Day3-学习R包
原创

1.安装和加载
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/")):
- 这行代码设置了R的选项,指定了用于安装R包的CRAN(The Comprehensive R Archive Network)镜像地址。这里选择的是中国清华大学的镜像服务器,这样做的好处是在国内下载R包时速度会更快。
options(BioC_mirror="http://mirrors.tuna.tsinghua.edu.cn/bioconductor/"): - 这行代码设置了Bioconductor的镜像地址,Bioconductor是一个提供超过1100个R包的生物信息学项目,它与R语言紧密集成。同样,这里选择的也是清华大学的镜像服务器。
install.packages("dplyr"):- 这行代码用于安装名为
dplyr的R包。dplyr是一个流行的数据操作包,提供了一系列的函数用于快速进行数据操作,如选择、过滤、排序、汇总等。 library(dplyr):- 这行代码加载了之前安装的
dplyr包,使其函数可以在当前R会话中使用。
安装Rtools包
https://cran.rstudio.com/bin/windows/Rtools/
Installing package into ‘C:/Users/Lenovo/AppData/Local/R/win-library/4.4’2.熟悉dplyr五个基础函数
mutate() 函数是 dplyr 包提供的一个用于修改数据框(data frame)的函数,它可以创建新的列或者修改现有的列。
mutate(.data, new_column_name = expression)
mutate(test, new = Sepal.Length * Sepal.Width)##在数据框 test 中,创建一个名为 new 的新列,该列的每个值是对应行中 Sepal.Length 和 Sepal.Width 的乘积
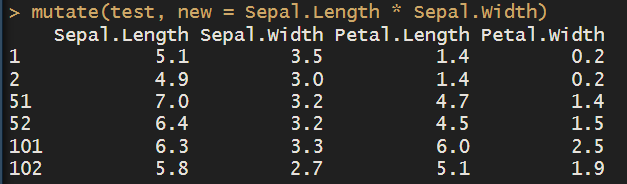
select(test,1)##从数据框 test 中选择第一列。
select() 函数是 dplyr 包提供的一个用于选择数据框(data frame)中特定列的函数。select() 函数的基本语法如下:
select(.data, column_name_1, column_name_2, ...).data:需要选择列的数据框。column_name_1,column_name_2,...:你想要从数据框中选择的列的名称。
filter(test, Species == "setosa")####从数据框 test 中选择setosa行。
filter(.data, condition).data:需要筛选行的数据框。condition:一个逻辑表达式,用于判定每行是否应该被包含在结果中。

arrange(test, Sepal.Length)###按照Sepal.Length列从小到大排序
summarise(test, mean(Sepal.Length), sd(Sepal.Length))# 计算Sepal.Length的平均值和标准差
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号