批量爬取b站视频
原创

简介
本文主要功能是批量爬取b站mp3和mp4文件,然后对这些文件进行批量合并
随便点击一个视频,复制该链接https://www.bilibili.com/video/BV1w62qYNEaS/
爬取前准备
- 程序结构
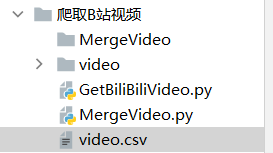
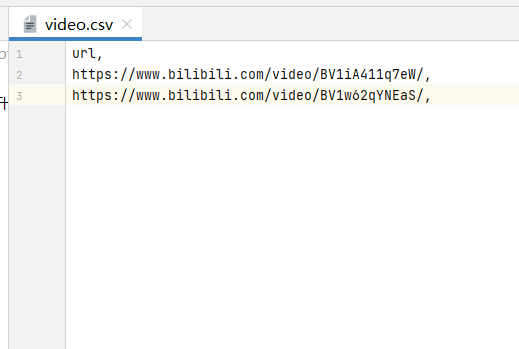
- video:保存要爬取的链接(格式如下)
- video:保存爬取下来的mp3和mp4文件
- MergeVideo:保存合并mp3和mp4的文件
GetBiliBiliVideo.py
import requests
import re
import json
import os
import csv
# TODO 读取 CSV 文件中的视频链接
video_links = []
with open('video.csv', 'r') as file:
reader = csv.reader(file)
next(reader) # TODO 跳过表头
for row in reader:
video_links.append(row[0])
# TODO 定义 cookie 和 headers
cookie = "使用自己的cookie"
headers = {
"Referer": "",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0",
"Cookie": cookie
}
# TODO 创建保存视频和音频的文件夹
if not os.path.exists('video'):
os.makedirs('video')
# TODO 批量爬取视频
for url in video_links:
try:
headers["Referer"] = url
response = requests.get(url=url, headers=headers)
html = response.text
# TODO 提取视频标题
title = re.findall('title="(.*?)"', html)[0]
# TODO 提取视频信息
info = re.findall('window.__playinfo__=(.*?)</script>', html)[0]
json_data = json.loads(info)
# TODO 提取视频链接
video_url = json_data['data']['dash']['video'][0]['baseUrl']
# TODO 提取音频链接
audio_url = json_data['data']['dash']['audio'][0]['baseUrl']
# TODO 获取视频内容
video_content = requests.get(url=video_url, headers=headers).content
# TODO 获取音频内容
audio_content = requests.get(url=audio_url, headers=headers).content
# TODO 保存视频文件
with open(os.path.join('video', title + '.mp4'), mode='wb') as v:
v.write(video_content)
print(title + " 视频爬取完成")
# TODO 保存音频文件
with open(os.path.join('video', title + '.mp3'), mode='wb') as a:
a.write(audio_content)
print(title + " 音频爬取完成")
except Exception as e:
print(f"Error processing {url}: {e}")
print("================================================")
print("所有视频和音频已成功爬取并保存")MergeVideo.py
import os
from moviepy.editor import VideoFileClip, AudioFileClip
# TODO 指定视频文件夹路径
video_folder = "./video"
# TODO 获取文件夹中的所有文件
files = os.listdir(video_folder)
# TODO 创建一个字典来存储匹配的mp3和mp4文件
file_pairs = {}
# TODO 遍历文件夹中的文件
for file in files:
# TODO 获取文件的扩展名
ext = os.path.splitext(file)[1].lower()
# TODO 如果是mp3或mp4文件
if ext in ('.mp3', '.mp4'):
# TODO 获取文件名(不带扩展名)
base_name = os.path.splitext(file)[0]
# TODO 如果文件名已经在字典中,说明找到了一对匹配的文件
if base_name in file_pairs:
file_pairs[base_name].append(file)
else:
file_pairs[base_name] = [file]
# TODO 创建一个合并后的视频文件夹(如果它不存在)
output_folder = "./MergeVideo"
os.makedirs(output_folder, exist_ok=True)
# TODO 合并匹配的文件
for base_name, files in file_pairs.items():
if len(files) == 2:
# TODO 确保一个是mp3,一个是mp4
mp4_file = None
mp3_file = None
for file in files:
if file.endswith('.mp4'):
mp4_file = file
elif file.endswith('.mp3'):
mp3_file = file
if mp4_file and mp3_file:
# TODO 读取视频和音频文件
video_clip = VideoFileClip(os.path.join(video_folder, mp4_file))
audio_clip = AudioFileClip(os.path.join(video_folder, mp3_file))
# TODO 将音频合并到视频中
final_clip = video_clip.set_audio(audio_clip)
# TODO 保存合并后的视频
output_path = os.path.join(output_folder, f"{base_name}_merged.mp4")
final_clip.write_videofile(output_path, codec='libx264')
print(f"合并 {mp4_file} 和 {mp3_file} 到 {output_path}")
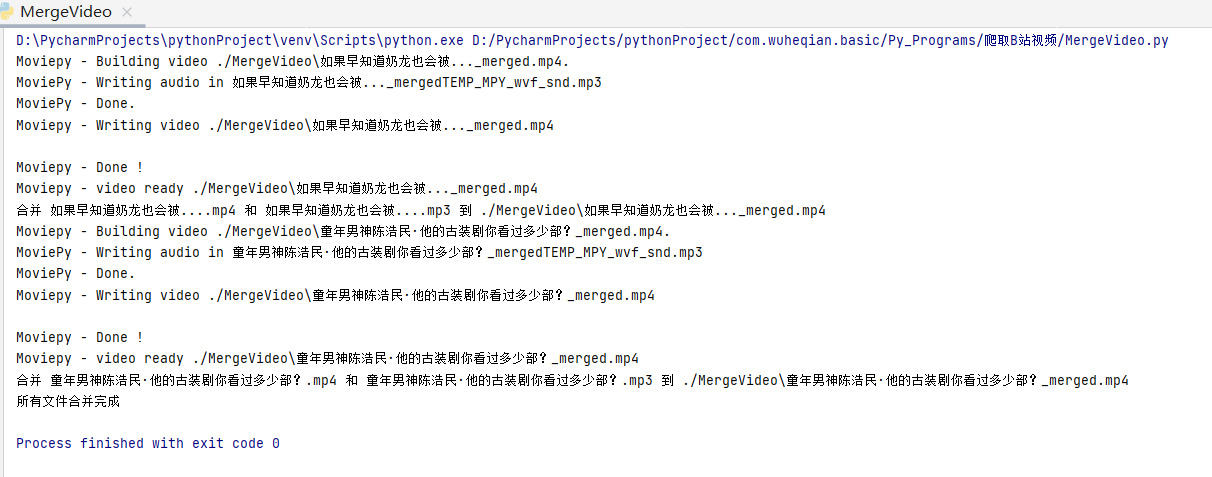
print("所有文件合并完成")结果展示
- GetBiliBiliVideo.py


- MergeVideo.py

有的视频系统自带的视频播放器播放不了,可以下载万能播放器player进行播放:https://potplayer.tv/?lang=zh_CN

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号