数据一致性解决方案
原创
数据一致性解决方案
原创
liddytang
发布于 2024-09-06 18:34:02
发布于 2024-09-06 18:34:02
复杂业务系统中,你或许面临多种权限、多种状态的业务数据,不得不存在多种存储选型。
多份存储的数据如何保障数据一致性,是作为系统架构设计师必须解决的问题。
数据一致性定义了数据的更新顺序和可见性规则。不同的业务对数据一致性要求不同,例如金融在线业务对数据一致性高,互联网内容点赞、评论等对大多只要求最终一致性。
基础理论
1. 分布式理论:ACID、CAP、BASE
在聊数据一致性之前,首先抛转引起,说说几种分布式理论:ACID(原子性、可用性、隔离性、持久化)、CAP(一致性、可用性、分区容错性)、BASE(基本可用、软状态、最终一致性, 其中软状态是系统允许数据在一段时间内存在中间状态,但保持最终一致性),BASE 是对 CAP 中一致性 C 和可用性 A 权衡的结果,是互联网大规模分布式数据基于CAP理论实践得出。ACID和CAP中的各项指标在实际业务难以全部满足,例如,保障强一致性必然一定程度损耗可用性。
2. 一致性等级和算法
- 强一致性:系统写入什么,读出来就是什么,数据更新即可见,主从架构中,主库更新并同步给从库,从库回复“更新成功后,即更新成功”;强一致性包含线性一致性和顺序一致性;实现强一致性的算法包含Paxos算法、Raft算法、ZAB。
- 弱一致性:主库写入成功后,不等待从库的响应,直接返回“更新成功”,则复制是异步的,即弱一致性,弱一致性包含因果一致性和最终一致性;实现若一致性的算法包含 DNS系统、Gossip。
数据一致性分类
1.线性一致性(强一致性)
操作顺序与与实际发生的顺序一致并且操作立即可见,一般用分布式事务解决raft协议和paxos协议保障,是分布式系统重用户最希望看到的状态。线性一致性(linearizability),也称为原子一致性(atomic consistency),强一致性(strong consistency),立即一致性(immediate consistency) 或外部一致性(external consistency )
线性一致性提供了什么保证?
- 只要一个客户端成功完成写操作,所有客户端从数据库中读取数据必须能够看到刚刚写入的值。
- 系统应保障读到的值是最近的、最新的,而不是来自陈旧的缓存或副本。
- 线性一致性是一个新鲜度保证(recency guarantee)。
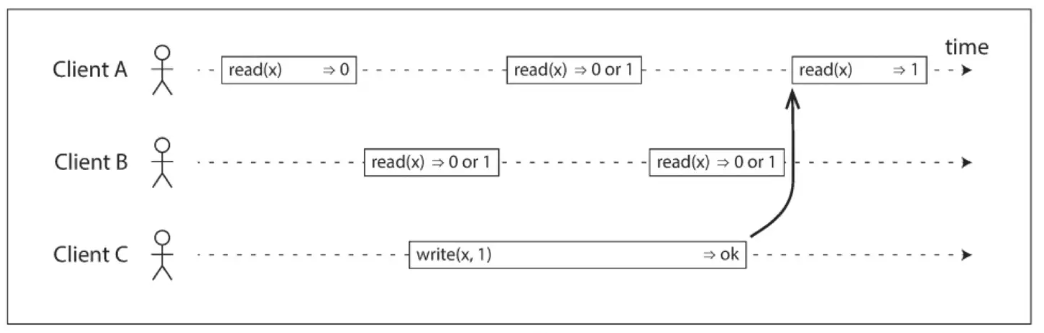
读写请求并发的情况,ClientB可能返回0 或者 1
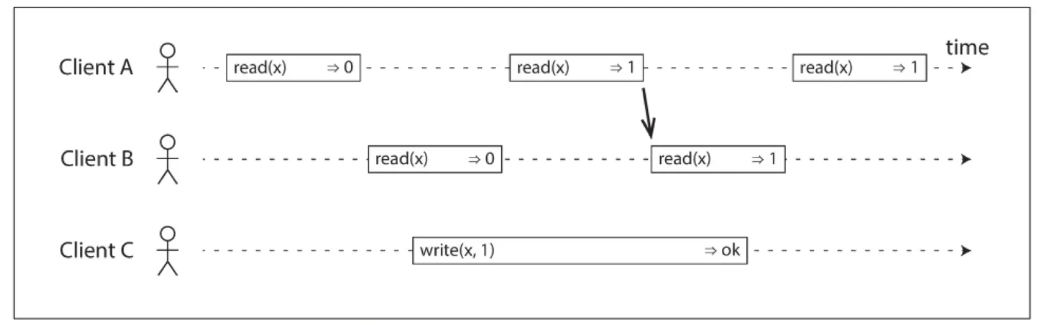
加入一条约束,任何一个读取返回新值后,所有后续读取(在相同或其他客户端上)也必须返回新值
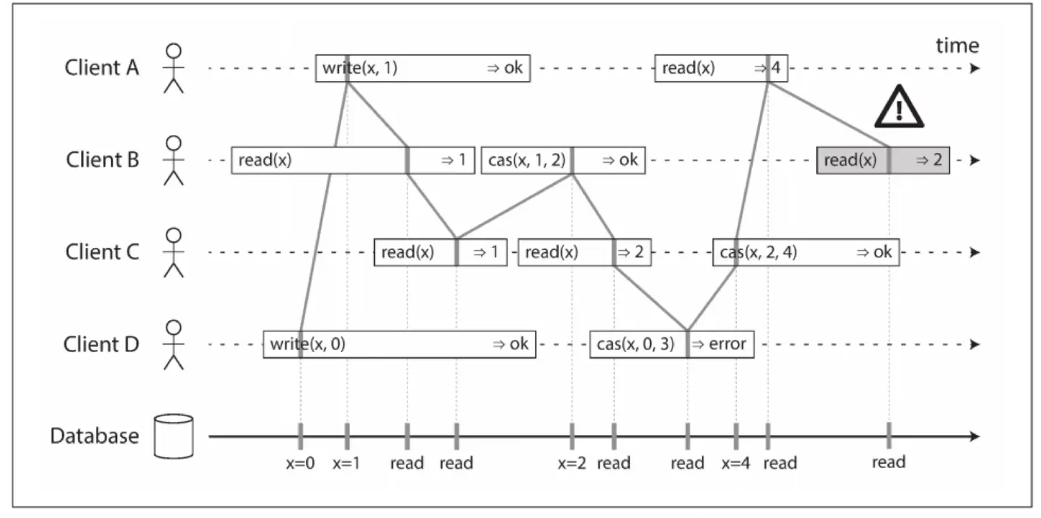
添加cas原子操作展示,细化在实例CPU上,线性一致性保障,Client B最后读取到2并不满足线性一致性条件
综上,得出以下几点结论(上面序列图片可以参考书籍DDIA)
- 原子和瞬间的被执行,一旦执行成功,对所有的 client 可见
- 让多个副本,对应用来说看起来就像一个副本
- 线性一致性保证的是对单个对象的单个操作的保证瞬间或者原子的被执行,注意是事务 ACID 语义的区分,事务 ACID 语义是保证的一组操作(单个对象或者多个对象操作)
- 线性一致性并不局限在分布式系统,例如:在多核 CPU 中,如普通变量的 counter 就不是线性一致的,只有 atomic 变量才是线性一致的;还有很多如 queue、mutex 一般都必须满足线性化语义
2.顺序一致性(强一致性)
顺序一致性相对放松,对于写操作不要求严格按时间排序,对于读操作只要求所有客户端观察到的顺序一致;客户端发送的更新命令,服务端会按它们发送的顺序执行。
Zookeeper 通过主节点执行所有写操作,从节点复制修改操作,这样所有节点的更新顺序都和主节点相同,不会出现某个节点的更新顺序与其它节点不同的情况。但是Zookeeper 允许客户端从从节点读取数据,因此如果客户端在读取过程中连接了不同的节点,则顺序一致性就得不到保证了,基于这个原理也就能理解kafka能保障同一分区中数据一致性。
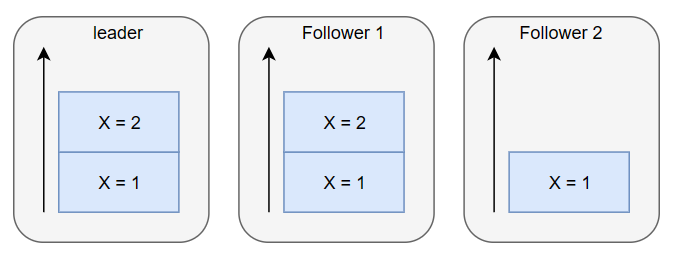
顺序不一致举例
如上图,主节点的 X=2 消息还没有同步到 Follower 2,此时如果有两个客户端:
- A: 先后连接到 Follower 1 和 Follower 2,则读到 X 的值为
2 -> 1 - B: 先后连接到 Follower 2 和 Follower 1,则读到 X 的值为
1 -> 2
上述情况利用 zookeeper “单一视图”的保证,保证在连接到 Follower 2 后,不会连上状态更老的 Follower 1,即可保障数据满足顺序一致性。
3. 因果一致性(Causal Consistency)
相较于顺序和线性一致性,因果一致性就简单一些,其实就只要满足在 Lamport 时钟中提到的happen-before关系即可:
- 引入符号→做为表示事件之间
happen-before的记号。 - 在同一个进程中,如果事件 a 在事件 b 之前发生,那么 a→b。(这是因为根据规则 1,进程每次发出事件之后都会将本地的 lamport 时钟加一,于是可以在同一个进程内定义事件的先后顺序了)
- 在不同的进程中,如果事件 a 表示一个进程发出一个事件,事件 b 表示接收进程收到这个事件,那么也必然满足 a→b。(这是因为根据规则 2,接收进程在收到事件之后会取本地时钟和事件时钟的最大值并且 +1,于是发出事件和接收事件尽管在不同的进程,但是也可以比较其 lamport 时钟知道其先后顺序了)
- 最后,
happend-before关系是满足传递性的,即:如果 a→b 且 b→c,那么也一定有 a→c。
下面以朋友圈的举例:
- 夏侯铁柱在朋友圈发表状态“我戒指丢了”
- 夏侯铁柱在同一条状态下评论“我找到啦”
- 诸葛建国在同一条状态下评论“太棒了”
- 远在美国的键盘侠看到“我戒指丢了”“太棒了”,开始喷诸葛建国
- 远在美国的键盘侠看到“我戒指丢了”“我找到啦”“太棒了”,意识到喷错人了
4. 最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。最终一致性的保障方式有异步复制、消息队列、分布式事务(raft、paxos);当用户从异步从库读取时,如果此异步从库落后,他可能会看到过时的信息。这种不一致只是一个暂时的状态——如果等待一段时间,从库最终会赶上并与主库保持一致。这称为最终一致性;最终一致性模型的实现通常依赖于一些复制策略,如 Dynamo 系统中的优先列表(preference list)和一致性哈希(consistent hashing),以及一些分布式事务处理技术如 TCC,或者一致性协议如 ZooKeeper 的 ZAB 等。
业界比较推崇是最终一致性级别,那实现最终一致性的具体方式是什么呢? 《分布式协议与算法实战》open in new window 中是这样介绍:
- 读时修复 : 在读取数据时,检测数据的不一致,进行修复。比如 Cassandra 的 Read Repair 实现,具体来说,在向 Cassandra 系统查询数据的时候,如果检测到不同节点 的副本数据不一致,系统就自动修复数据。
- 写时修复 : 在写入数据,检测数据的不一致时,进行修复。比如 Cassandra 的 Hinted Handoff 实现。具体来说,Cassandra 集群的节点之间远程写数据的时候,如果写失败 就将数据缓存下来,然后定时重传,修复数据的不一致性。
- 异步修复 : 这个是最常用的方式,通过定时对账检测副本数据的一致性,并修复。
想要了解分布式理论更多的理论知识可参考下面书籍清单:
《分布式协议与算法实战》
《数据密集型应用系统设计》
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号