单细胞学习小组第二天
原创

今天学习的是单细胞单样本数据的处理。
1.下载和整理数据
1.1 解包文件
1.2 单细胞文件组织的要求
1.3 修改文件名称
2.读取并创建Seurat对象
2.1读取文件
2.2 R语言补充知识👉稀疏矩阵
2.3 创建Seurat对象
2.4 细胞抽样
2.5 R语言补充知识☞对象
2.6 探索Seurat对象的meta信息
2.7 R语言补充知识☞管道符号
3.质控
3.1 质控的指标及原因
3.2计算线粒体基因比例
4.降维聚类分群
4.1 理解降维这件事
4.2 R语言知识补充👉存在即跳过
untar("GSE231920_RAW.tar",exdir = "input")
dir("input")
library(stringr)
nn = str_remove(dir("input/"),"GSM7306054_sample1_")
file.rename(paste0("input/",dir("input/")),
paste0("input/",nn))
dir("input/")
library(Seurat)
library(patchwork)
library(tidyverse)
ct = Read10X("input/")
dim(ct)
class(ct)
seu.obj <- CreateSeuratObject(counts = ct,
min.cells = 3,
min.features = 200)
dim(seu.obj)
set.seed(1234)
seu.obj = subset(seu.obj,downsample = 3000)
seu.obj[["percent.mt"]] <- PercentageFeatureSet(seu.obj, pattern = "^MT-")
head(seu.obj@meta.data)
VlnPlot(seu.obj,
features = c("nFeature_RNA",
"nCount_RNA",
"percent.mt"),
ncol = 3,pt.size = 0.5)
seu.obj = subset(seu.obj,
nFeature_RNA < 6000 &
nCount_RNA < 30000 &
percent.mt < 18)
f = "obj.Rdata"
if(!file.exists(f)){
seu.obj = seu.obj %>%
NormalizeData() %>%
FindVariableFeatures() %>%
ScaleData(features = rownames(.)) %>%
RunPCA(features = VariableFeatures(.)) %>%
FindNeighbors(dims = 1:15) %>%
FindClusters(resolution = 0.5) %>%
RunUMAP(dims = 1:15) %>%
RunTSNE(dims = 1:15)
save(seu.obj,file = f)
}
load(f)
ElbowPlot(seu.obj)
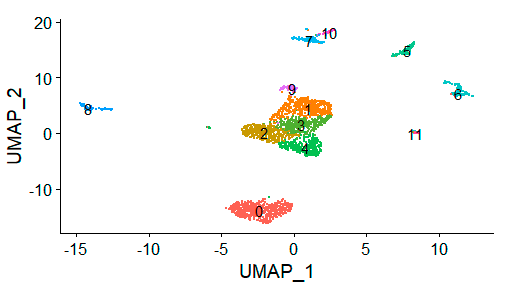
p1 <- DimPlot(seu.obj, reduction = "umap",label = T)+NoLegend();p1抽样数据出图:这个图和教程有出入,因为我用的Seurat版本是V4的,暂时有个项目需要V4版本的,所以没有更新。
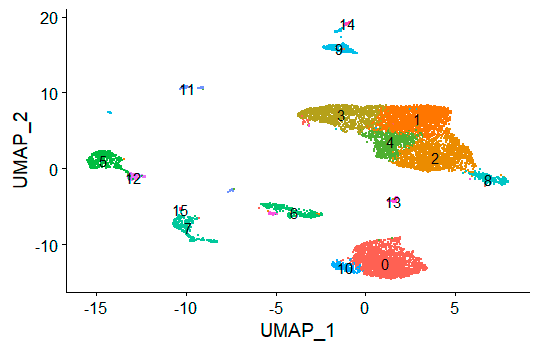
完整数据出图:细胞数量变多了,分群也变多了。
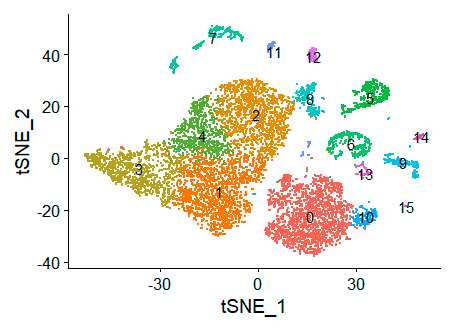
展示下TSNE图:
本节课学习内容结束。最后,关于resolution的问题,技能树有个比较好的教程,可以学习摸索适合自己的resolution。
不知道你的单细胞分多少群合适,clustree帮助你:https://mp.weixin.qq.com/s/cfo10QtxCasWfF4V9apUvw
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
作者已关闭评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号