数据结构——栈和队列


前言
栈和队列:
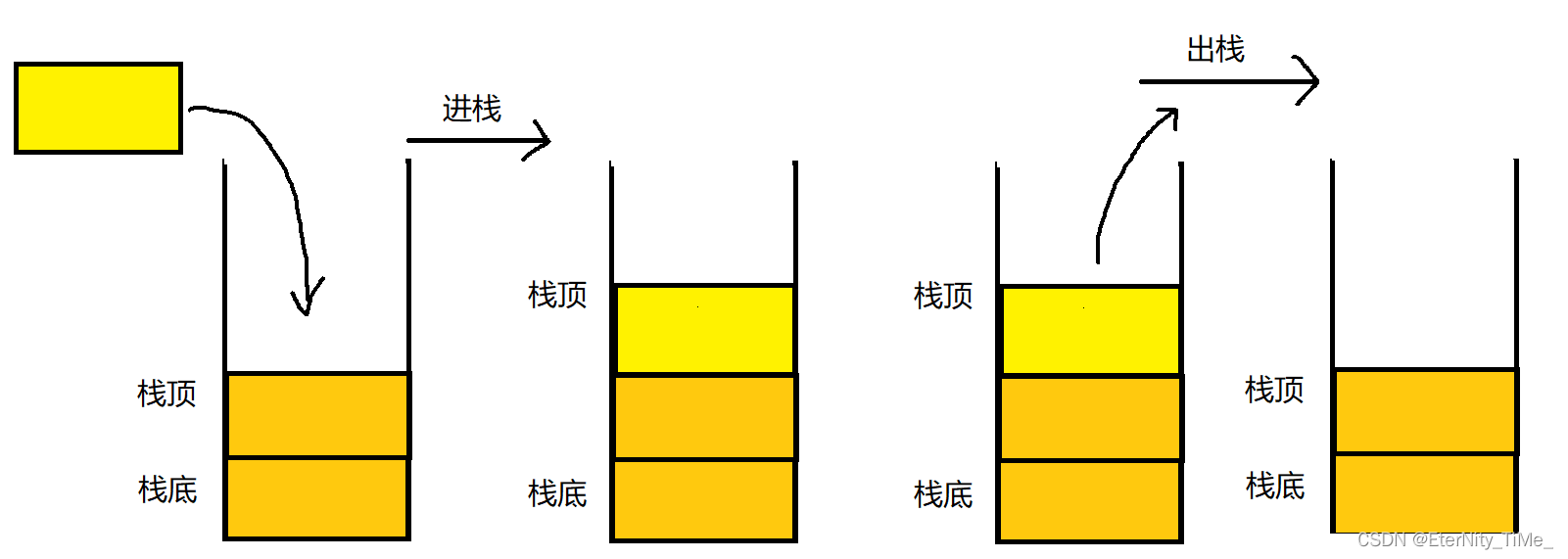
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。 压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。 出栈:栈的删除操作叫做出栈。出数据也在栈顶。
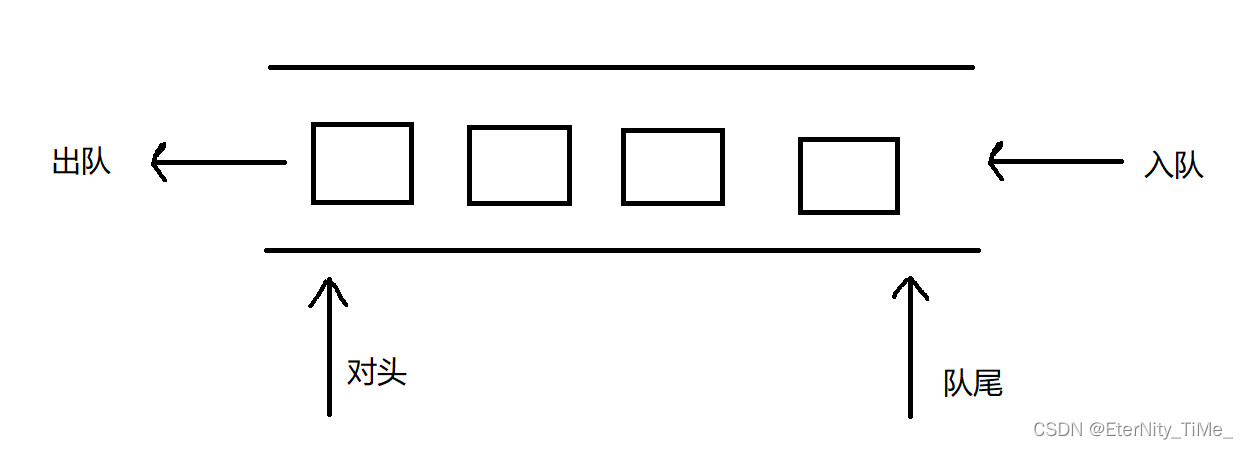
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出 FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头
一、栈的实现
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小。

在Stack.h中我们调用的头文件
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>1.1 创建结构体
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top; // 栈顶
int capacity; // 容量
}Stack;本次所需实现的功能有以下:
// 初始化栈
void StackInit(Stack* pst);
// 销毁栈
void StackDestroy(Stack* pst);
// 入栈
void StackPush(Stack* pst, STDataType x);
// 出栈
void StackPop(Stack* pst);
// 获取栈顶元素
STDataType Stacktop(Stack* pst);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(Stack* pst);
// 获取栈中有效元素个数
int StackSize(Stack* pst);1.2 初始化栈
在初始化栈时我们要考虑栈顶top的初始值
当top = 0 时,此时top 指向栈顶元素的下一个当top = -1 时,此时top 指向栈顶元素本次我们用top = 0来演示
void StackInit(Stack* pst)
{
assert(pst);
pst->a = NULL;
pst->top = 0; //top 指向栈顶元素的下一个
//pst->top = -1; //top 指向栈顶元素
pst->capacity = 0;
}1.3 入栈
入栈时首先考虑栈的容量,容量不足时应该扩容,再更改top的指向
void StackPush(Stack* pst, STDataType x)
{
if (pst->capacity == pst->top)
{
int newCapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;
STDataType* tmp = (STDataType*)realloc(pst->a, newCapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
pst->a = tmp;
pst->capacity = newCapacity;
}
pst->a[pst->top] = x;
pst->top++;
}1.4 检测栈是否为空
因为出栈时会用到这个功能,所以先讲是否为空的判定,而判空只需要知道top当前的值是否为0
bool StackEmpty(Stack* pst)
{
assert(pst);
return pst->top == 0;
}1.5 出栈
出栈时,要先判断栈是否为空,然后再让top–即可
void StackPop(Stack* pst)
{
assert(pst);
assert(!StackEmpty(pst));
pst->top--;
}1.6 获取栈顶元素
判断栈是否为空,然后返回栈顶元素即可,而此时则需跟之前top的初始值关联
STDataType StackTop(Stack* pst)
{
assert(pst);
assert(!StackEmpty(pst));
return pst->a[pst->top-1];
}1.7 获取栈中有效元素个数
栈中有效元素个数是与top有联系的 top初始值为0,则直接返回top, top初始值为-1,则直接返回top+1
int StackSize(Stack* pst)
{
assert(pst);
assert(!StackEmpty(pst));
return pst->top;
}1.8 销毁栈
直接释放即可
void StackDestroy(Stack* pst)
{
assert(pst);
free(pst->a);
pst->capacity = pst->top = 0;
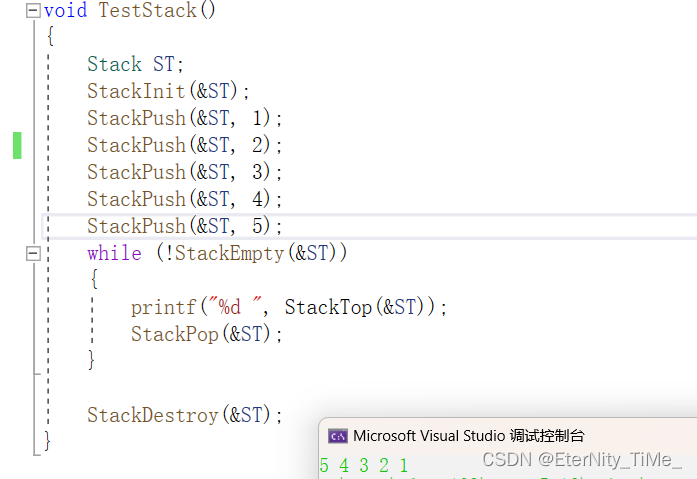
}测试栈的功能
符合栈的特点,先进后出
二、队列的实现
队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数组头上出数据,效率会比较低。

2.1 创建结构体
此处则需定义两个结构体,一个表示队列,另一个表示队列的结构
typedef int QDataType;
typedef struct QNode
{
struct QNode* next;
QDataType data;
}QNode;
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;
}Queue;本次所需实现的功能有以下:
// 初始化队列
void QueueInit(Queue* pq);
// 销毁队列
void QueueDestroy(Queue* pq);
// 队尾入队列
void QueuePush(Queue* pq, QDataType x);
// 队头出队列
void QueuePop(Queue* pq);
// 获取队列头部元素
QDataType QueueFront(Queue* pq);
// 获取队列队尾元素
QDataType QueueBack(Queue* pq);
// 获取队列中有效元素个数
int QueueSize(Queue* pq);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* pq);2.2 初始化队列
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}2.3 入队列
入队列时,要先创建元素,再分情况讨论,要判断队列原来是否已有元素 再移动队尾指针
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->data = x;
newnode->next = NULL;
if (pq->phead == NULL)
{
assert(pq->ptail == NULL);
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
pq->size++;
}2.4 检测队列是否为空
判断队列是否为空有两种方法;
- 判断头尾指针是否都为空
- 队列的元素个数为0
bool QueueEmpty(Queue* pq)
{
assert(pq);
/*return pq->phead == NULL
&& pq->ptail == NULL;*/
return pq->size == 0;
}2.5 出队列
出队列时,先判断队列是否为空,还要分情况讨论一个结点还是多个结点
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
//1.一个结点
//2.多个结点
if (pq->phead->next == NULL)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else
{
//头删
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
pq->size--;
}2.6 获取队列头部元素
判断队列是否为空,再直接返回头结点的值
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->phead->data;
}2.7 获取队列队尾元素
判断队列是否为空,再直接返回尾结点的值
在这里插入代码片QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->ptail->data;
}2.8 获取队列中有效元素个数
返回size的值
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}2.9 销毁队列
与链表的销毁方式差不多
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = pq->ptail = NULL;
pq->size = 0;
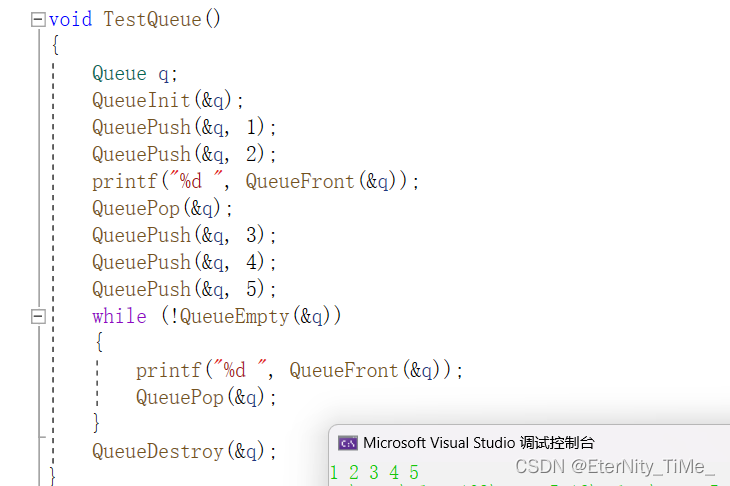
} 测试队列的功能
符合先进先出的特点
总结
栈的优点: 栈的操作非常简单,只需要对栈顶进行操作,效率较高。 栈可以非常方便地实现递归操作。 栈可以用于判断括号匹配、表达式求值、深度优先搜索等场景。
队列的优点: 队列可以实现数据的先进先出,保证了数据的有序性。 队列可以用于广度优先搜索、循环队列等场景。 队列的插入和删除操作都在不同的端进行,避免了栈可能会发生的栈满的情况。
栈和队列在实际应用中都有各自的优点和缺点,需要根据实际情况进行选择。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号