【探索数据结构】线性表之单链表
原创

好事发生
mall :hutool项目源码解析 作者:忆遂愿
https://cloud.tencent.com/developer/article/2466055?shareByChannel=link
文章通过实际项目需求引导对 Hutool 的学习,在工具类介绍环节,依据不同工具类在控制层接口的应用以及控制台打印信息进行讲解,同时紧密关联官方开发文档,为读者自主深入研究提供了清晰的指引路径,非常有帮助。
前言
回顾:线性表之顺序表 顺序表的问题及思考 1.中间/头部的插入删除,时间复杂度为0(N) 2.增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。 3.增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。 思考:如何解决以上问题呢? 是否存在一种数据结构,能够解决以上顺序表表现出来的问题: 1)中间/头部的插入删除,可以一步到位,不需要挪动数据 2)不需要扩容 3)不会造成空间 答案是本篇主角——(单)链表
文章重点介绍:不带头节点不循环的单链表
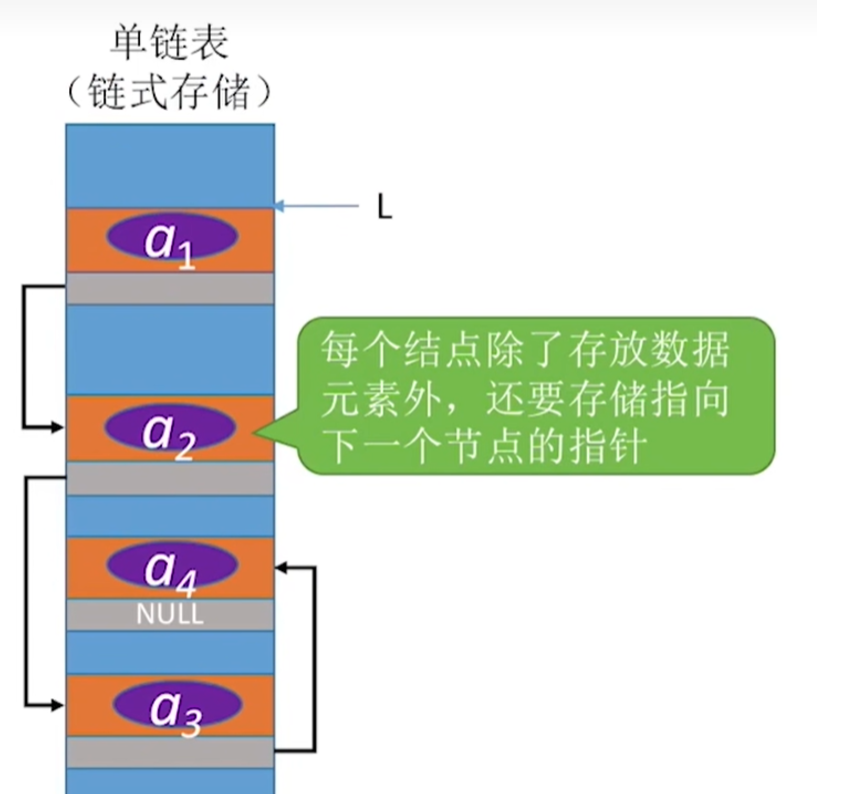
一、链表
链表是一种物理存储单元上非连续、非顺序的存储结构,其数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点组成,每个结点都包含两个部分:数据域和指针域。数据域用于存储数据元素的信息,而指针域则存储着指向下一个结点的地址信息。有单链表、双链表、循环链表 优点:动态内存分配、插入和删除高效、空间利用率高 缺点:访问元素效率低、有额外的空间开销、缓存不优好
二、单链表
1.概念
单链表是一种线性数据结构,其中元素在逻辑上按照线性顺序排列,但在物理内存中通过指针进行链接。每个元素(称为节点/结点)都包含两部分信息:数据域和指针域。数据域存储节点的值或数据,而指针域则包含指向下一个节点的指针。
2.分类
(1)带头节点 在单链表中,第一个节点之前通常有一个头指针(或称为头节点),它指向链表中的第一个数据节点。如果链表为空,则头指针通常指向空(NULL)。链表的最后一个节点的指针域被设置为空(NULL),以表示链表的结束。 (2)不带头节点 不带头节点的单链表,我们直接通过头指针指向第一个数据节点,而不需要额外的头节点作为起始点。
3.代码示例
创建单链表结构
typedef int SLTDataType;
typedef struct SListNode SLTNode;
struct SListNode
{
SLTDataType data;//节点存放的数据
SLTNode* next;//存放下一个节点的地址
};三、对单链表的操作
(0)打印
//打印
void SLTPrint(SLTNode* phead)
{
//创建指向第一个节点的指针的指针,让phead无需改变
SLTNode* pcur = phead;
while (pcur)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}(1)创建一个新节点
//创建一个新节点
SLTNode* SLTBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(1);//申请空间成功会返回0
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}(2)尾插
有链表为空和非空两种情况
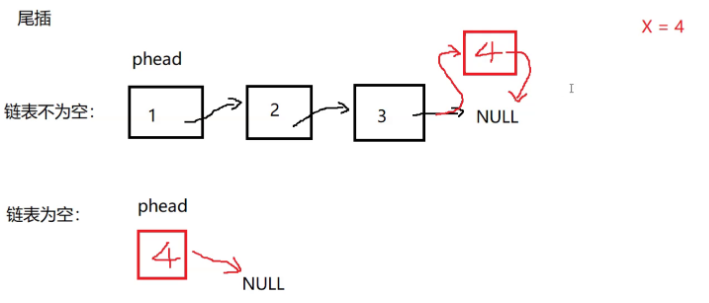
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
//*pphead是指向第一个节点的指针, 存放第一个节点的地址
//创建一个新节点
SLTNode* newnode = SLTBuyNode(x);
//空链表
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{//非空链表,找尾
//创建指向第一个节点的指针的指针,让*phead无需改变
SLTNode * ptail = *pphead;
while (ptail->next)
{
ptail = ptail->next;
}
//新节点变为链表的新尾巴
ptail->next = newnode;
}
}思考:为什么要用二级指针来接收实参?

简单来说,想要改变实参,传值无法改变,要通过传实参的地址给形参,形参的改变才会影响实参
(3)头插
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
//*pphead是指向第一个节点的指针, 存放第一个节点的地址
//创建一个新节点
SLTNode* newnode = SLTBuyNode(x);
newnode->next = *pphead;
*pphead = newnode;
}(4)头删
//头删
void SLTDelFront(SLTNode** pphead)
{
assert(pphead && *pphead);//链表不能为空
//无论有几个节点都适用
SLTNode* next = (*pphead)->next;//保存第二个节点的地址
free(*pphead);
*pphead = NULL;
*pphead = next;//原本的第二个节点成为新头结点
}(5)尾删
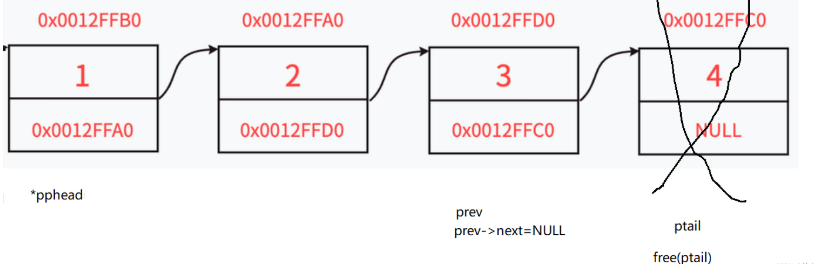
//尾删
void SLTDelBack(SLTNode** pphead)
{
//可能会修改头节点地址所以还是使用二级指针
assert(pphead && *pphead);//链表不能为空
//链表只有一个节点
if ((*pphead)->next == NULL)//->优先级高于*
{
free(*pphead);
*pphead = NULL;
}
//多个节点
SLTNode* ptail = *pphead;
SLTNode* prev = *pphead;
while (ptail->next)
{
prev = ptail;
ptail = ptail->next;
}
prev->next = NULL;
free(ptail);
ptail = NULL;
}(6)指定位置之后插入
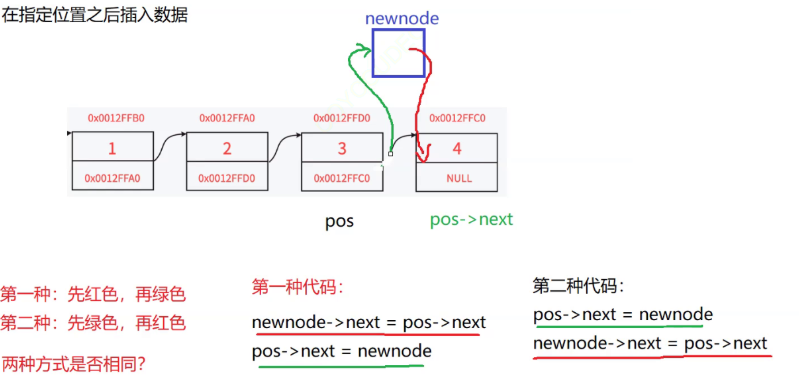
不相同,不可以互换位置,第二中代码pos->next指针先指向了newnode那么原先pos的下一个节点的地址就会找不到
//指定位置之后插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
//为什么不需要头结点,因为在指定位置插入是这样的逻辑
//pos-newnode-pos->next,通过pos我们就能找到他的下一个节点
assert(pos);
//创建一个新节点
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
//思考:上面两行代码顺序互换可以吗?
}(7)删除指定节点之后的数据
// 删除指定节点pos之后的数据
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
//如果没有用del来存放pos->next会怎么样?
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}(8)销毁
一个一个销毁
//销毁
void SLTDestroy(SLTNode** pphead)
{
assert(pphead && *pphead);//链表不能为空
SLTNode* pcur = *pphead;
while (pcur)
{
//如果没有保存pcur->next的地址
// 在pcur释放掉后,剩余节点找不到了,无法销毁
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号