AptaTrans:一种使用预训练编码器预测适配体-蛋白质相互作用的深度神经网络
原创
AptaTrans:一种使用预训练编码器预测适配体-蛋白质相互作用的深度神经网络
原创
用户10497140
发布于 2025-01-03 21:39:30
发布于 2025-01-03 21:39:30

BMC
本文介绍了 AptaTrans,这是一个深度学习框架,用于使用基于 transformer 的编码器预测适配子-蛋白质相互作用 (API)。适配子是单链 DNA/RNA 分子,可以以高特异性和亲和力与靶蛋白结合,使其在药物发现中具有价值。用于适配体发现的传统 SELEX 方法非常耗时且成功率有限。为了应对这些挑战,作者开发了 AptaTrans,它使用预训练的编码器在单体水平上处理适配体和蛋白质序列,并捕获它们之间的物理化学相互作用。该模型在基准数据集上进行了评估,其性能优于现有的 API 预测方法。AptaTrans 管道还与生成算法 Apta-MCTS 集成,以推荐候选适配子。作者预计 AptaTrans 将提高 SELEX 在药物发现中的成本效益和效率。
Key Points
- AptaTrans is a deep learning framework for predicting aptamer-protein interactions (API) using transformer-based encoders AptaTrans 是一个深度学习框架,用于使用基于 transformer 的编码器预测适配子-蛋白质相互作用 (API)
- It aims to address the limitations of the conventional SELEX method for aptamer discovery, which is time-consuming and has limited success rates 它旨在解决传统 SELEX 方法在适配体发现方面的局限性,该方法耗时且成功率有限
- AptaTrans uses pretrained encoders to handle aptamer and protein sequences at the monomer level and capture the physicochemical interactions between them AptaTrans 使用预训练的编码器在单体水平上处理适配体和蛋白质序列,并捕获它们之间的物理化学相互作用
- The model outperformed existing API prediction methods when evaluated on a benchmark dataset 在基准数据集上进行评估时,该模型的性能优于现有的 API 预测方法
- The AptaTrans pipeline integrates with a generative algorithm, Apta-MCTS, to recommend aptamer candidates AptaTrans 管道与生成算法 Apta-MCTS 集成,以推荐候选适配子
- The authors expect AptaTrans to enhance the cost-effectiveness and efficiency of SELEX in drug discovery 作者预计 AptaTrans 将提高 SELEX 在药物发现中的成本效益和效率
AptaTrans 模型的关键组成部分
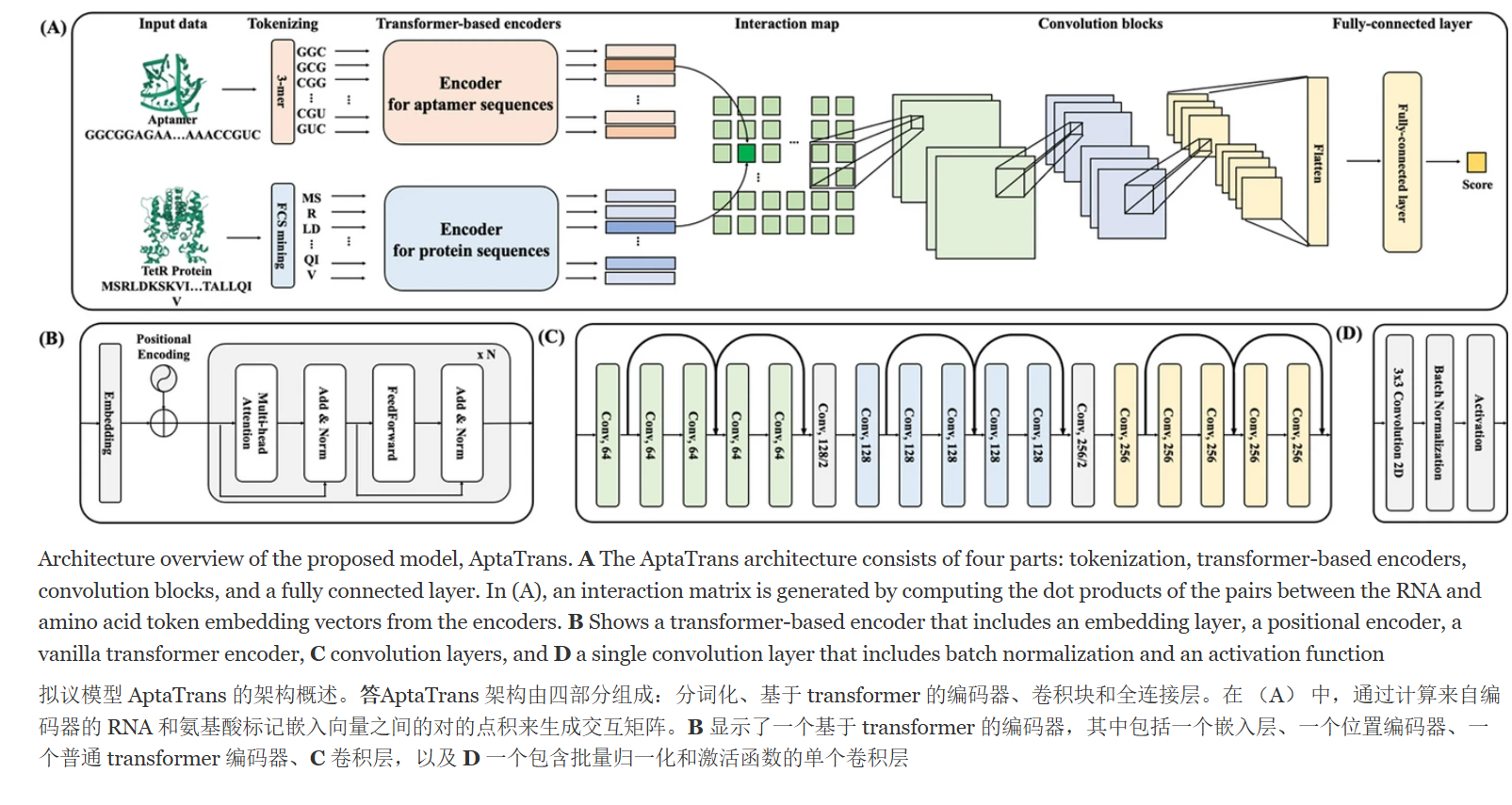
The key components of the AptaTrans model are: AptaTrans 模型的关键组件是:
- Transformer-based encoders: AptaTrans uses transformer-based encoders, Encoderapta(·) and Encoderprot(·), to transform the tokenized aptamer and protein sequences into contextual vector representations. 1 基于 transformer 的编码器:AptaTrans 使用基于 transformer 的编码器 Encoderapta(·) 和 Encoderprot(·),将标记化的适配子和蛋白质序列转换为上下文向量表示。1
- Tokenization algorithms: AptaTrans employs tokenization algorithms to convert the aptamer and protein sequences into numerical representations. Specifically, it uses 3-mers for aptamer sequences and frequent contiguous substrings (FCS) for protein sequences. 1 分词算法:AptaTrans 采用分词算法将适配子和蛋白质序列转换为数字表示。具体来说,它对适配子序列使用 3-mer,对蛋白质序列使用频繁的连续子串 (FCS)。
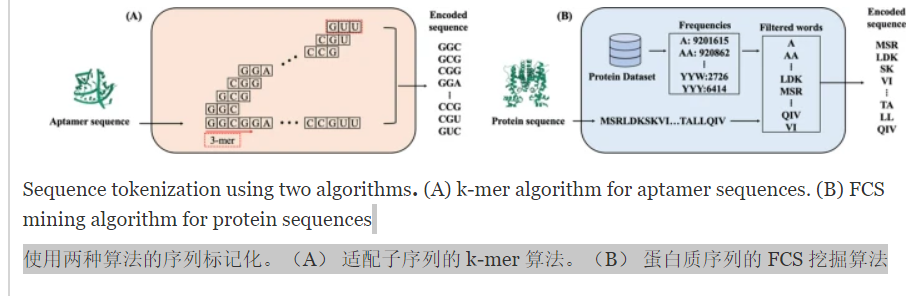
K-mer FCS
- Interaction matrix: AptaTrans creates an interaction matrix by computing the dot products of the pairs between the aptamer and protein token embedding vectors. This interaction matrix serves as a feature map for the downstream layers. 交互矩阵:AptaTrans 通过计算适配体和蛋白质标记嵌入向量之间对的点积来创建交互矩阵。此交互矩阵用作下游层的特征图。
- Convolutional layers: The model uses convolutional layers to extract information from the interaction matrix. 卷积层:该模型使用卷积层从交互矩阵中提取信息。
- Fully connected layer: AptaTrans uses a fully connected layer to predict the binding scores between the aptamer and protein. 1 全连接层:AptaTrans 使用全连接层来预测适配子和蛋白质之间的结合分数。1
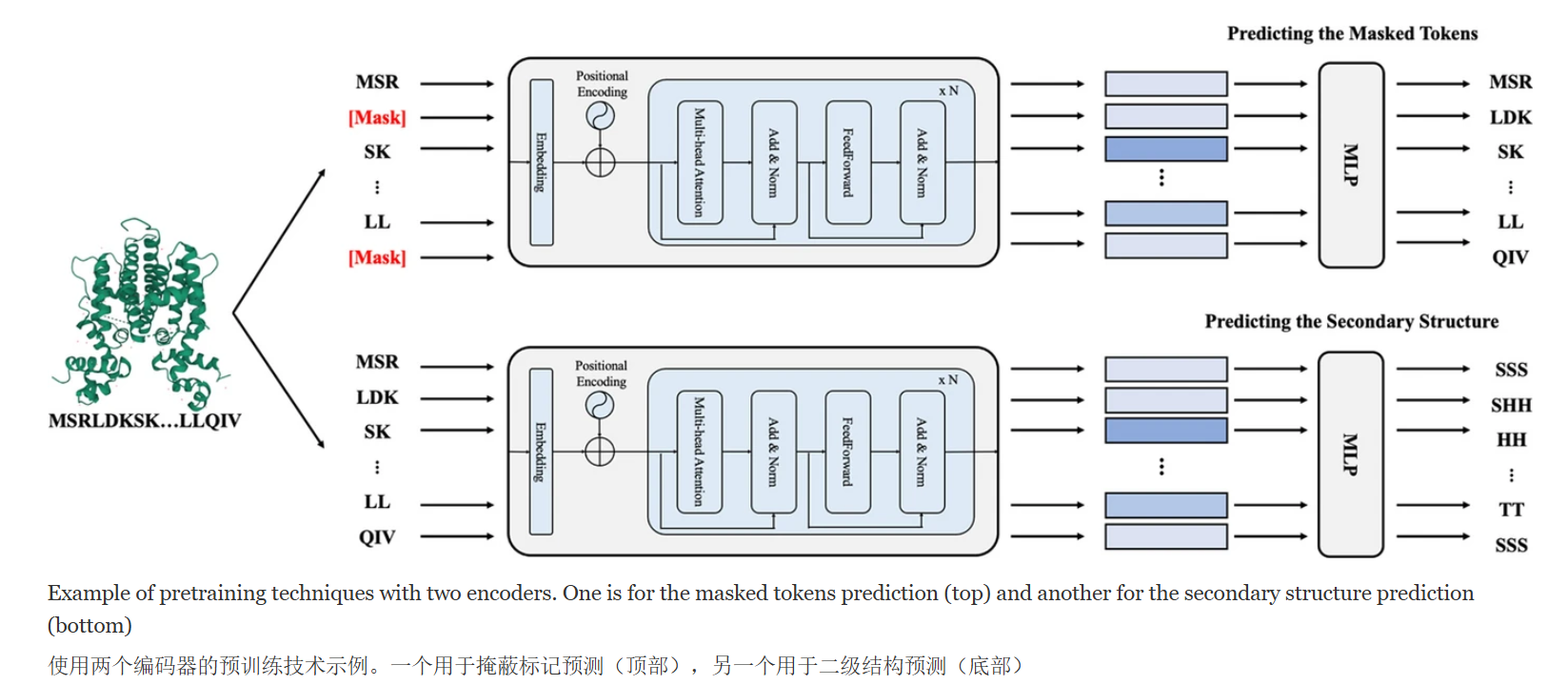
- Pretraining: To ensure optimal sequence embeddings, the transformer-based encoders are pretrained using self-supervised learning strategies that utilize the predictions of masked tokens and the secondary structures of the molecules. 1 预训练:为了确保最佳的序列嵌入,基于 transformer 的编码器使用自监督学习策略进行预训练,这些策略利用掩蔽标记和分子二级结构的预测。1
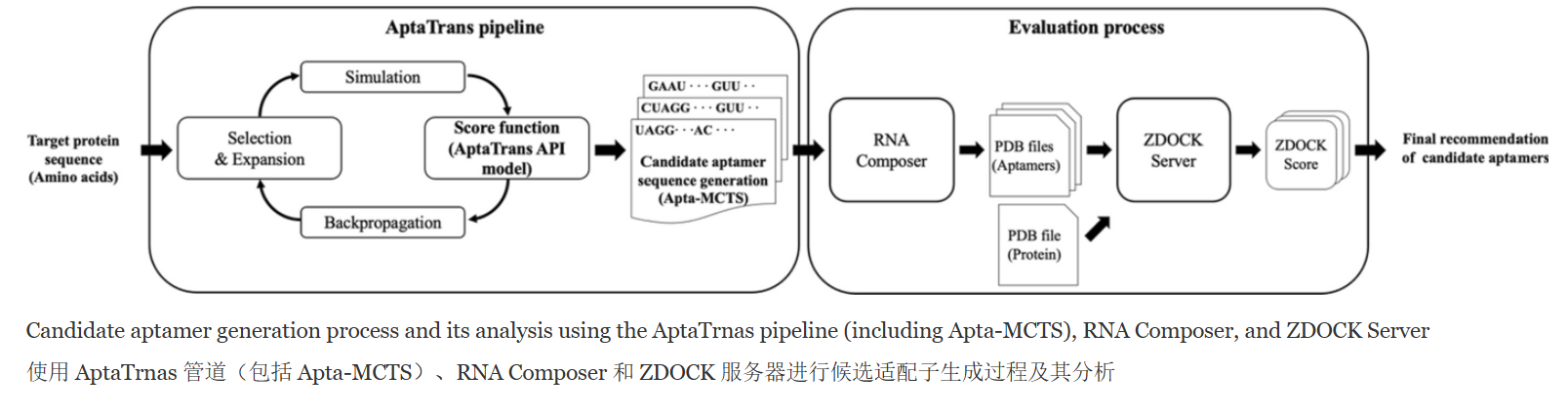
Apta Trans pipeline
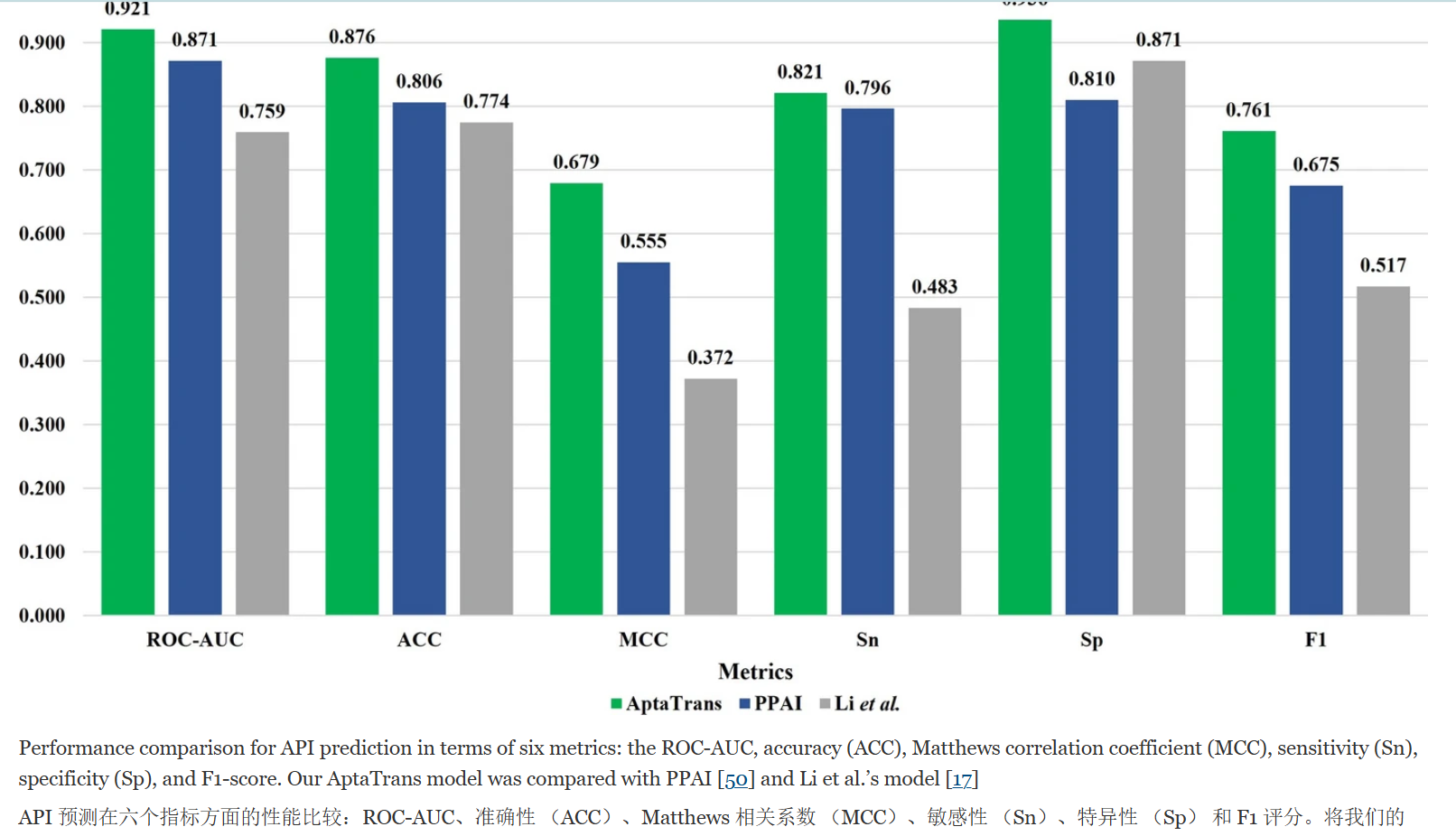
评分
使用教程:
以下是使用AptaTrans Pipeline的基本步骤:
1. 初始化Pipeline
首先,你需要初始化AptaTrans Pipeline。这包括设置一些参数,如维度(dim)、多层前馈网络的倍数(mult_ff)、层数(n_layers)、头数(n_heads)、dropout率(dropout)、是否加载最佳训练点(load_best_pt)、设备(device)和随机种子(seed)。
```python
pipeline = AptaTransPipeline(
dim=128,
mult_ff=2,
n_layers=6,
n_heads=8,
dropout=0.1,
load_best_pt=False,
device='cuda',
seed=1004,
)
```2. 预训练寡核苷酸编码器
使用bpRNA数据集预训练寡核苷酸编码器($encoder\_{apta}$)。你需要设置数据集和批量大小,然后进行预训练。
```python
pipeline.set_data_rna_pt(batch_size=32) # 从bpRNA数据集获取数据
pipeline.pretrain_encoder_aptamer(epochs=1000, lr=1e-5)
```3. 预训练蛋白质编码器
使用PDB数据集预训练蛋白质编码器($encoder\_{prot}$)。同样,你需要设置数据集和批量大小,然后进行预训练。
```python
pipeline.set_data_protein_pt(batch_size=32) # 从PDB数据集获取数据
pipeline.pretrain_encoder_protein(epochs=1000, lr=1e-5)
```
4. 微调AptaTrans进行API预测
在预训练之后,你需要对AptaTrans进行微调,以提高API预测的性能。
```python
pipeline.set_data_for_training(batch_size=16)
pipeline.train(epochs=200, lr=1e-5)
```
5. 预测API得分
使用预训练和微调后的AptaTrans模型,你可以预测给定寡核苷酸和目标蛋白质序列之间的API得分。
```python
# 寡核苷酸序列
aptamer = 'AACGCCGCGCGUUUAACUUCC'
# 目标蛋白质序列
target = 'STEYKLVVVGADGVGKSALTIQLIQNHFVDEYDPTIEDSYRKQVVIDGETCLLDILDTAGQEEYSAMRDQYMRTGEGFLCVFAINNTKSFEDIHHYREQIKRVKDSEDVPMVLVGNKCDLPSRTVDTKQAQDLARSYGIPFIETSAKTRQGVDDAFYTLV'
# 获取寡核苷酸序列和蛋白质序列之间的API得分
pipeline.inference(aptamer, target)
```
6. 推荐候选寡核苷酸
对于给定的目标蛋白质序列,使用Apta-MCTS推荐候选寡核苷酸序列。
```python
# 目标蛋白质序列
target = 'STEYKLVVVGADGVGKSALTIQLIQNHFVDEYDPTIEDSYRKQVVIDGETCLLDILDTAGQEEYSAMRDQYMRTGEGFLCVFAINNTKSFEDIHHYREQIKRVKDSEDVPMVLVGNKCDLPSRTVDTKQAQDLARSYGIPFIETSAKTRQGVDDAFYTLVREIRKHKEKMSK'
# 使用AptaTransPipeline(包括Apta-MCTS和AptaTrans)推荐寡核苷酸
pipeline.recommend(target, n_aptamers=5, depth=40, iteration=1000)
```在使用AptaTrans之前,请确保从提供的Google Drive链接获取必要的数据库文件。这些步骤概述了如何设置和运行AptaTrans Pipeline,以预测API并推荐候选寡核苷酸序列。
本文参考:
BioMed Central是一家独立出版社,致力于提供经过同行评审的生化研究的公开取阅途径(Open Access), BioMed Central发表的所有原创研究文章在发表之后立即可以在网上永久性免费访问。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号