不同表格式如何表示规范文件集?

不同表格式如何表示规范文件集?

ApacheHudi
发布于 2024-11-23 13:01:16
发布于 2024-11-23 13:01:16
术语
- • Copy-on-write (COW)是写时复制的
- • Merge-on-read (MOR)是读时合并的
表格式如何表示数据和删除文件的规范列表?
所有表格式都在元数据文件中存储对一组规范数据和删除数据集的引用。每种表格格式采用的方法略有不同,但大致可以将它们分为两类:
- • 增量日志方法(Hudi 和 Delta Lake)
- • 快照日志方法(Iceberg 和 Paimon)
增量日志方法
增量日志方法包括将新更改写入日志条目,这些日志条目仅引用已更改的内容,例如添加和删除的文件、对架构的更改等。
- • Delta Lake 将日志称为 Delta Log (增量日志),并将每个条目称为 Delta Entry (增量条目)。
- • Apache Hudi 将日志称为 Timeline,并将每个条目称为 Instant。
Delta Lake
增量日志包含以 JSON 文件形式排列的日志条目序列。 每个日志条目都是一个特定的操作,例如:
- • 更改元数据
- • 添加和移除文件
- • 添加 CDC 文件
- • 以及更多
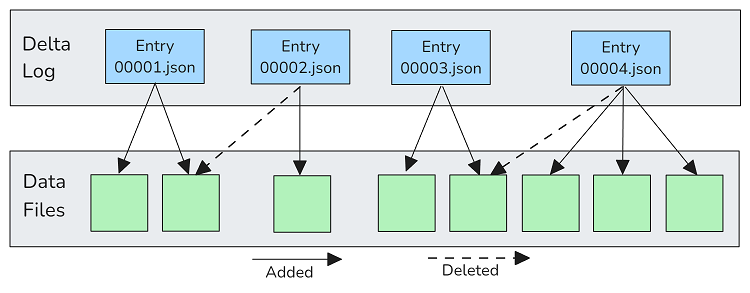
图 1.描述具有一组四个“添加/删除文件”操作的增量日志。
每个 Delta Log 条目及其 log-prefix 都表示该时间点的表。写入操作会生成一个 “Add/Remove Files” 日志条目,其中包含一组已添加的文件和一组已逻辑删除的文件。要了解规范文件集,读取器会读取所有日志条目,直到与它希望读取的 table 版本相对应的条目,并将其汇总到该表的单个逻辑快照中。Delta Lake 通过定期将检查点(Parquet 文件)写入日志,该检查点包含该时间点元数据的汇总快照(包括所有实时数据和删除矢量文件),从而保持较低的日志读取过程的成本。

图 2.表扫描只需要读取日志的三个元数据文件:00005.checkpoint.parquet、00006.json 和 00007.json。
通过读取最新的检查点,然后向前读取以创建逻辑快照来读取快照。
Delta Lake 在表示规范文件集上非常简单。
Apache Hudi
Apache Hudi 需要比其他格式使用更多的图表和文字来描述它。
规范文件集由两个组件表示:
- • 时间线 (deltas 的日志)。
- • 元数据表,它充当 Hudi 表的文件索引。
Hudi 元数据表包含构成 Hudi 表的所有已提交数据文件的列表。每个表提交都会写入时间线和元数据表。已提交数据文件的列表可以与时间线结合使用,以返回存储在时间线中的任何给定表版本的文件集。
另外需要介绍 Hudi 如何在文件之间分发数据以及时间线的工作原理。
文件组、文件切片、基本文件和日志文件
一个 Hudi 表分为许多文件组,文件组的一种思考方式是它们充当一种存储分片机制。主键映射到这些分片,并且该映射存储在索引中。

图 3.一个表分为多个文件组。
这些文件组的数量可以是固定的,也可以动态增加。
文件组由一个或多个文件切片组成,文件切片由单个基本文件(Parquet 文件)和多个日志文件(也是 Parquet 文件,也可以是 Avro)组成。日志文件写入 MOR 表中,并包含增量 (新行和删除向量)。对于 COW 表,文件切片只是一个基本文件。
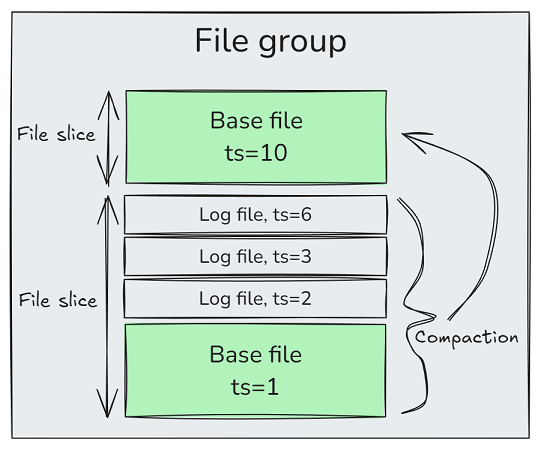
图4. 时间戳在 Hudi 中起着至关重要的作用,要了解这部分需要讨论时间线。
时间线
每个写入操作都会经历一个将一系列 instant 写入时间线的过程,操作状态如下:
- 1. Requested
- 2. Inflight
- 3. Completed
有多种操作类型,例如:
- • Commit (copy-on-write操作)
- • DeltaCommit (merge-on-read 操作)
- • Compaction
- • Clean
- • 以及更多
每个时刻都会写入时间线,其名称由以下组成:
- • 即时时间戳
- • 操作
- • 操作状态
Commit 和 DeltaCommit 操作的已完成 时刻包含已添加的文件列表。数据文件可以是基本文件或日志文件。
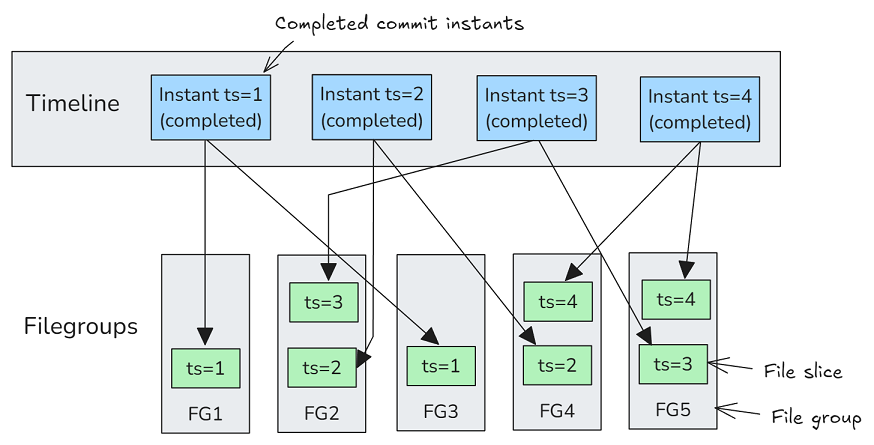
图 5.COW 表的 Apache Hudi 时间线。描述了一个包含 5 个文件组和已完成提交时刻日志的表,其中每个时刻都列出了一组添加的文件切片。此处省略了 requested 和 inflight 时刻。
Apache Hudi 时间线Commit和DeltaCommit时刻仅列出已添加的文件,没有已删除的文件,这使其与其他表格式区分开来。
文件切片(甚至文件切片中的日志文件)是根据时间戳过滤掉的,而不是使用显式的逻辑删除机制。在 Iceberg 和 Delta Lake 中,COW 操作将加载数据文件,执行一些行级更改,并将其写回为新的数据文件。然后,该操作会将新文件注册为已添加文件,并将原始文件注册为逻辑删除文件。同样对 COW 和 MOR 表执行压缩操作将导致逻辑删除。在 Hudi 中,时间线不包含任何逻辑删除的文件,因为时间戳决定了在表扫描中从每个文件组中读取哪些基本文件和日志文件。
例如:
- 1. 写入器将 ts=1 处的 file-slice-1.parquet 写入 file-group-1。它通过添加引用 file-slice-1.parquet 的 ts=1 的已完成提交即时来提交操作。
- 2. 接下来,写入器想要从 file-slice-1.parquet 中删除一行,因此它加载文件切片,删除该行,并将其写回为 ts=2 的 file-slice-2.parquet。它通过添加引用 file-slice-2.parquet 的 ts=2 的已完成提交即时来提交操作。
当读取器在 ts=1 处执行表扫描时,对于文件组 1,它将读取 file-slice-1.parquet,因为其时间戳小于或等于扫描的时间戳。ts=2 处的表扫描将读取 file-slice-2.parquet,因为它是具有小于或等于扫描时间戳的最高时间戳的文件切片。这样就不需要对文件进行显式的逻辑删除。
最后Hudi 客户端如何表示规范文件集
Hudi 客户端有两种方法可以发现组成表的文件切片:
- 1. 如果客户端只想知道最新表版本的文件切片(在 Hudi 中称为快照查询),则只需读取包含所有已提交文件切片信息的 Hudi 元数据表。它只需要获取具有最高时间戳的每个文件组的文件切片。
- 2. 如果客户端希望了解先前表版本的文件切片(称为时间旅行查询),它会执行相同的元数据表读取过程,不同之处在于它根据该表版本的最后提交时刻的提交时间戳筛选出文件切片和文件切片中的日志文件。该信息来自时间线。
时间线不是最新表版本的规范文件集的源,但在时间旅行查询中进行筛选时需要它。
Hudi 通过时间轴存档过程防止活动时间轴的大小变得太大。这会通过将较旧的 Instants 移动到已存档的时间轴来在活动时间轴中保留一定数量的已完成 Instant。存档的时间线不由常规操作引用,但出于其他目的作为表的历史记录存在。
时间线存档不会影响客户端读取最新表版本的文件切片的能力,它只是限制了时间旅行和增量查询可以追溯多远。只有时间线具有文件更改的历史记录,元数据表充当当前快照。
快照日志方法
快照日志方法涉及在每次提交时写入元数据文件的新树(快照)。特定表版本的根节点是快照或指向该快照的其他元数据文件。读取器了解快照(对于它希望读取的表版本)并浏览子节点以发现规范文件集。使用增量日志方法,新提交只会添加 delta,读取器必须汇总 deltas 日志才能创建逻辑快照。使用快照日志方法,这个汇总到快照的过程已经在写入阶段完成。
Apache Iceberg
Iceberg 存储快照日志,每个快照代表一个时间点(表版本)。
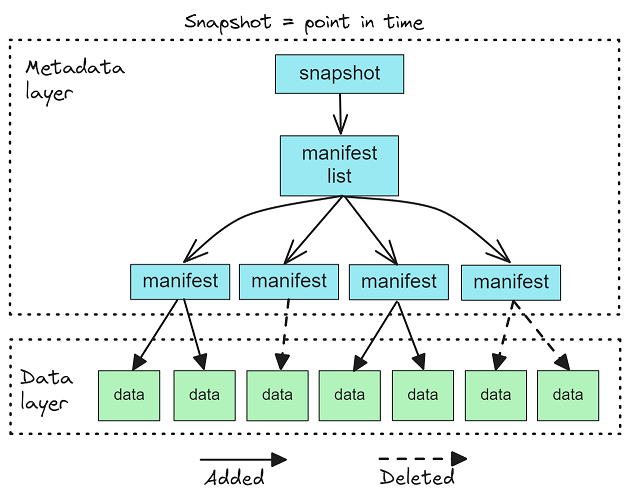
图 6.每个表版本都存储为快照。快照包含一个清单列表文件,该文件包含指向一组清单文件的条目列表。每个清单文件都包含一个条目列表,这些条目指向一组已添加、已删除或已存在的数据文件。
每次提交都会写入一个新的元数据文件,用于存储快照日志(新快照附加到末尾)和有关架构的信息。Iceberg 目录包含当前元数据文件的路径。
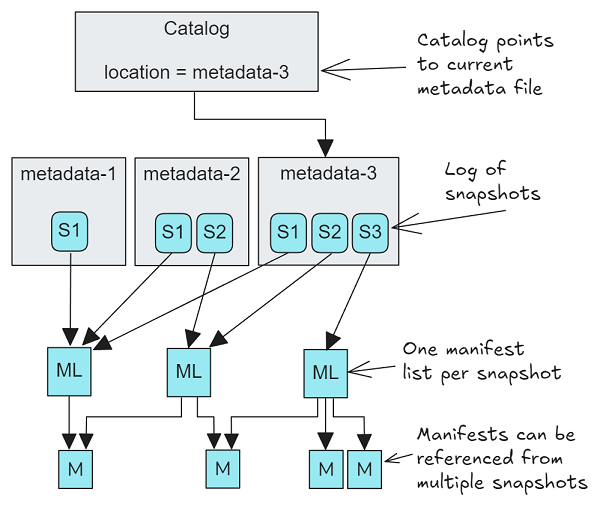
图 7.Iceberg 客户端将首先查阅目录以了解当前的元数据文件。然后它会加载包含所有实时快照的元数据文件。
元数据文件本身不构成可读取的日志。相反,当前元数据文件包含实时快照的日志(每个表版本一个)。读取器可以基于这些快照中的任何一个执行读取;对于普通查询,通常会读取当前(最新的)快照,但对于按时间顺序查看的查询,可以读取较旧的快照。
expireSnapshots 操作根据快照的存在时间删除快照,从而防止快照日志增长过大。
Apache Paimon
Paimon 元数据与 Iceberg 有一些相似之处,但不使用 catalog 来指向具有最新快照的元数据文件。相反它会像 Delta Lake 一样对快照进行编号,然后 Paimon 客户端可以通过列出和排序快照文件来确定当前快照。

图 8.Snapshot-4 是当前快照。
每个快照都是类似于 Iceberg 的树,只是 Paimon 快照有两个 manifest-list 文件:
- • Base manifest list(基本清单列表):表示操作开始时的表的文件树。
- • Delta manifest list:列出此操作中写入和逻辑删除的数据文件的清单文件。
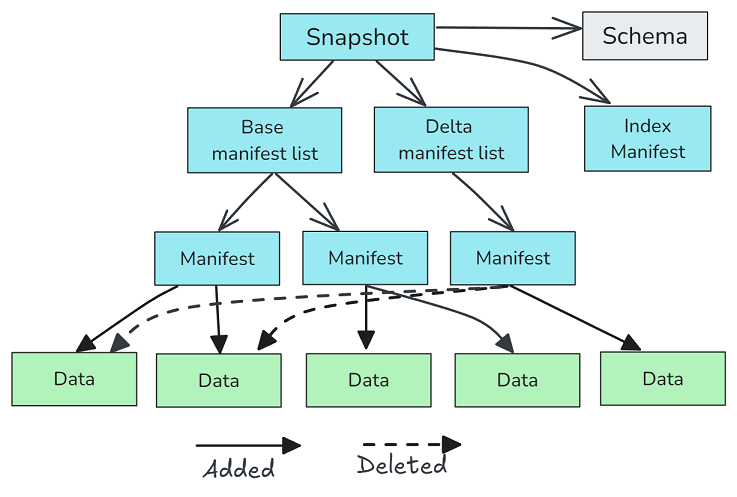
图 9.描述由压缩操作写入的快照,该操作删除了两个现有数据文件并将其重写为单个数据文件。
Paimon 快照将表分为不同的 manifest 文件,manifest 文件是操作开始时存在的 manifest 文件,以及列出操作添加或逻辑删除的数据或删除向量文件的 manifest 文件。常规写入不会在逻辑上删除文件,因为常规写入中的所有删除都只是 0 级数据文件(LSM 树的 0 级)中的行级删除。但是压缩作业会在逻辑上删除文件。
快照保留配置可防止快照日志增长过大。通常在写入操作期间会同步删除早于保留期的快照。
结论
虽然每种表格式以不同的方式表示规范的数据集和删除文件,但它们都具有以下特征:
- • 每个表提交都会生成一个新的表版本,查询可以选择从特定版本读取(时间旅行)。
- • 不可变的版本控制元数据指向不可变的数据文件。创建表版本后,不会更改其任何元数据或数据文件。最终,旧版本会通过删除其关联的元数据并物理删除数据和删除文件而过期。
- • 元数据版本存储为增量日志或快照日志。
- • 增量日志维护某种最新快照,快照日志包含生成它们的增量的每个快照中的信息:
- • Delta Lake 会定期将检查点写入日志,该检查点汇总所有增量以将快照制作为 Parquet 文件。
- • Hudi 在元数据表中维护当前快照。
- • Iceberg 和 Paimon 使用快照日志,但会注册每个快照中所做的更改。
原文链接:https://jack-vanlightly.com/blog/2024/8/7/table-format-comparisons-how-do-the-table-formats-represent-the-canonical-set-of-files
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-11-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号