网络药理学—基于网络爬虫获取复方中药活性小分子及其对应靶点
原创
网络药理学—基于网络爬虫获取复方中药活性小分子及其对应靶点
原创
sheldor没耳朵
发布于 2024-11-16 14:06:37
发布于 2024-11-16 14:06:37
网络药理学—基于网络爬虫获取复方中药活性小分子及其对应靶点
在中药复方的网络药理学分析中,第一步就是获取复方中药活性小分子及其对应靶点,常规做法是在TCMSP搜索相关中药,再根据(OB>30,DL>0.18)筛选出符合条件的小分子,再获取对应的小分子靶点。这里记录下使用网络爬虫的方法一步获取这些信息。
如某中药复方包含以下中药成份,首先需要在TCMSP中确定可以检索到对应的成份,记录其拉丁学名。(如果检索不到,可以再换其他数据库,99%都是可以的)
熟地黄 Rehmanniae Radix Praeparata
牡丹皮 Cortex Moutan
菟丝子 Cuscutae Semen
白芍 Paeoniae Radix Alba1 小分子及其对应靶点获取
首先激活conda环境,在运行1.TCMSP.py脚本,注意goods替换为需要查询的中药。关于conda环境的配置,可以直接运行python 1.TCMSP.py,根据报错信息提示安装对应的包即可。执行网络爬虫还需要和自己浏览器版本一致的浏览器驱动,我用的是谷歌浏览器,具体的驱动可以在https://mirrors.huaweicloud.com/chromedriver/下载对应版本。执行完之后,会在table文件夹中生成每个中药未过滤前的小分子,以及小分子对应的靶点。
conda activate lixiao
python 1.TCMSP.py1.TCMSP.py
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import re
import pandas as pd
import pickle
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys
import json
#webdriver的路径
gecko_driver_path = '/Users/tianfu/Documents/database/chromedriver-mac-arm64/chromedriver'
service = Service(executable_path=gecko_driver_path)
import re
#替换,注意一定要先在TCMSP中检索到才行
goods = ["Rehmanniae Radix Praeparata",
"Cortex Moutan",
"Cuscutae Semen",
"Paeoniae Radix Alba",
]
for good in goods:
option = webdriver.ChromeOptions()
#option.add_argument('headless')
line_data = {}
time_data = {}
#打开浏览器
start_time = time.time()
yueri = time.strftime('%m月%d日',time.localtime(start_time))
#driver = webdriver.Chrome(options=option,service=service)
time.sleep(1)
print(good)
driver = webdriver.Chrome(service=service,options=option)
driver.maximize_window()
driver.get('https://old.tcmsp-e.com/tcmsp.php')
el1 = driver.find_element(By.XPATH,'//*[@id="inputVarTcm"]').send_keys(good,Keys.ENTER)
time.sleep(1)
el2 = driver.find_element(By.XPATH,'//*[@id="grid"]/div[2]/table/tbody/tr/td[3]/a')
driver.execute_script('arguments[0].click();',el2)
time.sleep(1)
data0 = driver.page_source
# 使用正则表达式匹配以<div class="k-content k-state-active"开头的行
#pattern = re.compile(r'data: \[\{"molecule_ID".*?\]')
pattern = re.compile(r'^\s*data:.*', re.MULTILINE)
matches = pattern.findall(data0)
#print(data0)
#print(matches[0][22:-1])
print('\n\n\n\n\n')
print(matches[1])
#print(json.loads(matches[0][6:]))
df1 = pd.DataFrame(json.loads(matches[0][22:-1]))
df2 = pd.DataFrame(json.loads(matches[1][22:-1]))
print(df1)
print(df2)
df1.to_csv(f'table/mol_{good}.csv',index=False)
df2.to_csv(f"table/mol_target_{good}.csv",index=False)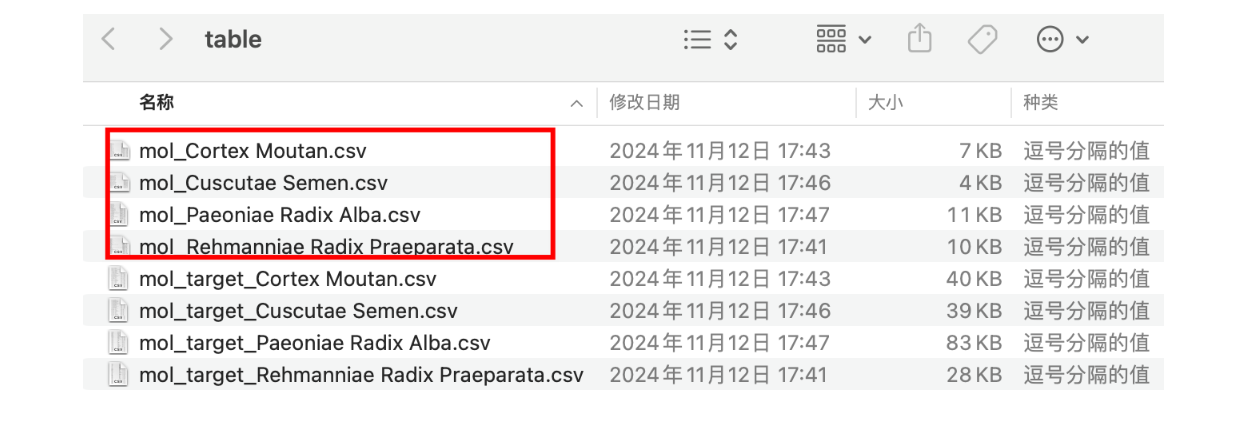
2 小分子及其对应靶点过滤
之后再执行2.Filter.py这个脚本对小分子,根据OB(口服利用度)>30,DL(drug-likeliss,类药性)>0.18的小分子筛选出符合条件的小分子,再把这些小分子对应的靶点全部筛选出来。执行完生成两个文件,
2.Filter.py
import pandas as pd
#goods = ["Coptidis Rhizoma","Scutellariae Radix","Gardeniae Fructus","Phellodendri Chinrnsis Cortex"]
goods = ["Rehmanniae Radix Praeparata",
"Cortex Moutan",
"Cuscutae Semen",
"Paeoniae Radix Alba",
]
df3=pd.DataFrame()
df4=pd.DataFrame()
for good in goods:
df1 = pd.read_csv(f"table/mol_{good}.csv")
df2 = pd.read_csv(f"table/mol_target_{good}.csv")
df1 = df1[(df1["ob"]>=30) & (df1["dl"]>=0.18)]
drugs = df1['molecule_name'].values.tolist()
df2 = df2[df2["molecule_name"].isin(drugs)]
df1['drug'] = good
df2['drug'] = good
df3 = pd.concat([df3,df1])
df4 = pd.concat([df4,df2])
df5 = pd.read_csv('/Users/tianfu/Documents/database/uniprot/uniprotkb_AND_reviewed_true_AND_model_o_2024_09_23.tsv',sep="\t")
N =[]
for prot in df5["Protein names"].values:
if " (" in prot:
prot = prot.split(" (")[0]
else:
prot = prot
N.append(prot)
df5["Protein names"] = N
df4 = pd.merge(df4, df5.loc[:,["Protein names","Gene Names"]], left_on='target_name', right_on='Protein names', how='inner')
print(df4)
df3.to_csv(f'table/molecule.csv',index=False)
df4.to_csv(f"table/target.csv",index=False)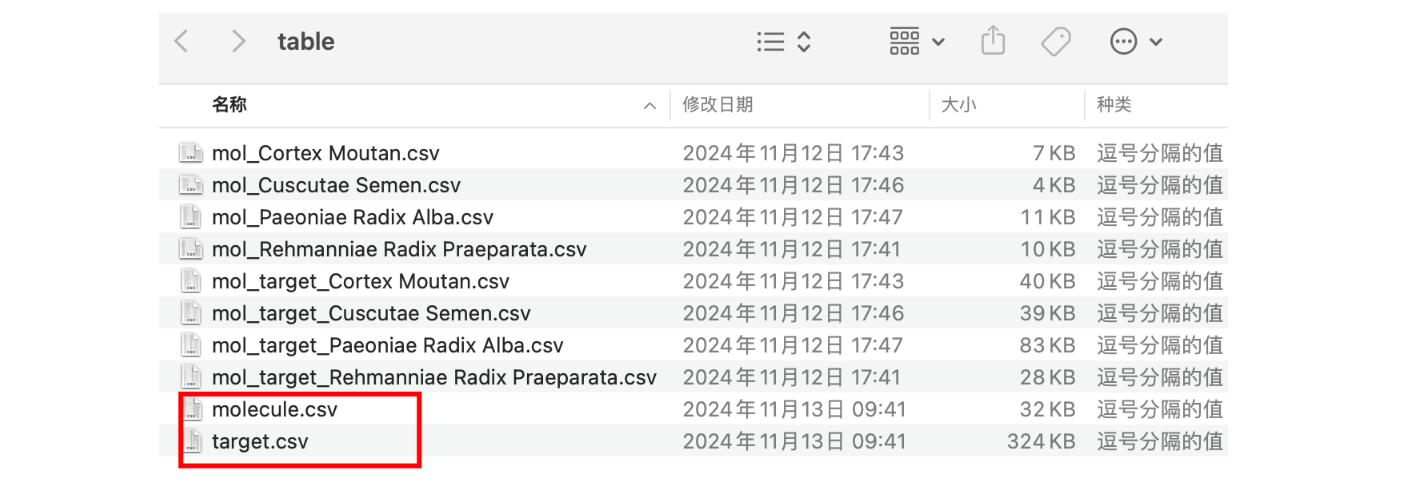
molecule.csv中包含所有中药满足OB(口服利用度)>30,DL(drug-likeliss,类药性)>0.18的小分子,target.csv中包含这些小分子的所有靶点。
至此网络药理学的第一步获取复方中药活性小分子及其对应靶点就已经完成了。
附conda环境包:
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号