6B 参数 ChatGLM-6B 落地指南:聚焦效率提升与简易部署双优势
原创
6B 参数 ChatGLM-6B 落地指南:聚焦效率提升与简易部署双优势
原创
FI萤火RE
修改于 2024-12-07 20:35:29
修改于 2024-12-07 20:35:29
【C语言】指针相关知识解析与代码示例 作者:池央
https://cloud.tencent.com/developer/article/2465647?shareByChannel=link
作者开篇便直击要害,从指针最基础的概念娓娓道来,以抽丝剥茧般的细致,一步步引领我走进指针的奇妙世界,深入探寻它在用法上潜藏的门道,以及与数组、函数碰撞融合时产生的奇妙 “化学反应”。整个讲解过程逻辑缜密、条理分明,复杂的知识点经作者之手,都化作了通俗易懂的直白表述,毫无晦涩难懂之感。
1.ChatGLM-6B 介绍
ChatGLM-6B是清华大学与智谱AI携手打造的一款先进语言模型,以其创新的通用语言模型(GLM)架构为基础,拥有62亿参数。该模型在自然语言处理领域取得了卓越的表现,因其优化的架构设计而备受关注,成为学术界和工业界广泛讨论的焦点之一。
对于开发者而言,ChatGLM-6B的设计充分考虑了实际应用需求,不仅在处理能力上表现出色,还有效降低了资源消耗。这一特性使得它在硬件限制较大的情况下,也能出色地完成复杂的语言任务,极大地增强了其吸引力。模型的出色性能在多个应用场景中得到了验证,无论是智能客服系统、文本自动生成,还是高级对话系统,ChatGLM-6B都展现出卓越的适应性。
ChatGLM-6B的灵活性和可靠性让开发者能够更专注于核心应用开发,而不必担心因资源不足而导致的性能瓶颈。其在不同任务中的广泛适用性为开发者提供了更多的创新空间和可能性。通过这一模型,开发者可以有效地推动项目进展,从而在竞争激烈的市场中获得优势。
2.服务端实例部署
使用时,我只需登录DAMODEL控制台,选择资源中的GPU实例,轻点“创建实例”按钮,即可快速启动新项目。整个过程快捷高效,大大提高了我的工作效率。
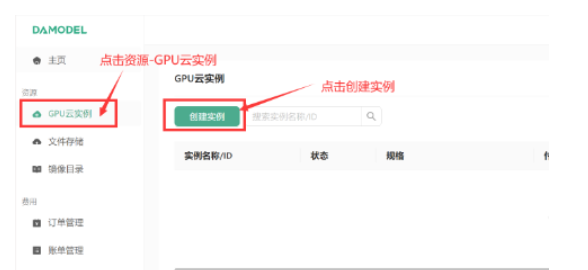
配置NVIDIA GeForce RTX 4090 GPU,其提供60GB内存和24GB显存,非常适合高性能需求。对于新手而言,50GB的数据硬盘空间足以满足基础使用需求,确保项目顺利开展。这样的设置不仅高效,还能根据需要灵活调整。
在配置实例时,我会挑选最适合的镜像。平台提供了一系列基础镜像,方便快速启动项目。在框架选项中,我可以便捷地选择预装了PyTorch 2.4.0环境的镜像。这种灵活性让环境设置变得快速且高效,帮助我更专注于核心开发任务。
为了保证连接的安全性,我创建了一个密钥对。首先,我自定义了一个名称,然后让系统生成密钥对,并将私钥下载到我的计算机上。我将其转换为.pem格式,以便于后续在本地进行安全连接。这种方法不仅提升了安全性,也简化了远程访问的流程。
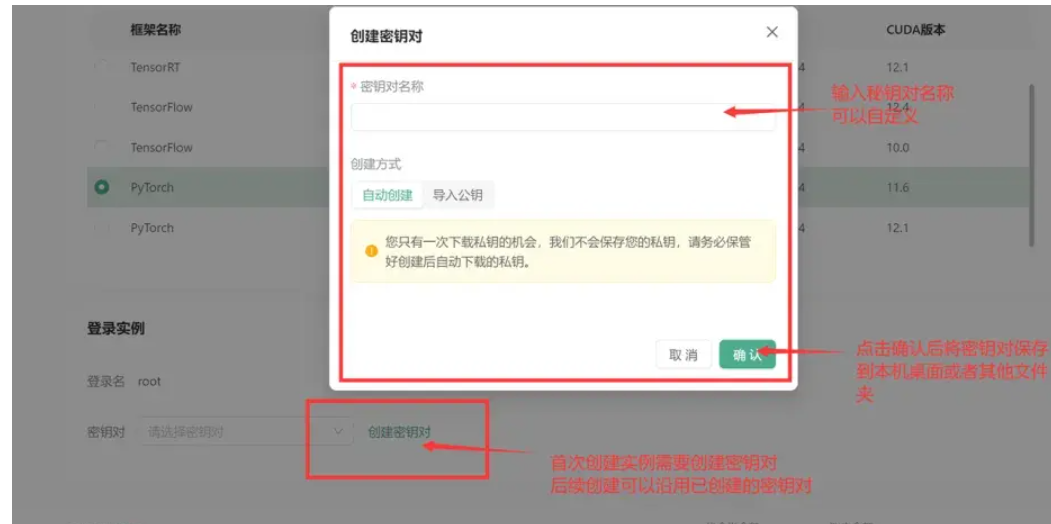
生成密钥对后,我选择了刚创建的密钥,并点击启动按钮。稍等片刻,实例就会启动,这样我就能快速进入项目开发阶段。这样的流程不仅省时,还能让我迅速专注于主要的开发任务,加快了项目的整体进展。
3.模型准备
环境启动后,我会打开终端,并使用git命令克隆ChatGLM-6B项目。如果遇到GitHub连接问题,我会切换到gitcode平台,或者先下载代码再离线上传,以保障项目的顺利进行。这种方式提供了多种选择,确保在各种网络条件下都能顺利推进项目开发。
cd /home/aistudio/work/
git clone https://github.com/THUDM/ChatGLM-6B.git
# 如果遇见github因为网络问题导致失败,可选择gitcode站点进行下载
# git clone https://gitcode.com/applib/ChatGLM-6B.git
项目克隆成功后,你将看到以下目录结构显示在屏幕上。
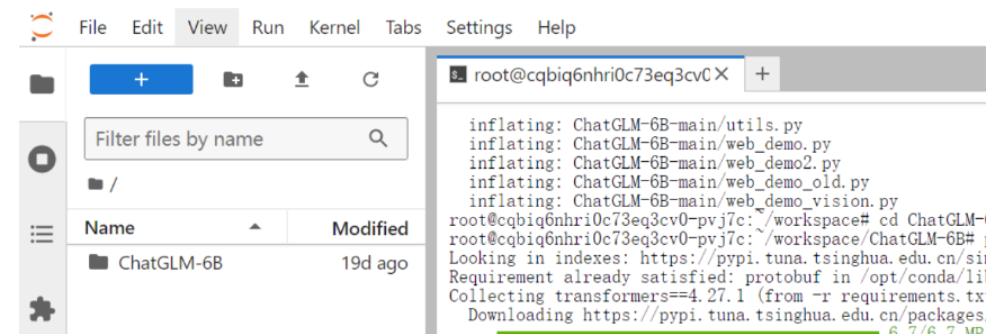
进入项目目录后,通过 pip 命令安装所需的依赖库。
pip install -r requirements.txt当界面提示“Successfully installed”时,所有所需的依赖就已成功安装完毕。这种高效体验让我能够更加专注于开发任务,而不是耗费时间在环境配置上。
在依赖安装完成后,我们需要导入模型文件。令这些空间被挂载在实例的/root/shared-storage目录下,并且可以被不同的实例共享。用户只需进入文件存储界面,选择上传文件,即可轻松完成数据的导入。这种便捷的设计为项目的启动和管理提供了极大便利。
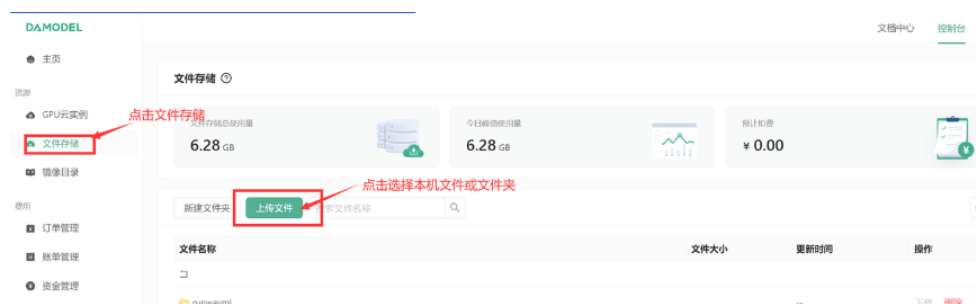
要获取ChatGLM-6B的预训练模型,你可以前往Hugging Face网站进行下载,这个平台提供了简单的操作和丰富的资源。另外,你也可以选择访问魔塔社区,从Chatglm3-6B项目中下载所需的文件,这一方式同样高效且方便。两种途径都能帮助你迅速获取所需模型,为开发工作提供坚实的支持。
需要将下载的模型和配置文件上传并解压。为了确保上传过程的顺利进行,建议将上传界面保持在前台显示。待上传成功后,再继续其他任务。这种操作步骤可以有效减少出错的可能性,同时提升文件管理的效率,让开发过程更加流畅和高效。
4.启动模型
在成功上传并解压预训练模型后,你就可以运行相关的Python脚本了。ChatGLM-6B提供了两个重要的文件:cli_demo.py和web_demo.py,分别用于命令行和网页交互。为了使用本地模型,你需要将代码中的Hugging Face Hub路径替换成本地文件路径。这一步骤能够确保模型在本地环境中顺利运行,为你的项目提供支持和灵活性。
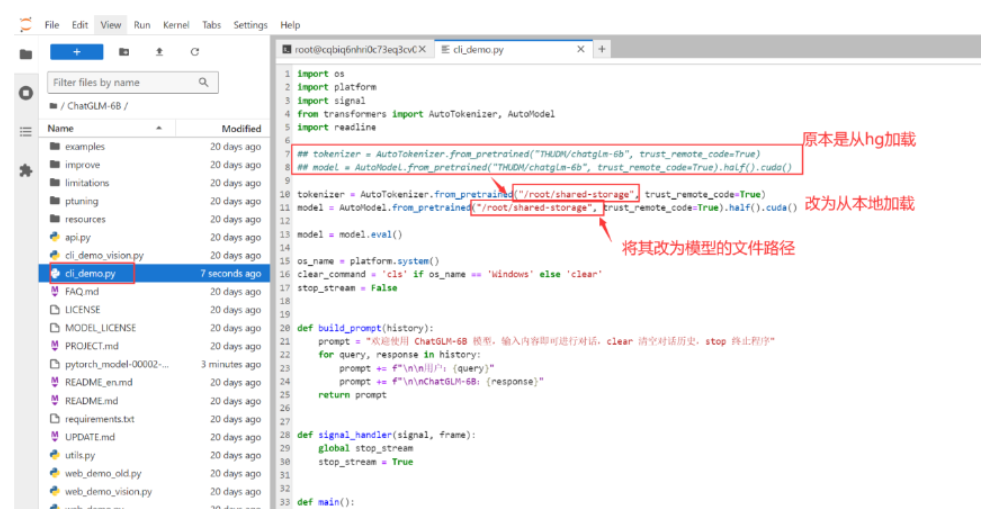
在终端中运行python cli_demo.py命令,即可启动模型。在cli_demo.py中,main函数会进入一个循环状态,等待用户的指令。通过键入文本,用户可以与模型进行交互;输入"clear"可清空当前对话记录并刷新界面,而输入"stop"则可以结束程序。这种设计使用户能够轻松管理对话流程,提供了良好的使用体验。
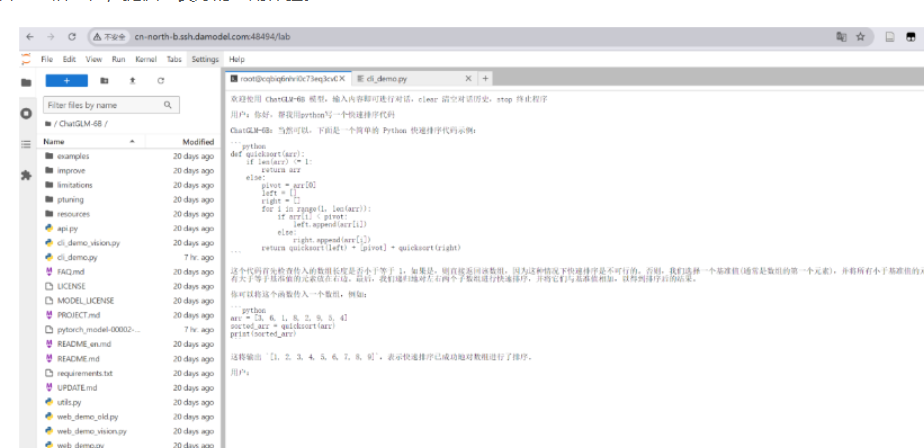
在终端中使用命令python web_demo.py,可以通过网页界面与模型进行交互。
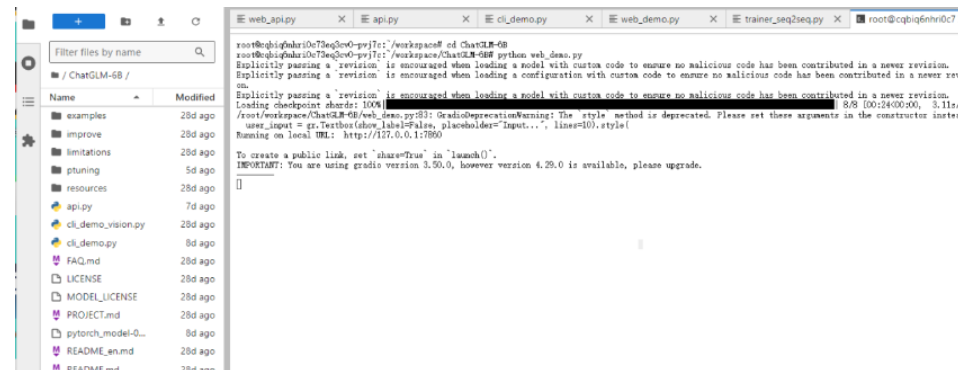
在Jupyter环境中,直接访问127.0.0.1:7860的网页界面可能会有一些限制。你可以通过MobaXterm来创建SSH隧道,解决这个问题并实现远程端口的本地转发。启动MobaXterm后,新建一个SSH会话,输入必要的SSH信息,将远程的7860端口映射到本地端口,然后点击“start”以启用端口转发。这种方式可以轻松地突破访问限制,确保你能够顺利使用远程服务。
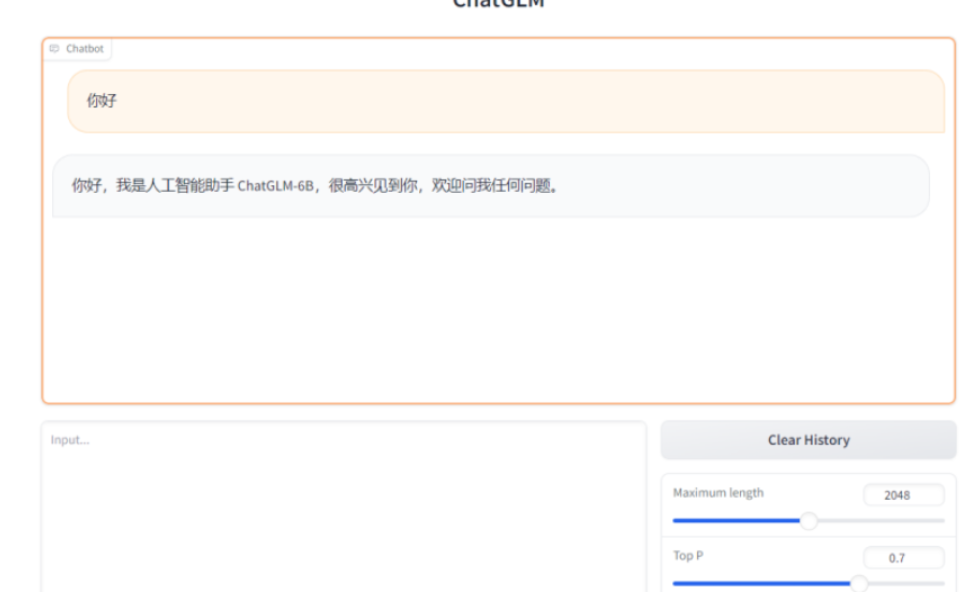
一旦端口转发设置成功,即可通过网页界面与模型进行交互。
邀请人:池央
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号