hhdb数据库介绍(9-19)
原创

Oracle兼容性说明
数据类型兼容
本节主要介绍 HHDB Server与Oracle 数据库中数据类型的详细兼容对比信息。
比较项 | Oracle数据库数据类型 | HHDB Server数据类型对应项/替代项 |
|---|---|---|
字符串/字符 | VARCHAR2( n ) | VARCHAR( n ) |
字符串/字符 | NVARCHAR2( n ) | VARCHAR( n ) character set utf8 |
字符串/字符 | RAW( n ) | VARBINARY( n ),无长度时转为VARBINARY(2000) |
字符串/字符 | LONG RAW | LONGTEXT |
数字 | NUMBER | DECIMAL( p , s ),当NUMBER(p)无精度时根据数据长度转换:[1,3) -> tinyint;[3,5) -> smallint;[5,9) -> int;[9,19) -> bigint;其他 -> decimal |
数字 | NUMBER( * ) | DOUBLE |
数字 | BINARY_FLOAT | BINARY_FLOAT 转为 decimal |
数字 | BINARY_DOUBLE | BINARY_DOUBLE 转为 decimal |
日期 | DATE | DATETIME |
日期 | TIMESTAMP( p ) WITH TIME ZONE | TIMESTAMP |
日期 | TIMESTAMP( p ) WITH LOCAL TIME ZONE | TIMESTAMP |
日期 | INTERVAL YEAR( p ) TO MONTH | 不支持 |
日期 | INTERVAL DAY( p ) TO SECOND( s ) | 不支持 |
XML | XMLTYPE | 根据数据长度转换:0,255 -> TINYTEXT;(255,65535] -> TEXT;(65535,16777215] -> MEDIUMTEXT;其他 -> LONGTEXT |
LOB | BFILE | VARCHAR(255) |
LOB | CLOB | 根据数据长度转换:0,255 -> TINYTEXT;(255,65535] -> TEXT;(65535,16777215] -> MEDIUMTEXT;其他 -> LONGTEXT |
LOB | NCLOB | 根据数据长度转换:0,255 -> TINYTEXT;(255,65535] -> TEXT;(65535,16777215] -> MEDIUMTEXT;其他 -> LONGTEXT |
ROWID | ROWID | 不支持 |
ROWID | UROWID( n ) | 不支持 |
函数兼容
日期函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
ADD_MONTHS | 支持 | |
CURRENT_DATE | 支持 | |
CURRENT_TIMESTAMP | 支持 | |
EXTRACT | 支持 | |
LAST_DAY | 支持 | |
LOCALTIMESTAMP | 支持 | |
MONTHS_BETWEEN | 支持 | |
NEW_TIME | 支持 | |
SYSDATE | 限制支持 | 仅计算节点和存储节点均为8.0版本支持,不支持alter语法中字段默认值为sysdate |
TRUNC(date,fmt) | 限制支持 | 支持fmt格式,不支持多表函数嵌套 |
转换函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
BIN_TO_NUM | 支持 | |
RAWTOHEX | 支持 | |
RAWTONHEX | 支持 | |
TO_BINARY_DOUBLE | 支持 | |
TO_BINARY_FLOAT | 支持 | |
TO_CHAR (bfile | blob) | 支持 | |
TO_CHAR (character) | 支持 | |
TO_CHAR (datetime) | 支持 | 支持格式转化 |
TO_CHAR (number) | 支持 | 详见下方补充说明 |
TO_CLOB | 支持 | |
TO_DATE | 支持 | 详见下方补充说明 |
TO_LOB | 支持 | |
TO_NCHAR (character) | 支持 | |
TO_NCHAR (datetime) | 支持 | |
TO_NCHAR (number) | 支持 | |
TO_NCLOB | 支持 | |
TO_NUMBER | 支持 | |
TO_TIMESTAMP | 支持 | |
WM_CONCAT | 支持 |
补充说明:
TO_CHAR(number):支持TO_CHAR(number, format)对格式进行控制,当前仅支持FM开头的格式控制,其后跟数字(0),数字(9),逗号(,),点(.)四种符号。其中0用于在返回结果最前端和最后端填充。FM表示去掉空格,9表示一位数字,用于控制字符长度,0表示最前端和最后端用0填充,一个0也会占用一个字符长度,逗号,控制在哪个位置出现逗号,点.表示小数点。例如:
select to_char(1234567.78,'FM009,999,999.9990') from dual;
-- 返回结果:001,234,567.780
-- 若实际数字超过格式定义的长度,则会用#号返回格式定义的长度位数。TO_DATE:支持TO_DATE自动对没有天的日期补齐1号数值,与Oracle的行为一致。例如:
#没有天的数值
select to_date('202308','yyyymm') from dual;
-- 返回结果:2023-08-01 00:00:00字符串函数
返回字符值的字符串函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
CHR | 支持 | |
LPAD | 支持 | |
LTRIM | 支持 | |
REGEXP_SUBSTR | 支持 | |
REPLACE | 支持 | |
RPAD | 支持 | |
RTRIM | 支持 | |
SOUNDEX | 支持 | |
SUBSTR | 支持 | |
TRANSLATE…USING | 支持 |
返回数字值的字符串函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
LENGTH | 支持 | |
LENGTHB | 支持 | 等价于LENGTH |
REGEXP_INSTR | 支持 |
数字函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
BITAND | 支持 | |
REMAINDER | 支持 | |
ROUND(number) | 支持 | |
TRUNC(number) | 支持 |
分析函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
CUME_DIST | 支持 | |
DENSE_RANK | 支持 | |
LAG | 支持 | |
LEAD | 支持 | |
LISTAGG | 支持 | |
NTILE | 支持 | |
OVER | 支持 | |
PERCENT_RANK | 支持 |
聚合函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
CUME_DIST | 支持 | |
DENSE_RANK | 支持 | |
GROUPING | 支持 | |
PERCENT_RANK | 支持 | |
XMLAGG | 支持 | |
XMLPARSE | 支持 |
NULL相关函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
NVL | 支持 |
编码/解码函数
Oracle数据库函数 | HHDB Server是否支持 | 备注 |
|---|---|---|
DECODE | 支持 |
环境与标识符函数
Oracle数据库函数 | HHDB Server数据库是否支持 | 备注 |
|---|---|---|
SYS_GUID | 支持 | 仅DDL操作,要求计算节点和存储节点均为8.0及以上版本 |
USERENV | 限制支持 | 仅参数为('language') |
SEQUENCE语法兼容
SEQUENCE 仅所属某个逻辑库下,用广拥有此逻辑库的权限,即可访问到此 SEQUENCE, 与TABLE 数据对象类似。
Oracle数据库SEQUENCE语法 | HHDB Server是否支持 | 备注 | |
|---|---|---|---|
CREATE语法 | create sequence schema. sequence_name { minvalue integer | nominvalue } | { maxvalue integer | nomaxvalue } | { start with integer } | { increment by integer} | { cycle | nocycle } | { order | noorder } | { cache integer | nocache } … ; | 支持 | |
ALTER语法 | alter sequence schema. sequence_name { minvalue integer | nominvalue } | { maxvalue integer | nomaxvalue } | { increment by integer} | { cycle | nocycle } | { order | noorder } | { cache integer | nocache } … ; | 支持 | oracle规定start with的值的修改必须先drop再create; HHDB Server与其保持一致 |
DROP语法 | drop sequence schema. sequence_name ; | 支持 | |
SEQUENCE使用语法及范围 | select schema. sequence_name.currval/nextval from dual ; | 支持 | |
查看所有SEQUENCE | select * from user_sequences/all_sequences ; | 支持 | user_sequences需要有对应逻辑库的SELECT权限 |
select* from all_sequences | 支持 | 需要有全局的SELECT 权限才可以执行 | |
在DDL语句中使用SEQUENCE | <\column> default <\sequence>.NEXTVAL | 支持 | 仅支持<序列>.NEXTVAL,暂不支持<序列>.CURRVAL |
在DML语句中使用SEQUENCE | insert into table_name(column_name) values( schema. sequence_name.currval/nextval); | 支持 | 支持INSERT/SELECT/UPDATE中使用 |
select * from table_name; | 支持 | ||
update table_name set table_name.column_name = schema. sequence_name.currval/nextval where …; | 支持 | ||
delete from table_name where table_name.column_name = schema. sequence_name.currval/nextval; | 不支持 | 不支持delete中使用 |
注意 序列的SCHEMA级别对应的是逻辑库,非用户级别,与TABLE类似。
同义词兼容
计算节点兼容Oracle同义词功能。使用此功能需开启Oracle语法解析,仅当数据库用户开启了“该用户执行SQL时是否按Oracle语法优先解析”开关,或打开参数“enableOracleFunction”才支持此同义词语法的功能。
Oracle数据库同义词语法 | HHDB Server数据库是否支持 | 备注 | |
|---|---|---|---|
CREATE语法 | CREATE OR REPLACEPUBLIC SYNONYMschema. synonymSHARING={METADATA|NONE} FOR schema. object @dblink ; | 支持 | 具体使用方法见下文 |
ALTER语法 | ALTER PUBLIC SYNONYM schema. synonym {EDITIONABLE| NONEDITIONABLE|COMPILE}; | 支持 | 具体使用方法见下文 |
DROP语法 | DROP PUBLIC SYNONYM schema. synonym FORCE; | 支持 | 具体使用方法见下文 |
- 创建同义词
创建同义词语法
CREATE [ OR REPLACE ] [ PUBLIC ] SYNONYM
[ database1. ] synonym
FOR [ database2.] object [ @ dblink ] ;语法说明
- CREATE SYNONYM:表示创建新的同义词;
- OR REPLACE:选填;若同义词已存在,则替换现有同义词;
- PUBLIC:选填;填写代表创建公有同义词,意思为所有用户均可直接使用此同义词;未填写代表私有,表示仅当前用户可使用;
- database1.:选填;指定在某个逻辑库下创建同义词;若不填写,则默认在当前所在逻辑库下创建同义词;若创建公有同义词,则无需指定该逻辑库;
- synonym:创建的同义词名称;
- FOR object:指定同义词引用的具体对象,该对象支持表、视图、同义词、序列;若支持对象不存在时创建同义词,则此对象被创建时会自动关联;同义词名最大长度限制为128字符;
- database2. :选填;指定引用某个逻辑库下对象;若不填写,则默认选择当前逻辑库下的对象;若指定对象为同义词,则对应该同义词指向的对象;
- @dblink:引用的对象支持对外部数据库创建同义词,此处填写DBLINK名。DBLINK功能说明请参考DBLINK章节
语法示例
- 不指定同义词所有库,也不指定表所在库
CREATE SYNONYM building FOR locations;
--为当前逻辑库下创建名为building的同义词,指向当前逻辑库下的locations表
mysql> create synonym building for locations;
Query OK, 0 rows affected (0.02 sec)- 指定同义词所有库,不指定表所在库
CREATE SYNONYM testdatabase.people FOR customer;
-- 在testdatabase逻辑库下创建名为people的同义词,指向当前逻辑库下的customer表
mysql> create synonym testdatabase.people for customer;
Query OK, 0 rows affected (0.02 sec)- 不指定同义词所有库,指定表所在库
CREATE SYNONYM emp FOR testdatabase.employees;
--在当前逻辑库下创建名为emp的同义词,指向testdatabase逻辑库下的employees表
mysql> create synonym emp for testdatabase.employees;
Query OK, 0 rows affected (0.02 sec)- 指向DBLINK
CREATE PUBLIC SYNONYM rest FOR customer@link001;
-- 创建名为rst的公有同义词,指向名为link001的dblink链接下的customer表
mysql> create public synonym rest for customer@link001;
Query OK, 0 rows affected (0.04 sec)- 指向同义词
CREATE SYNONYM children FOR testdatabase.teenager;
-- 创建名为children的同义词,指向归属于testdatabase库的同义词teenager。teenager同义词指向表people,则查询children实际返回结果是people表的结果。
mysql> create synonym children for testdatabase.teenager;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from children;
+--+--------------+--------+----+-------------+
| id | first_name | last_name | age | gender |
+--+--------------+--------+----+-------------+
| 1 | Mike | Smith | 12 | male |
| 2 | Lilian | Swift | 10 | female |
| 3 | Jennie | Watson | 11 | female |
| 4 | Erick | Lee | 10 | male |
+--+--------------+---------+---+-------------+
4 rows in set (0.02 sec)注意事项
- 若在某逻辑库内创建一个私有同义词,必须对此逻辑库(database1.)具有CREATE权限;
- 若创建一个公有同义词,必须具有全局的CREATE权限;
- 公有与私有同义词可重名,但不允许创建重名的公有同义词,且不允许在同一个逻辑库内创建重名的私有同义词;
- 可为同一个对象创建多个不同的同义词名;
- 同义词在创建后,不允许再修改其引用对象,只能通过删除再新建去完成。
- 使用同义词
支持对同义词使用DML语句,限于SELECT、INSERT、UPDATE、DELETE。具体使用方法同表DML操作方式一致,需注意以下事项:
- 使用时需要对同义词所指向的对象具有相应的权限;
- 若存在如下同名同义词对象(表、视图、同义词),遵循以下优先级:表>视图>私有同义词>公有同义词;
- 若存在如下同名同义词对象(序列、同义词),遵循以下优先级:序列>私有同义词>公有同义词
- 若同义词指向的表/视图等对象执行了ALTER/TRUNCATE操作,则此同义词会同步该变化;
- 若同义词指向的表/视图/序列/同义词对象执行了DROP或者RENAME操作,则此同义词依旧- 指向原来的链接对象,若要新建对应关系则需删除再新建同义词。
- 修改同义词
修改同义词语法
ALTER [ PUBLIC ] SYNONYM [ database. ] synonym COMPILE;语法说明:
Oracle中当同义词对应的对象发生变化(如修改了表结构),该同义词会因为对象的改变而失效无法使用,变为INVALID状态。此时需要执行上述语句将同义词状态变为VALID,才能正常查询调用。
注意 计算节点支持此语句的执行通过作为Oracle的语法兼容,但是无实际意义。因为当表结构变更时,计算节点会自动变更新的表结构同步至同义词,无VALID和INVALID状态,用户无需重新编译该对象即可获取最新的数据。
注意事项
- 执行该语句时需要有对应的权限,必须对私有同义词所在的逻辑库具有ALTER权限,必须对公有同义词拥有全局的ALTER权限;
- 若不填写database.则默认在当前逻辑库下执行该语句;对于公有同义词,则无需填写该项。
- 删除同义词
删除同义词语法
DROP [PUBLIC] SYNONYM [ database. ] synonym [FORCE] ;语法说明:
database.:指定同义词所在的逻辑库。在不填写的情况下,默认是在当前在的逻辑库下DROP同义词;对于公有同义词,则无需填写该项。 FORCE:指定强制删除同义词,即使其具有依赖表或用户定义的类型。此处填写或不填写FORCE均无意义,仅作为对Oracle的语法兼容。
语法示例:
DROP SYNONYM emp;
-- 删除当前逻辑库下的同义词emp
mysql> drop synonym emp;
Query OK, 0 rows affected (0.02 sec)
DROP SYNONYM testdatabase.people;
-- 删除逻辑库testdatabaset下的同义词people
mysql> drop testdatabase.people;
Query OK, 0 rows affected (0.02 sec)注意事项:
执行该语句时需要有对应的权限,必须对私有同义词所在的逻辑库具有DROP权限,必须对公有同义词拥有全局的DROP权限。
- 查看同义词
查看同义词语法:
可使用以下语句查看已创建的同义词信息:
SHOW SYNONYMS;语法示例:
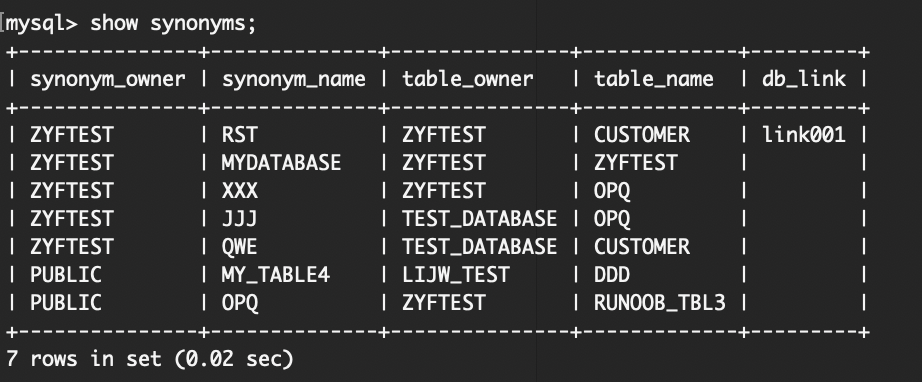
- synonym_owner:指同义词所属的逻辑库
- synonym_name:指创建的同义词名
- table_owner:指同义词指向的对象所属的逻辑库
- table_name:指同义词指向的对象
- db_link:指同义词指向对象所属的DBLINK
注意事项:
- 当未指定逻辑库时,显示所有的公有同义词;
- 当指定逻辑库时,除了展示所有的公有同义词外,还显示当前逻辑库下所有的私有同义词
特殊语法兼容
Oracle数据库特殊语法 | HHDB Server是否支持 | 备注 |
|---|---|---|
MERGE INTO | 支持 | |
START WITH and CONNECT BY | 支持 | |
||双管道符号 :mysql同名符号,识别 | 支持 | |
(+)操作符进行表关联JOIN | 支持 | |
COMMENT ON | 支持 | 仅支持表、表列、视图、视图列 |
GROUP BY | 支持 | GROUP BY 和 CUBE结合使用(包括多字段使用CUBE分组,以及部分字段GROUP BY分组,部分字段CUBE) |
GROUPING | 支持 | GROUPING 和 GROUP BY ... WITH ROLLUP 、HAVING 结合 |
INSERT ALL ... | 支持 | |
INSERT FIRST ... | 支持 | |
BEGIN ... END | 支持 | 仅支持INSERT、DELETE、UPDATE,整个代码块作为一个包发送,禁用其他的写法,包括SELECT和定义变量等操 |
<> | 支持 | 不等于的对比符号,同时支持符号间存在同一个空格的输入 |

BIT_AND_AGG | COVAR_POP | PERCENTILE_CONT | SKEWNESS_SAMP |
|---|---|---|---|
BIT_OR_AGG | COVAR_SAMP | PERCENTILE_DISC | STDDEV |
BIT_XOR_AGG | FEATURE_DETAILS | PREDICTION | STDDEV_SAMP |
CLUSTER_DETAILS | FEATURE_ID | PREDICTION_COST | STDDEV_POP |
CLUSTER_DISTANCE | FEATURE_SET | PREDICTION_DETAILS | VAR_POP |
CLUSTER_ID | FEATURE_VALUE | PREDICTION_PROBABILITY | VAR_SAMP |
CLUSTER_PROBABILITY | FIRST | PREDICTION_SET | VARIANCE |
CLUSTER_SET | KURTOSIS_POP | RATIO_TO_REPORT | |
CORR | KURTOSIS_SAMP | REGR_ (Linear Regression) Functions | |
CHECKSUM | LAST | SKEWNESS_POP |
- GROUPING函数:不支持GROUPING函数与聚合函数出现在同一个表达式中。
- DATE数据类型(date):考虑到DATE在Oracle和MySQL模式下的含义不一样,由于257的开关粒度较粗,而259做了用户级别的开关,因此DATE自动转换为DATETIME的逻辑在259版本上进行处理,此前的版本不进行自动转换以兼容DATE和DATETIME两种数据类型。
- DATE数据类型(number):不支持负数。
INFORMATION_SCHEMA
INFORMATION_SCHEMA库提供当前计算节点的信息与数据,例如数据库名称、表名称、某列的数据类型等。
此章节列出计算节点支持的INFORMATION_SCHEMA中的表与其特殊处理内容如下:
表名称 | 特殊处理 |
|---|---|
character_sets | 仅返回计算节点支持的字符集与校对集数据 |
collations | 仅返回计算节点支持的字符集与校对集数据 |
collation_character_set_applicability | 仅返回计算节点支持的字符集与校对集数据 |
columns | 返回逻辑库中表的列信息 |
column_privileges | 返回空集 |
engines | 仅返回innodb |
events | 返回空集 |
files | 返回空集 |
global_status | 与SHOW GLOBAL STATUS结果相同 |
global_variables | 与SHOW GLOBAL VARIABLES结果相同 |
hotdb_tableinfo | 与SHOW HOTDB TABLES LIKE 'xx'结果相同,可以批量查询表分片信息 |
innodb_buffer_page | 返回空集 |
innodb_buffer_page_lru | 返回空集 |
innodb_buffer_pool_stats | 返回空集 |
innodb_cmp | 返回空集 |
innodb_cmpmem | 返回空集 |
innodb_cmpmem_reset | 返回空集 |
innodb_cmp_per_index | 返回空集 |
innodb_cmp_per_index_reset | 返回空集 |
innodb_cmp_reset | 返回空集 |
innodb_ft_being_deleted | 返回空集 |
innodb_ft_config | 返回空集 |
innodb_ft_default_stopword | 返回空集 |
innodb_ft_deleted | 返回空集 |
innodb_ft_index_cache | 返回空集 |
innodb_ft_index_table | 返回空集 |
innodb_locks | 返回空集 |
innodb_lock_waits | 返回空集 |
innodb_metrics | 返回空集 |
innodb_sys_columns | 返回空集 |
innodb_sys_datafiles | 返回空集 |
innodb_sys_fields | 返回空集 |
innodb_sys_foreign | 返回空集 |
innodb_sys_foreign_cols | 返回空集 |
innodb_sys_indexes | 返回空集 |
innodb_sys_tables | 返回空集 |
innodb_sys_tablespaces | 返回空集 |
innodb_sys_tablestats | 返回空集 |
innodb_trx | 返回当前执行每个事务的事务详情 |
key_column_usage | 返回索引的约束信息。 |
optimizer_trace | 返回空集 |
parameters | 返回空集 |
partitions | 返回逻辑库中表的分区信息,可支持对该表进行排序、分组查询。 |
plugins | 返回空集 |
processlist | 返回的结果与服务端命令show processlist一致 |
profiling | 返回空集 |
referential_constraints | 返回逻辑库中表的外键信息 |
routines | 返回空集 |
schemata | 返回逻辑库相关信息 |
schema_privileges | 返回空集 |
session_status | 与SHOW SESSION STATUS结果相同 |
session_variables | 与SHOW SESSION VARIABLES结果相同 |
statistics | 返回逻辑库中表的索引统计信息 |
tables | 返回逻辑库中表信息 |
tablespaces | 返回空集 |
table_constraints | 返回逻辑库中表的约束信息 |
table_privileges | 返回空集 |
triggers | 返回空集 |
user_privileges | 返回计算节点中所有的数据库用户权限信息,TABLE_CATALOG字段固定值为def, GRANTEE字段值与SUPER权限有关,如果是含有SUPER权限的数据库用户, IS_GRANTABLE字段返回值为YES且包含REPLICATION SLAVE,REPLICATION CLIENT权限。 |
views | 返回已创建的视图信息 |
hotdb_global_variables | 返回计算节点参数信息 |
为兼容版本高于8.0的存储节点,对于8.0新增的表做如下特殊处理:
表名称 | 特殊处理 |
|---|---|
check_constraints | 返回CHECK约束信息 |
column_statistics | 返回索引的直方图统计信息 |
keywords | 返回空集 |
resource_groups | 返回空集 |
st_geometry_columns | 返回逻辑库中表的空间列信息 |
st_spatial_reference_systems | 不做特殊处理 |
st_units_of_measure | 不做特殊处理 |
view_table_usage | 返回空集 |
view_routine_usage | 返回空集 |
为方便运维统计,同步支持以下语法类型:
查询语法 | 举例说明 |
|---|---|
join关联查询 |  |
group by |  |
聚合函数 |  |
case when |  |
order by |  |
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号