Postgresql源码(135)生成执行计划— —Var的调整set_plan_references

Postgresql源码(135)生成执行计划— —Var的调整set_plan_references

mingjie
修改于 2024-10-10 16:33:48
修改于 2024-10-10 16:33:48
1 总结
- set_plan_references主要有两个功能:
- 拉平:生成拉平后的RTE列表(add_rtes_to_flat_rtable)。
- 调整:调整前每一层计划中varno的引用都是相对于本层RTE的偏移量。放在一个整体计划后,需要指向一个统一的RTE列表,所以需要把varno调整下指向拉平后的RTE表。
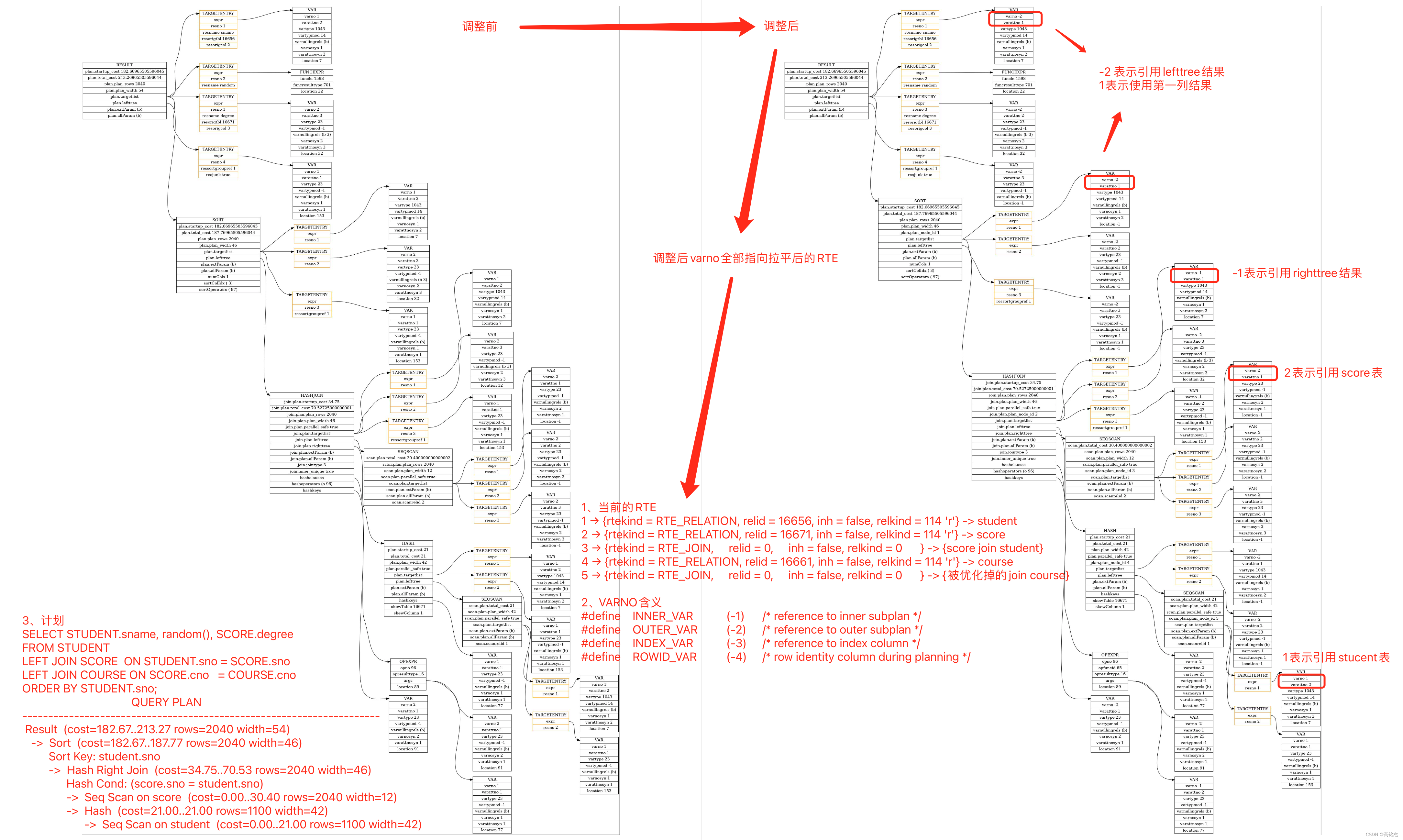
- 例如下面计划中,RTE记录了6张表:
- 1 → `{rtekind = RTE_RELATION, relid = 16656, inh = false, relkind = 114 ‘r’} -> student
- 2 → `{rtekind = RTE_RELATION, relid = 16671, inh = false, relkind = 114 ‘r’} -> score
- 3 → `{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0 } -> {score join student}
- 4 → `{rtekind = RTE_RELATION, relid = 16661, inh = false, relkind = 114 ‘r’} -> course
- 5 → `{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0 } -> {被优化掉的join course}
- Result节点的第一列是STUDENT.sname,他的varno一开始是1,varattno是2,显然他不应该直接引用RTE中的某一张表,因为Result节点的数据应该使用下面SORT节点中取出来的,所以:
- varno被调整为-2(表示引用OUTTER节点也就是LEFT树返回的结果)
- varattno被调整1,表示从结果中拿第一列。
explain
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY STUDENT.sno;
QUERY PLAN
------------------------------------------------------------------------------------
Result (cost=182.67..213.27 rows=2040 width=54)
-> Sort (cost=182.67..187.77 rows=2040 width=46)
Sort Key: student.sno
-> Hash Right Join (cost=34.75..70.53 rows=2040 width=46)
Hash Cond: (score.sno = student.sno)
-> Seq Scan on score (cost=0.00..30.40 rows=2040 width=12)
-> Hash (cost=21.00..21.00 rows=1100 width=42)
-> Seq Scan on student (cost=0.00..21.00 rows=1100 width=42)上面用例经过set_plan_references调整前后的完整例子:
2 数据结构
PlannerInfo
当前查询优化的状态,包含了当前查询的所有信息:
- 当前查询的目标列表(target list)
- 子句(例如,WHERE、GROUP BY、ORDER BY 等)
- 范围表(range table)
- 可用的索引信息
- 统计信息
- 子查询和参数信息
- 优化器的各种临时数据和结果
PlannerGlobal
全局结构,包含了跨多个查询级别的信息。例如一个包含子查询或CTE的查询中,每个子查询都会有自己的 PlannerInfo结构,会共享同一个PlannerGlobal。包含了:
- 全局范围表(finalrtable)
- 全局子计划列表
- 全局初始化计划列表
- 全局参数表达式列表
- 重写规则和其他全局状态信息
varno宏
#define INNER_VAR (-1) /* reference to inner subplan */
#define OUTER_VAR (-2) /* reference to outer subplan */
#define INDEX_VAR (-3) /* reference to index column */
#define ROWID_VAR (-4) /* row identity column during planning */3 set_plan_references
1 计算全局flat_rtable
set_plan_references → add_rtes_to_flat_rtable
首先把引用的rtable全部拉平到一个级别,重新排列RTE。
具体在PlannerGlobal中构造全局范围表finalrtable,所有子PlannerInfo共享的一套RTE。
p *root->glob->finalrtable
$7 = {type = T_List, length = 5, max_length = 5, elements = 0x3085520, initial_elements = 0x3085520}add_rtes_to_flat_rtable后生成五个RTE:
- RangeTblEntry
{rtekind = RTE_RELATION, relid = 16656, inh = false, relkind = 114 'r'} - RangeTblEntry
{rtekind = RTE_RELATION, relid = 16671, inh = false, relkind = 114 'r'} - RangeTblEntry
{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0} - RangeTblEntry
{rtekind = RTE_RELATION, relid = 16661, inh = false, relkind = 114 'r'} - RangeTblEntry
{rtekind = RTE_JOIN, relid = 0, inh = false, relkind = 0}
PlannerInfo→PlannerGlobal:
2 开始修正RTE的引用
set_plan_references → set_plan_refs
2.1 处理Result
- set_plan_refs
- →
case T_Result:… 处理result子树 - →
plan->lefttree = set_plan_refs(root, plan->lefttree, rtoffset);递归处理左树 - →
plan->righttree = set_plan_refs(root, plan->righttree, rtoffset);递归处理右树
- →
- 根据内层的sort节点,重新排列result节点的三个var的varno和varattno,result已经是最外层节点了,当前使用到的var还是从sort节点继承的,需要修复下。
处理前 vs 处理后
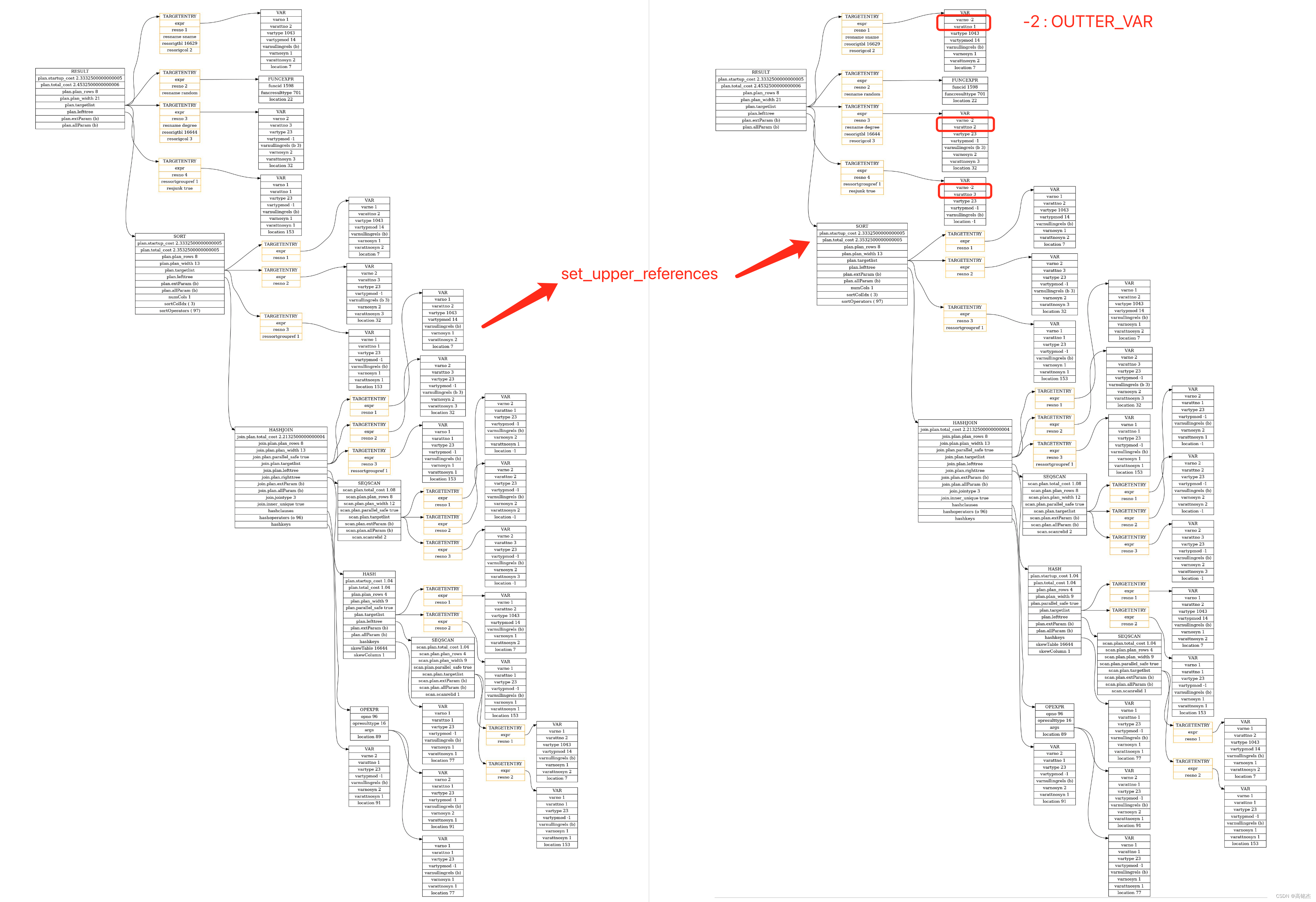
set_plan_refs处理T_Result节点:
set_plan_refs
...
...
case T_Result:
Result *splan = (Result *) plan;
if (splan->plan.lefttree != NULL)
set_upper_references(root, plan, rtoffset);
...
...
// subplan 是 SORT节点
// subplan->targetlist 中返回三列:STUDENT.sname, SCORE.degree, STUDENT.sno
// 注意缺了一列random函数
subplan_itlist = build_tlist_index(subplan->targetlist); - subplan->targetlist
varno = 1, varattno = 2, vartype = 1043varno = 2, varattno = 3, vartype = 23varno = 1, varattno = 1, vartype = 23
- subplan_itlist
subplan_itlist->tlist = subplan->targetlistsubplan_itlist->vars[0] = {varno = 1, varattno = 2, resno = 1, varnullingrels = 0x0}subplan_itlist->vars[1] = {varno = 2, varattno = 3, resno = 2, varnullingrels = ...}subplan_itlist->vars[2] = {varno = 1, varattno = 1, resno = 3, varnullingrels = 0x0}
foreach(l, plan->targetlist)
...
newexpr = fix_upper_expr(...)
...
// 计算完成
plan->targetlist = output_targetlist;- output_targetlist
expr = 0x308f0c8, resno = 1, resname = 0x2f4d670 "sname"varno = OUTER_VAR = -2, varattno = 1, vartype = 1043
expr = 0x308f1b8, resno = 2, resname = 0x2f4d7e8 "random"funcid = 1598, funcresulttype = 701, funcretset = false
expr = 0x308f258, resno = 3, resname = 0x2f4d928 "degree"varno = OUTER_VAR = -2, varattno = 2, vartype = 23
expr = 0x308f2f8, resno = 4, resname = 0x0, ressortgroupref = 1varno = OUTER_VAR = -2, varattno = 3, vartype = 23
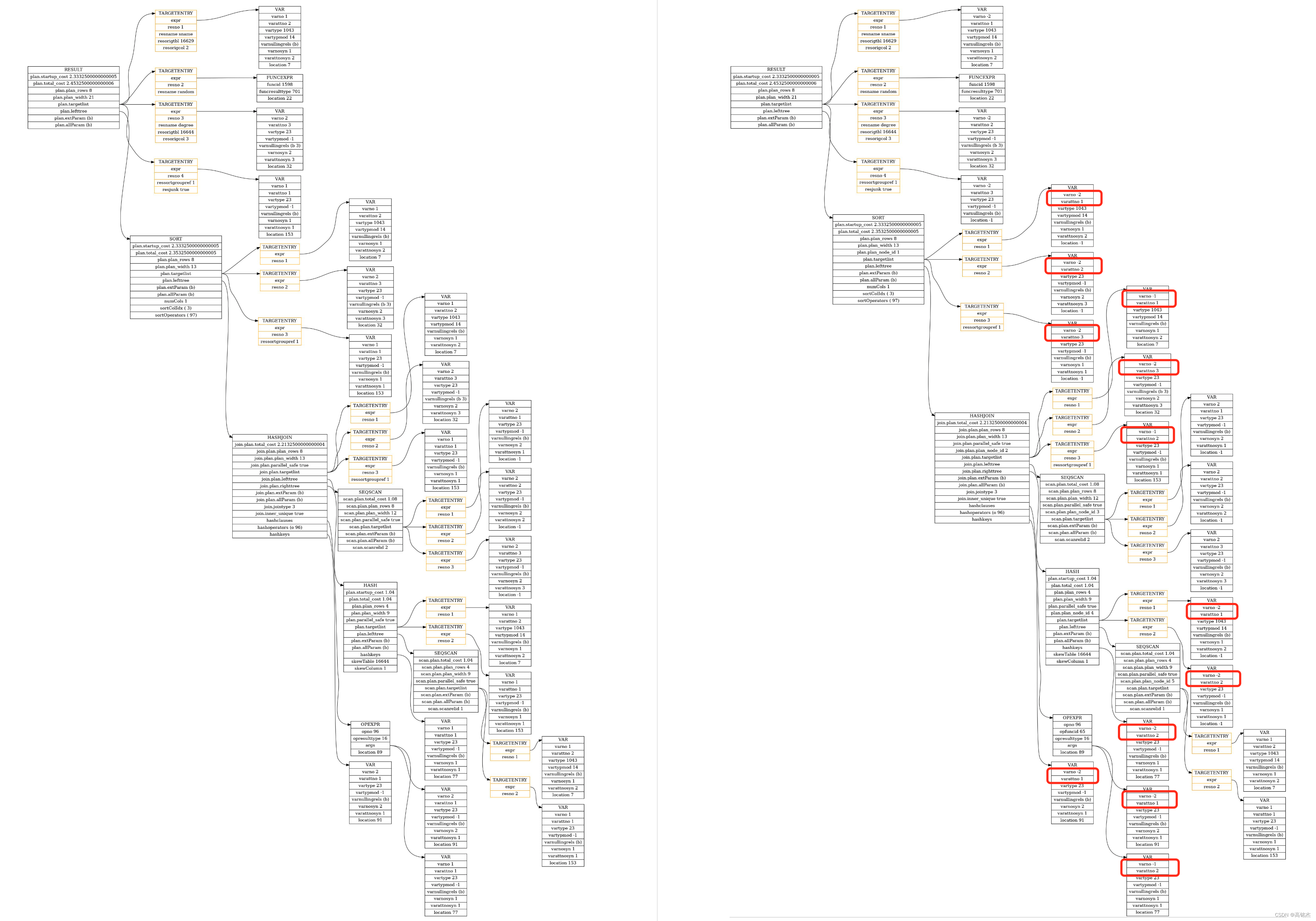
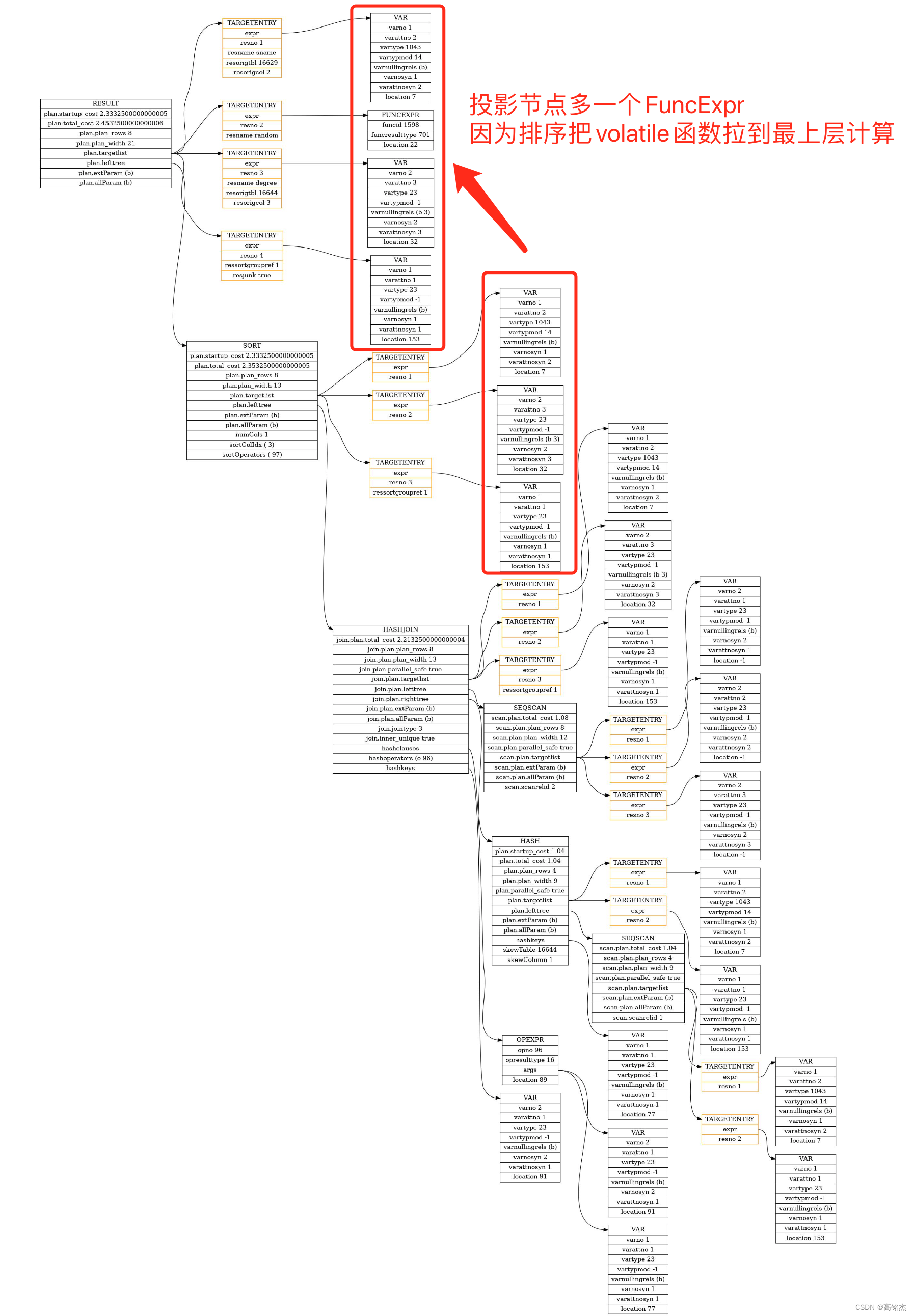
2.2 处理SORT
- set_plan_refs
- →
case T_Sort:… 处理sort子树set_dummy_tlist_references - →
plan->lefttree = set_plan_refs(root, plan->lefttree, rtoffset);递归处理左树 - →
plan->righttree = set_plan_refs(root, plan->righttree, rtoffset);递归处理右树
- →
排序只需要引用下面一层的结果即可。
// These plan types don't actually bother to evaluate their
// targetlists, because they just return their unmodified input
// tuples. Even though the targetlist won't be used by the
// executor, we fix it up for possible use by EXPLAIN (not to
// mention ease of debugging --- wrong varnos are very confusing).
set_dummy_tlist_references2.3 处理Hash Right Join
- set_plan_refs
- →
case T_HashJoin:… 处理join子树set_join_references - →
plan->lefttree = set_plan_refs(root, plan->lefttree, rtoffset);递归处理左树 - →
plan->righttree = set_plan_refs(root, plan->righttree, rtoffset);递归处理右树
- →
4 用例
explain
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY STUDENT.sno;
QUERY PLAN
------------------------------------------------------------------------------------
Result (cost=182.67..213.27 rows=2040 width=54)
-> Sort (cost=182.67..187.77 rows=2040 width=46)
Sort Key: student.sno
-> Hash Right Join (cost=34.75..70.53 rows=2040 width=46)
Hash Cond: (score.sno = student.sno)
-> Seq Scan on score (cost=0.00..30.40 rows=2040 width=12)
-> Hash (cost=21.00..21.00 rows=1100 width=42)
-> Seq Scan on student (cost=0.00..21.00 rows=1100 width=42)本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-06-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号