探索基于 Hadoop 的分布式文件处理系统
原创
探索基于 Hadoop 的分布式文件处理系统
原创
一杯茶Ja
发布于 2024-11-18 22:10:42
发布于 2024-11-18 22:10:42
开始之前,引用一篇《Go语言学习12-数据的使用》,该文章详细讲解了 Go 语言数据使用,涵盖赋值语句、常量与变量(含声明、特性等)、数据可比性与有序性,以及类型恒等判断规则,还提到后续将介绍类型转换和内建函数等内容,有需要的朋友可以了解了解!
一、引言
在当今大数据时代,处理大规模数据文件已成为众多领域面临的关键挑战。Hadoop 作为一种强大的分布式计算框架,为解决此类问题提供了高效且可靠的方案。本文将详细阐述基于 Hadoop 的分布式文件处理系统的设计与实现,该系统旨在处理大规模数据文件,并将处理结果存储回 HDFS(Hadoop 分布式文件系统)。
二、系统架构设计
(一)整体架构
本分布式文件处理系统采用经典的 Hadoop 架构模式,主要由客户端、Hadoop 集群(包括 HDFS 和 MapReduce 组件)以及处理结果存储模块构成。客户端负责提交文件处理任务请求,Hadoop 集群承担文件的分布式读取、处理任务,处理结果存储模块将最终结果存储回 HDFS。
(二)模块功能
- 客户端模块 提供用户交互界面,用于上传待处理的大规模数据文件至 HDFS 指定目录。 允许用户指定文件处理任务的相关参数,如数据格式、处理逻辑等。 提交 MapReduce 任务至 Hadoop 集群,并监控任务执行状态,实时反馈给用户。
- MapReduce 任务模块 Map 阶段:根据文件格式(如 CSV、JSON 等)解析输入文件的每一条记录,提取关键信息并转换为键值对形式。例如,对于一个包含用户信息的 CSV 文件,可能将用户 ID 作为键,用户的其他属性(如姓名、年龄、消费金额等)作为值。 Reduce 阶段:对具有相同键的值进行合并和统计分析。如统计每个用户的总消费金额,或计算特定年龄段用户的数量等。根据具体的业务需求实现相应的计算逻辑。
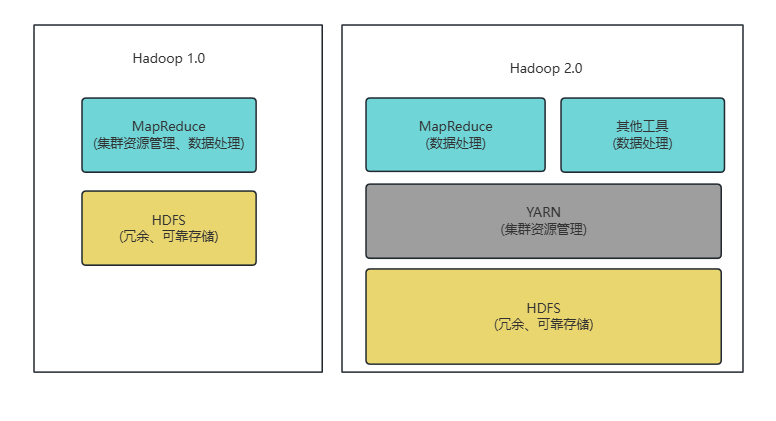
- 结果存储模块 将 MapReduce 任务处理后的结果按照预定格式存储回 HDFS。可以选择合适的文件格式,如文本文件、SequenceFile 等,以便后续的查询和分析。 在Hadoop 1.0 和2.0中各模块功能大致如下:
三、关键技术实现
(一)文件读取与解析
对于 CSV 格式文件,使用 Java 的 BufferedReader 逐行读取文件内容。通过解析逗号分隔符,将每行数据拆分成字段数组,然后根据业务需求提取所需字段进行后续处理。
针对 JSON 格式文件,利用 JSON 解析库(如 Jackson 或 Gson)将文件内容解析为 Java 对象。可以定义与 JSON 数据结构对应的 Java 类,方便对数据进行操作和分析。
(二)MapReduce 任务编写
继承 Hadoop 提供的 Mapper 和 Reducer 抽象类,实现自定义的 Map 和 Reduce 函数。在 Map 函数中,根据文件解析结果生成键值对,例如:
public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 假设处理CSV文件,以第二列数据作为键
String[] fields = value.toString().split(",");
word.set(fields[1]);
context.write(word, one);
}
}在 Reduce 函数中,对相同键的值进行求和或其他统计操作,如:\
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}在主函数中,配置并提交 MapReduce 任务:
public class MyMapReduceJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "My MapReduce Job");
job.setJarByClass(MyMapReduceJob.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}(三)性能调优
合理设置 Map 和 Reduce 任务数量:根据输入文件的大小、节点数量以及硬件配置等因素,调整 Map 和 Reduce 任务的数量。例如,对于较大的文件,可以适当增加 Map 任务数量,以提高并行处理能力;但过多的 Map 任务也可能导致任务启动和调度开销过大,需要进行权衡。
优化数据传输:尽量减少数据在 Map 和 Reduce 阶段之间的传输量。可以通过在 Map 阶段进行数据预处理,只传输必要的数据到 Reduce 阶段。此外,使用压缩技术(如 Snappy 压缩)可以减少数据传输带宽占用,提高传输效率。
内存调优:调整 MapReduce 任务的内存配置参数,确保任务在执行过程中有足够的内存可用。例如,设置适当的 Map 和 Reduce 任务的堆内存大小,避免因内存不足导致任务频繁 GC(垃圾回收),影响性能。
(四)正确性验证
数据完整性检查:在文件读取和处理过程中,加入数据完整性校验机制。例如,对于 CSV 文件,可以检查每行数据的字段数量是否符合预期,对于 JSON 文件,验证数据结构的完整性。如果发现数据损坏或格式错误,及时记录错误信息并进行相应处理。
结果对比验证:对于一些已知结果的测试数据集,在处理完成后,将处理结果与预期结果进行对比。可以编写自动化测试脚本,对处理结果进行全面验证,确保系统的正确性。如果结果不一致,通过日志分析和调试工具找出问题所在,进行修复。
总结
未来,可以进一步优化系统的性能和功能。例如,探索更高效的数据处理算法和技术,提高系统在复杂数据处理场景下的效率;加强系统的容错性和可靠性,确保在节点故障等异常情况下系统仍能正常运行。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号