入门Hadoop存储与计算:实现单词统计的分布式文件处理系统
原创
入门Hadoop存储与计算:实现单词统计的分布式文件处理系统
原创
菜菜的后端私房菜
发布于 2024-11-18 14:49:38
发布于 2024-11-18 14:49:38
入门Hadoop存储与计算:实现单词统计的分布式文件处理系统
”好事“
这里推荐一篇Python多线程的文章:Python多线程与多进程详解:性能提升技巧与实战案例 文章列举Python多线程与多进程两种重要技术,分别总结它们的优缺点以及适用于不同场景,通过文章案例可以更合理的选择不同的并发技术
引言
在当今数字化时代,数据量呈爆炸式增长,传统的数据处理和存储技术已经难以应对这种规模的数据
企业和研究机构迫切需要一种高效、可扩展且可靠的解决方案来管理和分析这些海量数据
Hadoop,作为一种分布式计算框架,凭借其强大的存储和处理能力,成为了大数据领域的明星技术
本文将分析官方文档探讨Hadoop的存储、计算原理,设计并实现一个分布式文件处理系统,该系统能够处理大规模数据文件(统计单词数量),并将处理结果存储回HDFS
HDFS存储
HDFS全称Hadoop Distributed File System(Hadoop分布式文件系统),用于实现大数据场景下的分布式存储
它的设计目标是多节点在廉价的硬件上运行并提供高吞吐量的数据访问,并且提供副本进行数据冗余,实现数据的可靠与可用
架构
HDFS架构通常有DataNode、NameNode常用组件组成:
- DataNode分布在集群中各个节点上,负责实际的存储、检索数据,存储数据时使用数据块(Block)
- NameNode负责文件系统元数据管理,客户端通过它进行交互,它对数据节点进行管理
HDFS架构如下图:
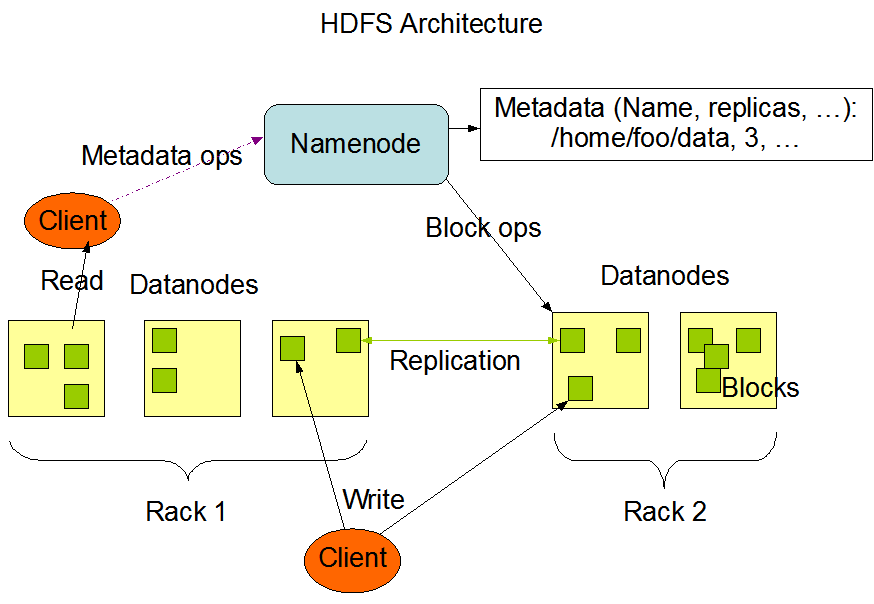
HDFS架构
大型HDFS实例在通常分布在许多机架上的计算机群集上运行,DataNode数据节点被分布在不同的机架(Rack)上
不同机架中的两个节点之间的通信必须通过交换机进行,不同机架间节点同步数据带宽通常会大于同机架间数据同步
也就是说不同机架间节点进行数据同步的开销会更大
复制
为了实现可靠与可用,采用数据块副本来实现数据冗余,在写入的同时进行复制副本到其他节点
一种简单的设计方式是将副本平均到不同机架的节点上(比如设置3个副本,就同步到3个不同机架的节点上)
这样可以防止在整个机架出现故障时丢失数据,并允许在读取数据时使用多个机架的带宽,但会增加写入成本,写入需要将块传输到多个机架
HDFS的最佳实现并不是采用这种方式,以三个副本为例:
- 如果(客户端)在数据节点上则放本地,否则写到同机架随机数据节点上
- 不同(远程)机架上的一个节点
- 不同(远程)机架与第二个副本不同的节点
相当于一个副本放在客户端近的机架中,第二、三个副本放在其他机架不同节点上
以官方文档给出的图片为例,id为1、3的块设置2个副本,id为2、4、5的块设置3个副本
2个副本的情况机架均分,而3副本情况远程机架节点副本多占一个(可以把左边四个节点和右边四个节点看出两个机架)
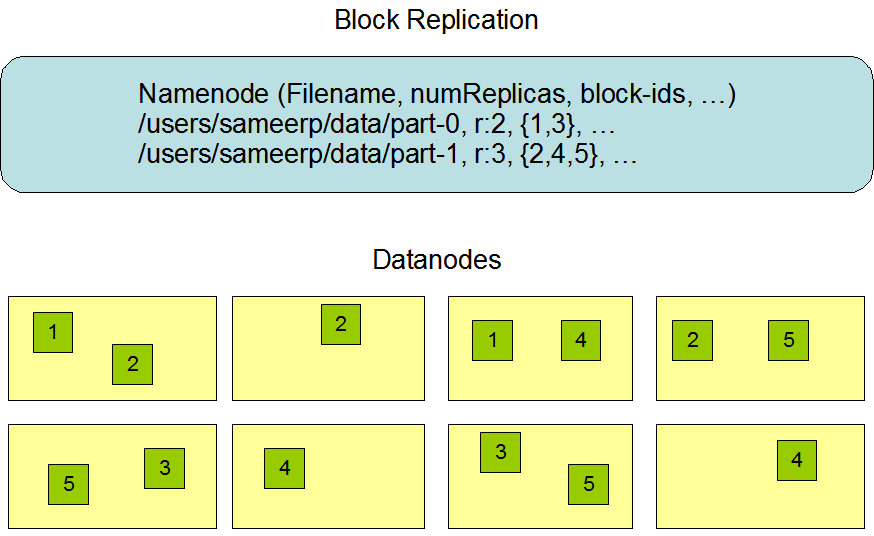
复制
这样的策略,不会将副本平均分配到不同机架上,减少写入的开销,并且不影响数据可靠,同时也可以通过多机架带宽读,但是分布不均匀(三分之二副本在一个机架、三分之一副本在另一个机架)
原文如下:
when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode in the same rack as that of the writer, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack.
MapReduce计算
Hadoop中的计算模型采用MapReduce,MapReduce的核心思想类似分治,将一个大的计算任务分解成多个小的任务,这些小任务可以并行处理,最后将结果汇总
MapReduce模型分为Map、Reduce两个阶段,其中Reduce又分为shuffle, sort and reduce
运行流程
文件上传到HDFS -> 输入 input <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> output 输出 -> 存储到HDFS
- 文件上传到HDFS
- 输入分片:将输入数据分割成多个分片,每个分片会被分配给一个Map任务
- Map任务:每个Map任务读取一个分片的数据,调用Map函数处理数据,生成中间键值对
- Shuffle:将Map任务生成的中间键值对按照键进行分区,发送到相应的Reduce任务
- Sort:在Reduce任务接收到中间键值对后,按照键进行排序
- Reduce任务:接收到一组具有相同键的中间键值对,调用Reduce函数进行聚合处理,生成最终的输出键值对
- 输出:Reduce任务将最终的输出键值对写入到输出文件中存储到HDFS
实战
实战阶段在搭建环境后,通过官网统计单词的案例来进行演示
环境搭建
具体流程包括可能踩坑的地方可以查看从零搭建Hadoop的文章
这里简略进行说明:
- 创建Hadoop用户
#添加用户
sudo useradd hadoop
#设置密码
sudo passwd hadoop
#切换用户
su hadoop- 配置SSH
#安装
yum install openssh
#需要密码校验
ssh localhost
#登陆成功后退出 开始配置免密登陆
exit
cd ~/.ssh
#生成密钥 回车几下
ssh-keygen -t rsa
#添加
cat ./id_rsa.pub >> ./authorized_keys
#确保有权限
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
#再次登陆不需要密码
ssh localhost- JDK安装配置
#更新包索引
sudo yum update -y
#安装JDK
sudo yum install java-1.8.0-openjdk-devel -y
#找到JDK目录 JDK通常在/usr/lib下
#/usr/lib/jvm
pwd
#目录名太长改成jdk8
mv java-1.8.0-openjdk-1.8.0.432.b06-2.oc8.x86_64/ jdk8
#配置环境变量 在末尾追加环境变量
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jdk8
export PATH=$JAVA_HOME/bin:$PATH
#环境变量生效
source ~/.bashrc
#查看版本号 判断是否安装成功
java -version- 下载Hadoop解压
#解压
sudo tar -zxf hadoop-3.4.1.tar.gz
#进入目录
cd hadoop-3.4.1
#查看版本 如果没找到JDK说明 JDK环境变量配的有问题
./bin/hadoop version- 配置Hadoop环境变量
#末尾追加 我的Hadoop目录是:/home/lighthouse/hadoop-3.4.1
vim ~/.bashrc
export HADOOP_HOME=/home/lighthouse/hadoop-3.4.1
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
#这里也有JAVA的环境变量
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH- 配置数据文件和hdfs地址
vim core-site.xml
<configuration>
<!-- 临时文件 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/lighthouse/hadoop-data/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!--hdfs地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>- 配置hdfs存储相关配置
vim hdfs-site.xml
<configuration>
<!-- 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- namenode 元数据 存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/lighthouse/hadoop-data/tmp/dfs/name</value>
</property>
<!-- datanode 真正数据 存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/lighthouse/hadoop-data/tmp/dfs/data</value>
</property>
</configuration>- 配置jdk环境变量
vim hadoop-env.sh
exportJAVA_HOME=/usr/1ib/jvm/jdk8- 格式化数据节点
hdfs namenode -format start-all.sh执行启动脚本
查看NameNode的WEB界面,默认端口:50070(Hadoop 2.X版本),9870(Hadoop 3.X版本)
访问UI WEB界面
编写MapReduce代码
创建一个maven项目,引入Hadoop需要的依赖:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.4.1</version>
</dependency>
</dependencies>实现Mapper
Map的实现需要实现 org.apache.hadoop.mapreduce.Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
它的四个泛型代表着key/value的输入与输出
/**
* 实现Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* map 转换为 <单词,1>
*
* @param key 输入KEY
* @param value 输入VALUE
* @param context
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//输出 <单词,1> 比如 <CaiCai,1> 表示CaiCai出现1次
context.write(word, one);
}
}
}这段代码会将输入文本中的单词作为输出Key,次数为1作为输出value 即 <CaiCai,1>
实现Reduce
org.apache.hadoop.mapreduce.Reducer前的shuffle会将同key的次数转换为集合<CaiCai,<2,1,3>>,实现时只需要进行累加结果并输出
/**
* 实现Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
//统计次数
int sum = 0;
//经过Shuffle 会对相同key进行分区 比如<CaiCai,2> <CaiCai,1> <CaiCai,3>在一个分区
//values就是次数的集合 <2,1,3> 分别出现2、1、3次,累加即可
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
//累加次数后输出 <>
context.write(key, result);
}
}完整代码如下:
package com.caicaijava.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 统计单词出现的次数
*/
public class WordCount {
/**
* 实现Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* map 转换为 <单词,1>
*
* @param key 输入KEY
* @param value 输入VALUE
* @param context
* @throws IOException
* @throws InterruptedException
*/
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//输出 <单词,1> 比如 <CaiCai,1> 表示CaiCai出现1次
context.write(word, one);
}
}
}
/**
* 实现Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
//统计次数
int sum = 0;
//经过Shuffle 会对相同key进行分区 比如<CaiCai,2> <CaiCai,1> <CaiCai,3>在一个分区
//values就是次数的集合 <2,1,3> 分别出现2、1、3次,累加即可
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
//累加次数后输出 <>
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第一个参数为输入地址
FileInputFormat.addInputPath(job, new Path(args[0]));
//第二个参数为输出地址
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//等待任务执行完成结束
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}将启动类通过maven打成jar包后上传到Linux中
使用Hadoop
使用shell脚本来实现往文件中追加指定数量的单词:
vim gen.sh
#!/bin/bash
# 检查参数数量
if [ "$#" -ne 3 ]; then
echo "Usage: $0 <word> <number_of_words> <output_file>"
exit 1
fi
# 获取参数
word=$1
num_words=$2
output_file=$3
# 检查输出文件是否存在
if [ ! -f "$output_file" ]; then
touch "$output_file"
fi
# 生成指定数量的单词并追加到文件
generated_words=""
for (( i=1; i<=num_words; i++ ))
do
generated_words+="$word "
done
# 去掉最后一个多余的空格
generated_words=${generated_words% }
# 追加到输出文件
echo "$generated_words" >> "$output_file"
echo "Generated $num_words instances of '$word' and appended to $output_file"修改权限后,生成999个Hello和CaiCai 加入input.txt文件
chmod 777 gen.sh
./gen.sh Hello 999 input.txt
#打印 Generated 999 instances of 'Hello' and appended to input.txt
./gen.sh CaiCai 999 input.txt
#打印 Generated 999 instances of 'CaiCai' and appended to input.txt将输入文件上传到hdfs
hadoop fs -mkdir /test
hadoop fs -mkdir /test/input
hadoop fs -put input.txt /test/input/hellocaicai.txt执行:
hadoop jar HadoopDemo-1.0-SNAPSHOT.jar com.caicaijava.hadoop.WordCount /test/input/hellocaicai.txt /test/output/hellocaicaihadoop jar 执行命令
HadoopDemo-1.0-SNAPSHOT.jar 程序jar包
com.caicaijava.hadoop.WordCount 启动类全限定类名
/test/input/hellocaicai.txt hdfs上的输入文件
/test/output/hellocaicai hdfs的输出目录
查看结果
hadoop fs -cat /test/output/hellocaicai/part-r-00000
查看结果
至此完成了HDFS的搭建,以及对数据文件进行统计单词数量并将结果存储到HDFS
如果有其他需要处理数据的需求,只要重新实现MapReduce即可
总结
本文主要讨论Hadoop下的HDFS存储与MapReduce计算
HDFS存储架构主要由namenode、datanode来实现,其中存储分为不同机架rack,机架上的节点间通信需要交换机,节点上真正存储数据块block
同时为了实现数据可用与可靠,会对数据块进行冗余,副本存储在不同机架上,机架上不均匀的存储可以减少写开销
计算流程会先对输入进行切片,切片后一一进行映射map,然后对KV进行分区排序后,再进行reduce合并,最终将结果输出到文件存储到HDFS
最后(点赞、收藏、关注求求啦~)
我是菜菜,热爱技术交流、分享与写作,喜欢图文并茂、通俗易懂的输出知识
本篇文章被收入专栏 常用框架,感兴趣的同学可以持续关注喔
本篇文章笔记以及案例被收入 Gitee-CaiCaiJava、 Github-CaiCaiJava,除此之外还有更多Java进阶相关知识,感兴趣的同学可以starred持续关注喔~
有什么问题可以在评论区交流,如果觉得菜菜写的不错,可以点赞、关注、收藏支持一下~
关注菜菜,分享更多技术干货,公众号:菜菜的后端私房菜
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号