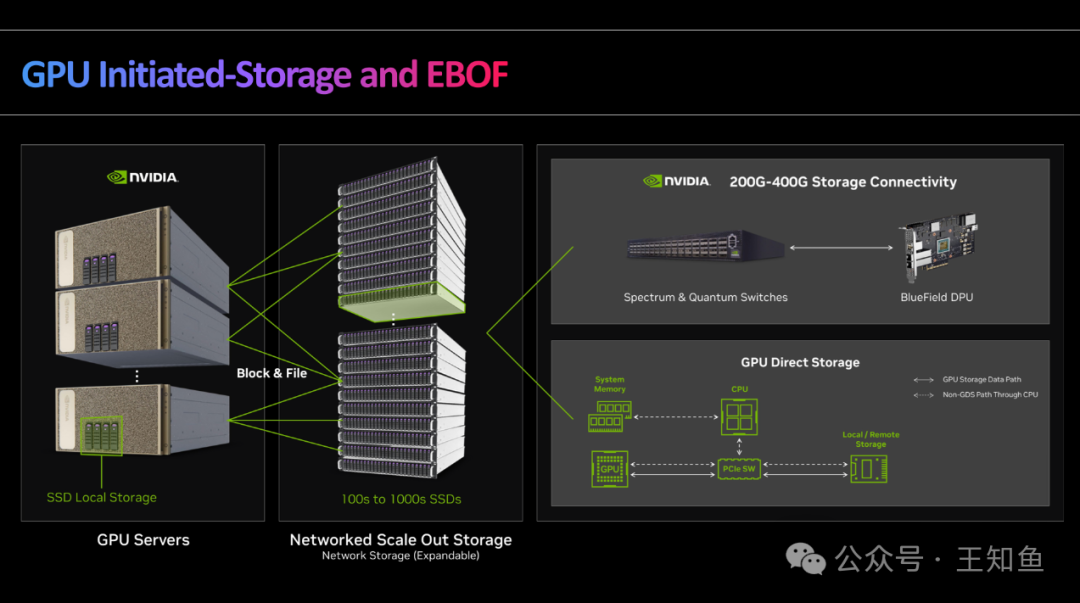
WD:适配GPU DAS的存储系统设计-Fig-10
以GPU为中心的存储扩展系统,从左往右依次为:
- 本地SSD存储;
- 基于网络扩展的存储系统(文件/块存储),DPU加持下的数据网络交换机,可支持GPU直接存储访问和通过CPU调度存储两种IO行为;
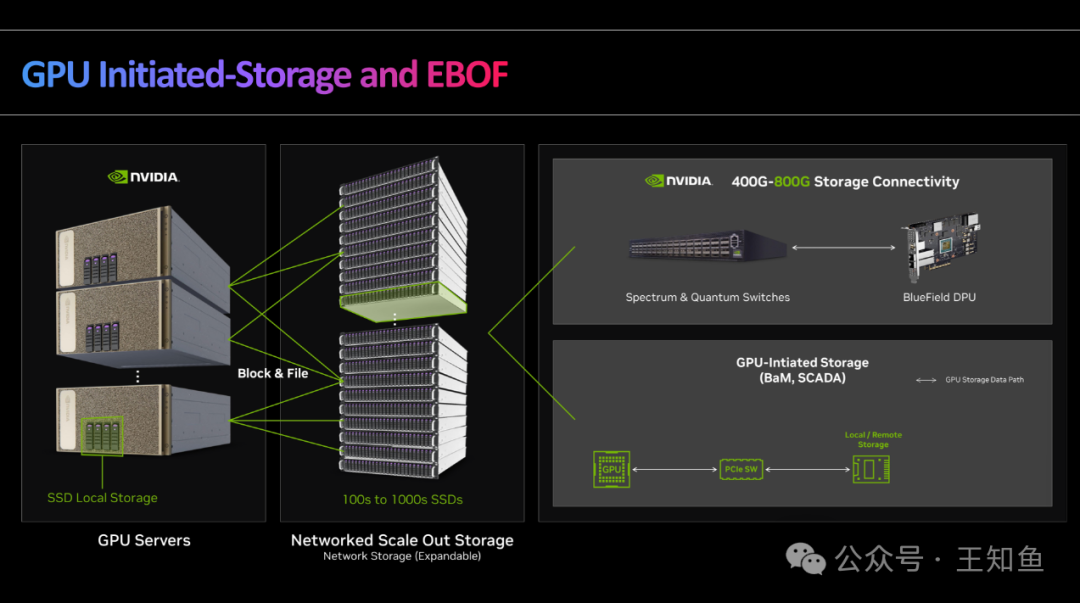
WD:适配GPU DAS的存储系统设计-Fig-11
与前图差异的地方在于,数据交换网络增强至400-800 GbE,得益于更大的数据传输带宽,从成本效率考虑,更推荐使用GPU直接访问存储技术,如BaM架构。
关于BaM/SCADA架构,可参考:

WD:适配GPU DAS的存储系统设计-Fig-12
在高速网络和GPU直接访问的设计下,先进的Flash SSD时延被大大缩短,性能明显提升,可跃升为内存行列的基础设施,从而增强以GPU为核心的数据处理系统。

WD:适配GPU DAS的存储系统设计-Fig-13
物理世界模拟案例
图片展示了NVIDIA Index Demo FMS 2024的一个演示案例,旨在可视化世界上最猛烈的龙卷风。具体信息如下:
- 性能对比:
- 当启用GPUDirect Storage时,系统能够达到13 FPS(帧每秒)和最高89 GBS(千兆字节每秒)的读取吞吐量。
- 当禁用GPUDirect Storage时,系统性能下降到4 FPS和最高15 GBS的读取吞吐量。
- 数据处理能力:
- 启用GPUDirect Storage时,系统每65秒可以处理约5.9TB的数据集。
- 这种高性能使得用户能够进行交互式导航、实时参数调整以及轻松地通过模拟进行擦除。
- 图像细节:
- 演示中使用了2500亿个网格点,每个网格点包含多种属性,如降雨、冰雹、气压和风速,以实现高度详细的龙卷风模拟。
总结
SSD作为大容量存储扩展单元,在接口PCIe升级到Gen5+交换网络升级到200GbE以上+GPU IO 直通等先进技术加持下,因持久化数据的IO行为,其时延与CXL 内存扩展相差3个数量级左右,纵观整个AI数据堆栈,另一种策略是:基于CXL的分层存储+热数据调度。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号