ASI 8年计划 paper7 生成模型、语言交流和主动推理

ASI 8年计划 paper7 生成模型、语言交流和主动推理

CreateAMind
发布于 2024-03-06 15:18:01
发布于 2024-03-06 15:18:01
生成模型、语言交流和主动推理
Generative models, linguistic communication and active inference
相比之下,通过将语言构建为一个主动(贝叶斯)推理问题,具有潜在生成模型的框架,我们的方法推断输入和输出之间的因果关系,并提供所呈现的单词序列及其上下文敏感性的结构性理解。这导致解决不确定性的行动,从而产生具有前瞻性的对话
换句话说,不需要手工制作任何规则或语法,也不需要提供任何强化或反馈,本文展示的所有行为都是由生成模型的结构产生的
not deal explicitly with belief states updating cannot be used to create artefacts that communicate。例如,在语音识别中使用深度学习可能会提供有关在听觉水平上的语言处理的计算架构的引人注目的见解;然而,语音识别并不构成理解。换句话说,仅仅将听觉输入映射到单词列表并不构成生成模型的反演。
元认知的一个重要方面是知道自己何时不确定。在上述模拟中,代理通过彼此提供不具信息性的(“不确定”)答案来保持他们的不确定性。然而,他们并不知道自己不确定(即,他们的生成模型没有隐藏的“不确定状态”)。更复杂的生成模型会意识到某些事情缺乏信心,并以“我真的不知道”的方式回应。这种表面上简单的能力建立在一个本质上是元认知的信心生成模型之上;因为反转这种深度生成模型会产生关于信念的(后验)信念。

https://www.sciencedirect.com/science/article/pii/S0149763420304668
ABSTRACT摘要 (2万6千字)
本文提出了一个生物学上可信的生成模型和推理方案,能够模拟相互交谈的合成主体之间的交流。基于二元交互的主动推理公式,我们模拟语言交换来探索支持对话的生成模型。这些模型在深层(分层)模型中的抽象(离散)状态之间采用高阶交互。语言处理的顺序性质要求生成模型具有特定的因子结构——这是适应丰富的语言组合学所必需的。我们通过模拟一个能玩“二十个问题”游戏的合成主体来说明语言交流。在这个游戏中,合成主体扮演提问者或回答者的角色,使用相同的生成模型。这种模拟设置用于说明一些关键的架构点,并证明在变化的(边缘)消息传递下,给定正确类型的生成模型,语言交流的许多行为和神经生理关联会出现。例如,我们表明,当倾听他人时,θ-γ耦合是信念更新的一个自然属性。
关键词:消息传递 推理 连接性 自由能 神经元 分层的 贝叶斯 语言
一、Introduction简介
2018 年 4 月,一个国际专家组齐聚法兰克福,参加 Ernst Strüngmann 论坛,讨论大脑皮层的复杂性和计算问题(Singer 等,2019)。一个小组听取了关于讨论人类认知的简报,并根据该小组的兴趣,选择关注语言处理 对于计算神经科学、语言学和理论神经生物学来说是一个具有挑战性的领域(Hauser et al., 2002)。接下来是正式的分析,阐述了该小组的一个关键结论;也就是说,只要有正确的生成模型,语言处理和功能性大脑结构的神经元相关性就会自然出现。简而言之,本文利用语言交流的模拟来表明,语言处理的许多行为和神经生理学相关性是在深层历时模型下出现的。
生成模型是指从原因(例如语义)到结果(例如听觉信号)的概率映射。然后,感知、识别或推理就变成了生成模型的(贝叶斯)反转,以从结果推断原因。生成模型的概念基于对大脑作为建设性器官的承诺,为其感觉生成解释。我们将使用这一基本思想的主动推理(又称预测处理)表述它继承了有关大脑如何运作的心理学思想的悠久传统;从康德到亥姆霍兹(Helmholtz,1878 (1971)),从综合分析(Yuille and Kersten,2006)到作为假设检验的感知(Gregory,1980),从亥姆霍兹机器(Dayan et al.,1995)到自由能量原理(弗里斯顿,2010)。具体来说,我们将使用自由能原理的推论;即主动推理(Friston et al., 2017a)。主动推理背后的基本思想是,在规范意义上,任何神经元处理都可以表述为近似贝叶斯推理中使用的相同数量的最小化;即,变分自由能或证据界限(Mattys 等人,2005 年; Winn 和 Bishop,2005 年)。
最小化变分自由能相当于最大化内部模型的感觉证据,该内部模型说明世界的未观察到的(即隐藏的)状态如何产生观察到的(即感觉的)结果。从技术上讲,这可以通过最大化生活世界模型的边际可能性来表述 这被巧妙地概括为不言而喻self-evidencing的(Clark,2016; Hohwy,2016);换句话说,为我们的生成模型收集感官证据。指定生成模型后,我们可以使用标准的“现成”信念更新方案(Friston 等人,2017c)来创建合成代理,该代理以使用模拟来测试有关沟通的假设;例如与概念知识相关的语言短语的生成和理解(Barsalou,2003; Yufik,1998,2019 ),使用不言而喻的方式感知和行动。这些模拟还可用于预测经验行为和生理反应。在这里,我们共享叙事(Mar et al., 2011; Mathewson et al., 2019),以及语言的线性化(Bornkessel 等,2005)。
这篇论文延续了自然语言处理(以及响应生成)领域的长期研究。先前的重点是将自然语言处理视为一个学习问题(Elman,1990),在这方面,深度学习的运用推动了算法的发展(Young等,2018):例如,从学习预测关系中导出的词嵌入(Collobert等,2011;Mikolov,2010;Mikolov等,2013;Pennington等,2014)和完全上下文化的词表示(Devlin等,2018;Radford等,2019;Vaswani等,2017)。这些方法限制自己于通过训练特定神经网络学习输入和输出之间的关联。相比之下,响应生成——包括对话式对话代理——被构建为深度强化学习(Li等,2016;Zhao等,2017)或推理问题(Liu等,2018)。尽管这些方法与我们的工作密切相关,但它们正在优化不考虑未来的客观函数,包括它们具有前瞻性对话的能力,由于词重复或封闭式回复(Li等,2016)。相比之下,通过将语言构建为一个主动(贝叶斯)推理问题,具有潜在生成模型的框架,我们的方法推断输入和输出之间的因果关系,并提供所呈现的单词序列及其上下文敏感性的结构性理解。这导致解决不确定性的行动,从而产生具有前瞻性的对话:正如接下来的模拟所示,代理不需要重温已解决的问题。
所得到的方法也与先前的语言处理认知理论有所不同。尽管“惊奇”的概念在文献中变得越来越普遍(Hale,2001;Levy,2008),但这通常指的是个别单词传达的“惊奇”程度,因此预期的语义仅仅是由所有前面的单词传达的语义的综合。相比之下,在当前的表述中,信念更新发生在更高的水平,并依赖于关于声学场景的信念,关于这个场景,代理已经有先验信念。
请注意,在这里使用的数学公式与先前在这一领域使用的方法不同。这里有两个关键点需要注意。首先,当前的表述考虑了代理对手头场景的信念的不确定性。其次,我们引入了一个主动组件——它生成关于代理将寻求解决其不确定性的信息的预测。换句话说:我应该问什么问题,来解决我们对话主题的不确定性?
这篇论文包括四个部分。第一部分(语言的生成模型)描述了一种自顶向下的方法,以生成模型的形式理解功能性大脑结构,特别关注适用于语言交流的模型。这一部分考虑了必要的计算架构,第二部分(主动推理)描述了相应的消息传递。第三部分(“二十个问题”模拟)利用生成模型阐明了言语和听力行为及神经生理学相关性(Edwards和Chang,2013;Kayser,2019;Lizarazu等,2019;Pefkou等,2017)。该部分以演示模型如何预测被解释为θ-γ耦合的响应而结束(Giraud和Poeppel,2012;Lizarazu等,2019;Pefkou等,2017)。它还重现了一些简单的违反范例,以合成事件相关电位和差异波形的形式呈现,这些范例类似于失配负性、P300和N400研究中观察到的模式(Coulson等,1998;Van Petten和Luka,2012)。最后一部分(合成交流)转向交流本身,利用两个合成主体之间的二元互动来说明某些类型的信念更新可以以语言形式实现。我们最后讨论了尚未解决的问题;例如,代理感和通过学习深度模型获得语言的习得。
2. Generative models of language语言的生成模型
在对语言交流进行建模之前,我们首先从一个简化的生成模型开始,该模型描述了个体合成代理如何生成口头短语。这个生成模型并不打算成为一个全面的语言模型,而是指定了允许我们模拟语言交流的计算架构的关键组成部分。专注于生成模型的优势在于,与识别模型相比,同一个生成模型可以用于根据叙述生成听觉信号(即用于语言产生),也可以用于根据听觉输入推断叙述(即用于语言理解)。在这里,我们专注于模拟一个简单的代理,它可以提问并回答问题。在这种表述中,代理不知道它的信念是自己的还是由某个外部叙述者生成的。我们将在讨论中回到这个问题。
那么,语言生成模型的特殊要求是什么?在这里,我们采取一种常识性的方法,并列出这样一个模型必须具备的必要属性。从生成模型开始,有点简化了事情,因为人们只需要指定生成有意义语言所需的条件。然后,可以通过应用已建立的反演方案来模拟基本的语言理解。首先,我们假设语言是用于交流的,这立即意味着存在一个共享的前瞻性叙述(Allwood等,1992;Brown和Brune,2012;Friston和Frith,2015a;Mar等,2011;Schegloff和Sacks,1973;Specht,2014)。反过来,这意味着关于交流主题的共享(并不断发展的)信念(Mathewson等,2019)。这个简单的观察具有一些基本的含义。第一个可能有点反直觉,并借鉴了早期关于神经解释学的工作(Friston和Frith,2015a)。这项工作——利用广义同步来模拟鸣禽之间的交流——表明,只要共享相同的生成模型,就足以推断交互者之间的感觉交换的含义。谁在说话以及代理的归因问题随后变成了一个次要问题,只有在轮流交流时才是必要的(Ghazanfar和Takahashi,2014;Wilson和Wilson,2005)。简而言之,叙述不能被唯一归因于你或我——它是我们的叙述。
共享叙述的概念对我们的生成模型的构建至关重要。通常,在实现或模拟主动推理时(在真实工件或模拟环境中),结果是由代理导航的世界的外部状态生成的。然后使用这些感觉结果来更新关于外部状态的信念,然后用于规划行动。策略——这些是行动序列——改变外部状态并生成新的结果。因此,感知-行动循环继续进行。然而,在二元交换的背景下,结果是由另一个人或代理生成的,而无需参考外部状态。在这种情况下,当一个人工代理说话时,它生成的结果最符合其信念,进而更新其对话对象的信念。这种交换的结果是信念状态的同步或对齐,在纯粹的交流中,它避开了对世界外部状态的任何参考。
这种一致性自然而然地来自于生成与信念一致的结果(从技术上讲,是具有最大边际似然或模型证据的结果)。假设行动和结果是同构的。基于这些结果的后续信念更新使得两个主体的信念与他们共享的结果一致。简而言之,结果和信念被协调选择以最大化模型证据,隐含地增加感觉样本的可预测性。这种相互交换的不可避免的结果是收敛到相同的信念状态(Isomura等,2019),这确保了一个代理生成的结果很容易预测,因为这些是代理本身会产生的相同结果。这种广义同步已经在对鸟鸣和细胞内交流的通信进行的数值分析中进行了探索(Friston等,2015;Friston和Frith,2015b;Isomura等,2019;Kuchling等,2019)。在本文中,我们专注于纯粹的交流;在这种情况下,所有的结果都是由一个或另一个代理生成的意思。这意味着没有其他的世界状态需要考虑。请参见图1,以图形方式描述了纯粹交流所暗示的特殊条件依赖关系。
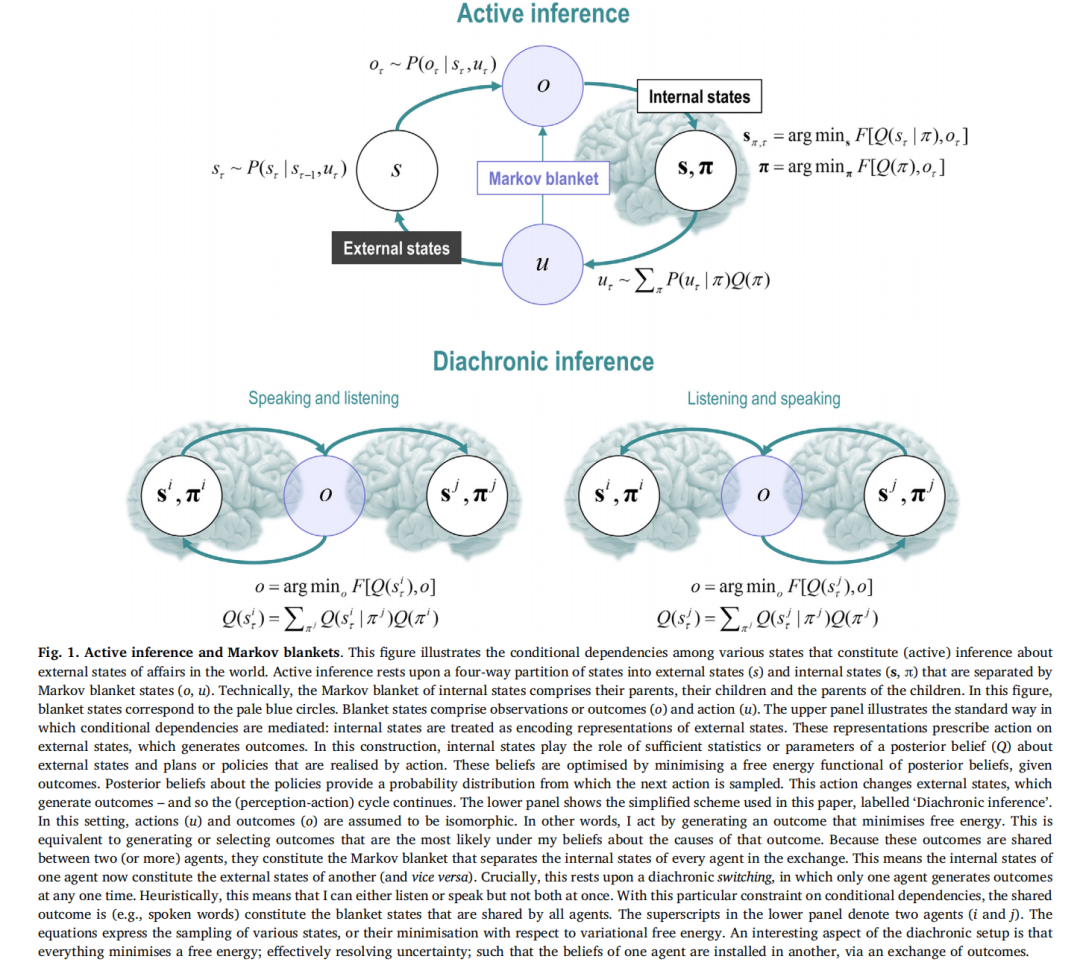
在下文中,我们试图展示两个或多个主体的信念状态如何通过纯粹的沟通而变得一致,其中这种对齐是选择与听到的一致的信念的自然属性,同时生成与这些信念相一致的产出。如果两个或多个代理遵守这些命令,他们的信念就会一致,从而表现出最低限度的沟通形式。考虑外部国家states如何参与游戏是很有趣的。例如,提供视觉线索影响一个代理人的信念:即,一个人如何向另一个人传达她对所看到的事物的信念,或者当他们看到同一场景的不同部分时,他们如何达成共识?然而,在这项工作中,我们将只考虑没有外部状态的纯粹通信,并关注如何通过共享叙事建立对场景的信念。
那么,什么是叙事呢?从主动推理的角度来看,我们所做的一切都可以被视为追求一种解决不确定性的叙事(Friston et al., 2017a; Mirza et al., 2016)。这意味着唯一重要的叙事是具有认知可供性的叙事。即,在关于世界的特定信念结构下减少不确定性的机会。从这个意义上说,语言的形式命令变得与任何主动推理完全相同。例如,主动视觉(Ferro 等人,2010; Ognibene 和 Baldassarre,2014)。事实上,科学探究中的实验设计也遵循同样的原则,即收集数据来消除相互竞争的假设的歧义(Lindley,1956)。下面的生成模型的大部分动机继承了在场景构建过程中通过眼球扫视运动查询世界的形式上相同的问题(Mirza et al., 2016; Ognibene and Baldassarre, 2014; Purpura et al., 2003)。简而言之,我们将把语言视为作用于世界以解决不确定性,其中认知搜寻已从视觉触诊(即主动视觉中的视觉搜索)提升为通过语义和符号学对世界的审问,这是通过文化学习获得的。 Constant 等人,2019; Creanza 和 Feldman,2014; Penn 等人,2008; Rizzolatti 和 Craighero,2004)。按照这个类比得出结论,可以用一系列“问题”和“答案”(即命题和响应)来构建一个最小但足够的交流语言模型,就像用我们的感觉上皮细胞构成了“关于外面是什么的问题” (Gregory,1980)。随后的感官样本为我们对世界的信念提供了一些显着的、减少不确定性的证据。
考虑到这一点,我们给自己设定的任务是制定一个可以玩“二十个问题”游戏的生成模型。换句话说,一个模型可以生成一系列问题和封闭式“是/否”答案,从而逐渐减少对话主题(即上下文知识)的不确定性。此类顺序通信游戏已在文献中得到广泛解决:包括一轮问答“威士忌定价”交互(Hawkins 等人,2015)、通过一次性通信玩受限“纸牌语料库” (Potts,2012)、顺序“信息拼图”游戏(Khani 等人,2018)、 “帽子游戏”,其中智能体通过观察动作学习交流(Foerster 等人,2016)以及有关视觉刺激的对话(Das 等人)等,2017)。在为我们的“二十个问题”范式指定了生成模型后,我们没有做进一步的假设 我们使用现成的(边缘)消息传递来模拟神经元处理(Dauwels,2007; Friston 等人,2017c; Parr)和弗里斯顿,2018 年;温恩和毕晓普,2005 年)。对于部分观察的马尔可夫决策过程,完全相同的信念更新方案已在许多情况下使用;范围从迷宫探索和经济博弈论,到抽象规则求解和场景构建(Friston 等人,2017a)。我们预计这些模拟将重现经验语言研究中看到的关键行为和神经元反应。
2.1. A deep diachronic model of language for communication
2.1. 交流语言的深层历时模型
简而言之,我们的生成模型必须生成一系列问题和答案,并限制它们被表达为连续结果的离散序列;在这里,口语。这意味着叙述出现在多个(即离散和连续)级别上,这说明了必要模型的深层或层次方面。这种分层构建会话对话问题的方法之前已经通过使用人工神经网络包含两个独立的(快速和慢速)级别进行了探索(George et al., 2017; Serban et al., 2016; Sordoni et al., 2015)。为了说明这种深层结构和时间尺度的隐式分离,我们考虑了生成一系列取决于世界信念的问题和答案的问题。世界各国有多种风格。我们将这些状态称为隐藏因素,其中每个因素(例如“颜色”)都有许多离散状态(例如“红色”、“绿色”、“蓝色”⋯⋯)。在变分机器学习文献中,因子的使用被称为平均场近似(Jaakkola 和 Jordan,1998; Kschischang 等人,2001; Sallans 和 Hinton,2004; Zhang 等人,2018) ,并且对于简化生成模型的形式并进行推理。事实上,使用变分贝叶斯的近似贝叶斯推理的概念是根据这种因式分解在操作上定义的。
指定生成模型的问题现在简化为指定足以生成特定问题或答案的因素specifying the factors that are sufficient to generate a particular question or answer.。其中包括问题的形式、内容以及决定正确答案的世界信念。通过在句子的形式和内容之间进行因式分解,能够巧妙地用组合数学来表示所有可能的问题和所有可能的内容。换句话说,我们假设大脑在某个适当的高层次上分别呈现问题的形式及其内容,两者仅在为下面的层次级别生成结果或上下文时才相互作用。
在本文中,我们考虑两个层次;即,概念层生成语法和语义,较低层生成单词或短语的词汇序列。人们可以考虑更进一步的层次,一直到音素和发音;然而,这种级别的建模已经在主动聆听的背景下得到考虑(Friston 等人,2020)因此,我们将把当前的分析限制在完全形成的单词的生成和理解上(请注意,伴随的 Matlab 模拟)本文包括完整的三级演示,支持口头回答和问题:请参阅软件说明)。
那么,要生成一个句子,需要知道什么?基本上,我们需要问题的时间结构或语法、语义内容(填充名词和动词等实词)以及答案(例如“是”或“否”)。然而,为了生成语法和语义,我们需要叙述(例如,这是一个问题还是答案?)和问题的形式(例如,这是一个关于某物在哪里(即位置)或某物是什么的问题)即形状?)。我们还需要知道所描述的世界的状态(例如,上下文或场景知识)以及正在讨论哪些特定属性。这些概念构造构成了生成模型的最高层次;也就是说,人们需要知道的一切来指定较低级别的语法和语义。
在此类深层模型中,更深层次的层次是由在逐渐更长的时间尺度上变化的因素构成的(Friston 等人,2017d; George 和 Hawkins,2009; Kiebel 等人,2009)。这意味着较高级别的因素是句子或短语的属性,而较低级别的因素可能会因单词而异(Chien 和 Honey,2020; Davis 和 Johnsrude,2003; Demirta 等人,2019; Specht,2014; Stephens 等人) .,2013)。这里,高层因素包括叙事结构;即这句话是提示、问题还是答案?
如果这句话是一个疑问句,那么这个疑问句是关于什么的;例如,物体的位置或颜色?如果叙事需要一个答案,那么就必须存在编码世界状态的风景因素,从而使答案正确或错误;例如,该物体是“红色”。最后,也许也是最重要的一点是,必须有支持共同叙事的因素;即共同讨论的主题。我们将这些称为符号学因素,以强调这种因素支持沟通(Roy,2005; Steels,2011)。换句话说,符号学因素蕴含着仅存在于话语语境中的潜在状态。例如,“我们正在讨论某物的颜色”。
这四种因素(叙事、问题、场景和符号(narrative, question, scenic and semiotic)足以指定关于某事的问题,或在关于某事的信念下产生的答案。至关重要的是,其中一些因素取决于选择或政策,而其他因素则不然。例如,智能体可以选择问题的形式及其符号内容,但不能改变场景状态(即正在讨论的场景或概念)。此外,我们假设叙述不能改变,因为问题总是由提示提出,然后是答案。通过这种特殊的构造,智能体可以根据他们对当前符号状态的信念和对问题的回答来更新他们对风景状态的信念。换句话说,世界的隐藏状态可以通过共享符号学进行交流,而共享符号学依赖于共享生成模型下问题的合法答案。人们可以凭直觉看出,这种生成模型需要起作用的因素之间进行高阶交互才能生成句子。换句话说,产生一系列真实问题和答案的偶然事件必然需要多个因素之间的相互作用或结合。接下来的大部分内容都试图使用工作示例来说明这些交互。
指定了句子的形式和符号内容后,现在可以在句子的从属级别生成一系列单词。配备词汇状态之间概率转换的生成模型。词与词之间的隐式转换是由更高层次的叙述和问题因素规定的,以生成句法,而语义内容则由符号学指定。在下面的示例中,这两个属性(句法和语义)构成了模型较低层的隐藏因素。最后,考虑到这两个因素,我们可以生成适当的单词词汇序列;再次,通过(句法和语义)因素的相互作用。
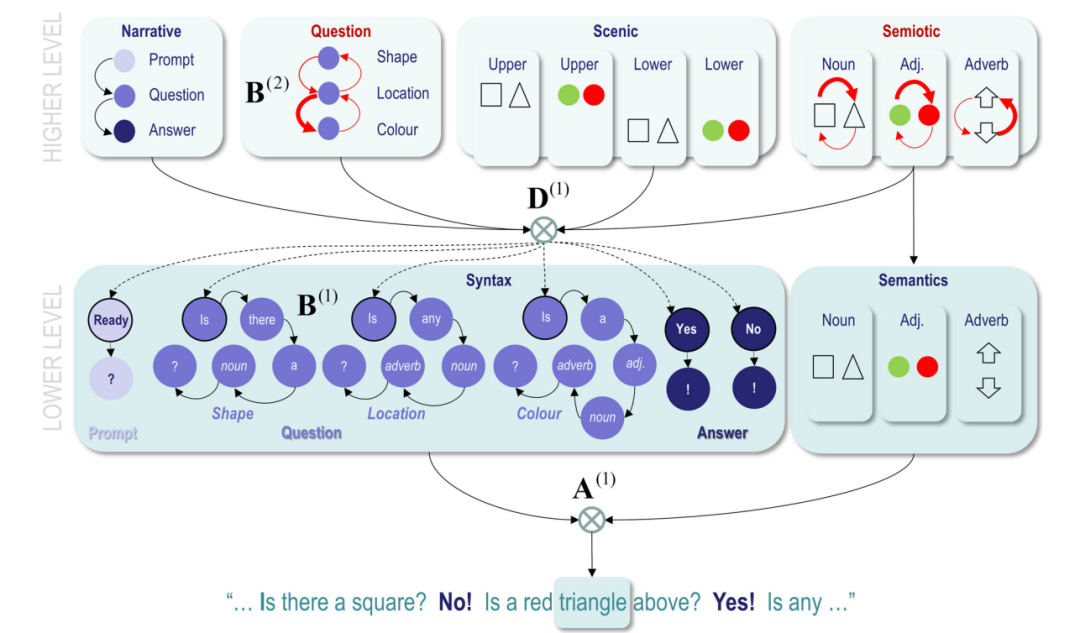

2.2. A generative model for “Twenty Questions” “二十个问题”的生成模型
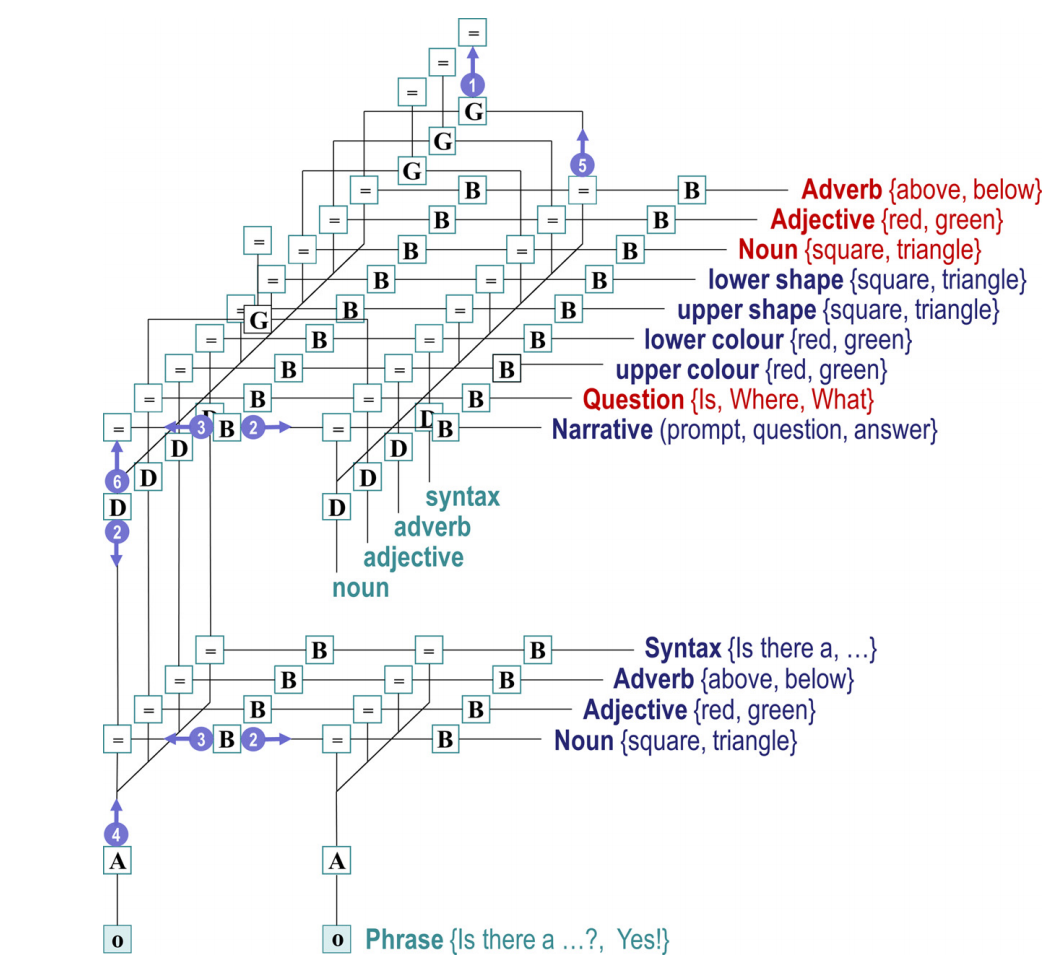
图2提供了这种生成模型的示意图,并填补了一些细节(请参见图例)。这个例子将在后面用来说明“二十个问题”的简化版本,其中一个主体必须通过回答提示中提出的一系列封闭问题来确定两个隐藏对象的配置。这两个对象放在彼此之上,每个对象可以是一个正方形或一个三角形,可以是红色或绿色。这意味着一个理想的(主动)贝叶斯观察者应该能够通过四个问题揭示配置:两个问题用于确定下部对象的颜色和形状,另外两个问题用于确定上部对象的颜色和形状。然而,这取决于根据先前答案更新的信念提出正确的问题。我们希望展示和描述的正是这种认知、减少不确定性的交流方面。
图2生成模型中的因子的特定层次已经构建成一个模型,展示了一个代理如何将对景观状态(即隐藏对象的配置)的信念传达给另一个代理。在更高的层次上,模型包含了关于正在进行的叙述部分(提示、问题或答案)、问题类型(形状、位置或颜色)、世界的假设景观状态以及指示讨论主题的符号因子的信念。这些因素为较低层次生成期望:即句法(即单词的排序和内容)和语义(即代理被询问的形状、颜色和位置)。因此,较低层次生成了单词序列,这些单词被连接在一起形成短语,并且短语序列(即交换)在更高层次循环通过较低层次时发生。
请注意,此处包含的“语法”在传统定义下并不全部被视为语法。在当前的实现中,语法只是状态(单词)的序列,语法用作终止状态表明对话轮已经结束。
该模型中的句法结构仅限于三种问题和两种答案;然而,即使曲目有限,组合起来也并非微不足道。为了提出一个特定的问题,主体必须通过选择适当的策略来选择问题的形式和三个符号学因素的水平。为了理解任何答案,它还必须记住这些选择。 这种记忆是由更高水平赋予的,在承诺特定政策后,该水平保持对可控(即问题和符号)因素的信念。所选择的政策最大限度地减少了不确定性,因此会随着对隐藏场景的信念、连续的问答而改变,确保前瞻性的交流(Allwood et al., 1992)。请注意,这种工作记忆和认知行为是自然产生的最大化模型证据(即最小化变分自由能),给定产生结果的世界连续状态的生成模型。我们添加一个提示状态只是为了演示提示、问题和答案之间的循环。在这个表述中,提示没有传达任何有趣的信息:它只是结构化的一部分对话。在下面的模拟中,我们只是用它来传达现实环境中常见的轮流类型。
显然,我们可以通过多种方式来划分支持语言交流的因素或原因,但我们忽略了许多有趣的方面;然而,基本信息是人们需要在剖析语言的计算架构之前,考虑生成模型的因式分解和深层(层次)性质。接下来,我们更广泛地考虑如何生成此类模型可以以图形形式表示,以及变分消息传递如何生成神经元动态的预测。
3. Active inference主动推理
前面的部分考虑了生成模型的形式。现在我们可以使用主动推理来模拟在该模型下的行动和感知。这里使用的程序假设大脑限制自己只处于有限数量的特征状态中(Friston, 2013)—这是所有有感知系统必须具备的特性。从数学上讲,这些程序最小化惊奇(以信息论术语),这等同于最大化贝叶斯模型证据;换句话说,它们最大化了在一个生成模型下,感官与环境的交换的概率,这个模型描述了这些感觉是如何产生的。这就是主动推理和隐式自证(Hohwy, 2016)的本质。
直觉上,自证意味着大脑可以被描述为推断感觉样本的原因,同时引发的感觉是最不令人惊讶的(例如,不直接凝视太阳或保持热感受器在生理范围内的活动)。从技术上讲,这种对行动和感知的理解可以被描述为最小化惊奇的替代方法,称为变分自由能。从统计学的角度看,变分自由能可以分解为复杂度和准确度,这样最小化变分自由能就提供了一种在最简单的方式下对某些数据的准确解释(Maisto et al., 2015)。关键是,主动推理推广了贝叶斯推理,因此目标不仅仅是推断导致感觉的潜在或隐藏状态,而且是以最小化预期惊奇的方式行动。在信息论中,预期惊奇被称为熵或不确定性。这意味着,可以将最佳行为定义为以解决不确定性的方式行动:例如,快速扫视到视觉空间中显著或信息丰富的区域,或避免从一开始就具有高成本或不吸引人的结果。与直接行动和感知最小化自由能一样,行动可以根据最小化追求该策略的预期自由能的计划或策略来规定。
本节简要回顾了与本文相关的主动推理的部分内容。我们首先解释预期自由能。然后考虑如何将主动推理应用于离散生成模型,例如上一节描述的模型。最后,我们考虑了如何将信念更新实现为一种神经可信的消息传递方案。
3.1. Expected free energy预期自由能
预期自由能(G)具有相对简单的形式(请参阅附录A),可以分解为一个关于信息探索和不确定性减少的认知价值(内在价值)部分,以及一个关于目标追求和成本规避的务实价值部分(外在价值)。形式上,特定策略(π)的预期自由能可以用未来时间τ的关于结果(o)和世界状态(s)的后验信念
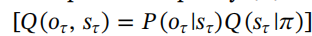
来表示:
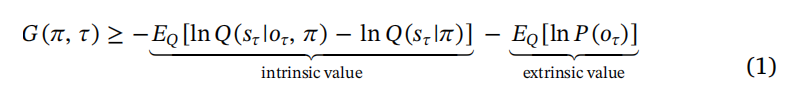
外在(即务实)价值简单地是以预先偏好的结果为基础定义的政策的预期价值;其中等价成本对应于贝叶斯风险或先验惊喜(请参阅表1和附录B)。更有趣的部分是不确定性解决或内在(即认知)价值,各种称为相对熵、互信息、信息增益、贝叶斯惊喜或在特定政策下预期的信息价值(Barlow,1961; Howard,1966; Itti and Baldi,2009; Linsker,1990; Optican and Richmond,1987)。预期自由能的另一种表述可以在附录A中找到:这种表述重新排列了预期自由能的方程,使其被解释为关于结果的预期不确定性(即模糊性或预期的不准确性)加上预测和偏好结果之间的Kullback-Leibler散度(即风险或预期的复杂性)。该公式显示,最小化预期自由能将确保实现偏好的结果,同时解决有关生成这些结果的世界状态的不确定性。
在这里,我们不太关注预期自由能的务实方面,而是关注于减少不确定性的认知动机。我们以前已经从关于视觉搜索的建构主义角度(如,场景构建)解释了这种认知机会(Hassabis and Maguire,2007; Mirza et al.,2016)。在本文中,我们使用更复杂的生成模型来说明同样类型的认知探索,通过语言交流进行中介。值得注意的是,我们稍后将看到的有目的、好奇和演绎行为都是最小化(预期的)自由能的 emergent性质。换句话说,不需要手工制作任何规则或语法,也不需要提供任何强化或反馈。本文展示的所有行为都是由生成模型的结构产生的。后续部分将说明在该模型下的信念更新,因此,首先,我们考虑信念更新与神经过程和行动的关系。

3.2. Belief updating and neuronal dynamics in discrete generative models
3.2 离散生成模型中的信念更新和神经元动力学
本节关注由无法直接观察到的离散状态(即隐藏状态)引起的离散结果的生成模型。本摘要基于(Friston et al., 2017c ASI 8年计划 paper6 图网络大脑: 信念传播和主动推理),其中包含了对该方法感兴趣的读者更详细的内容。简而言之,这些模型中的未知变量对应于生成结果的世界状态和生成连续状态的政策。为简单起见,我们将信念更新引入到一个通用的离散生成模型中,该模型具有单个层级;然后,我们将此描述扩展到包含两个层级的离散分层模型。
图3描述了这些生成模型的基本形式,以两种互补的格式,以及在观察到新的(感官)结果后的隐式信念更新。左侧的方程式以概率分布的形式指定了生成模型,涵盖了结果、状态和可以用边缘密度或因子表达的政策。这些因子是条件分布,包含由右上角的贝叶斯网络中的边编码的条件依赖关系。图3中的模型以以下方式生成结果。首先,在最高级别使用预期自由能的 softmax 函数选择政策(即计划或受控行动序列)。然后,使用所选政策指定的概率转换生成隐藏状态的序列(编码在 B 矩阵中)。随着政策的展开,状态在每个时间点生成概率结果(编码在 A 矩阵中)。
该图形模型的等效表示显示为右下角的 Forney 因子图。在这里,生成模型的因子(方框中的数字)现在构成了节点,(对)未知状态与边相关联。构建因子图的规则很简单:与每个变量相关的边连接到其参与的因子。

在神经动力学方面,方程式2中的 Sigmoid 函数(σ)可以被视为跨膜电位的 Sigmoid(放电率)激活函数,而关于隐藏状态的对数期望可以与编码期望的神经元群体的去极化相关联。这在与证据积累的理论提议和实证研究(de Lafuente等人,2015;Kira等人,2015)以及概率的神经编码(Deneve,2008)方面具有一定的建构效度。关于政策的信念和信念的精度的等效更新也可以推导出来。尽管出于简单起见,在图3中省略了关于政策信念的预期精度,但这些预期精度对于具有阶段性多巴胺动态的所有特征而言是有趣的。我们稍后将简要介绍模拟的多巴胺神经元放电。有兴趣的读者可以参考(Friston等人,2017a,2014)了解详细信息。
如上所述,在这种(纯沟通)环境中,产生结果的是当前发言的代理。这些结果是最小化变分自由能的结果。从方程式3可以推断出,这些结果只是最大化准确性的结果:

这是因为自由能的复杂性部分不依赖于结果(参见方程式3)。这种结果形式上与主动推断下的运动输出相关联;也就是说,经典反射通过满足本体感预测来实现(Adams等人,2013;Shipp等人,2013)。在当前的模拟中,生成单词或短语,其扮演的是根据每个时间点的对隐藏状态的信念而形成的预测的等效角色。
最后一步是通过将生成模型堆叠在一起来创建深层生成模型;这样,一个级别生成的结果为下一级别的初始状态提供(经验)先验。通过以这种方式链接层次级别,较高级别的状态随着时间变化缓慢,因为在较低级别的状态转换序列中,较高级别的状态保持不变。在当前设置中,这意味着对于较低级别的连续单词的信念更新比对于较高级别的短语的信念更新更快 - 强制短语由多个单词组成。来自较高级别的自上而下(经验)先验为关于下一个单词的推断提供了背景,该推断受到句子中所有先前单词的影响。这是深层时间模型的重要方面,赋予推断一种层次性质;在技术上被称为半马尔可夫过程。图4展示了生成模型的层次形式(上部面板)及相应的消息传递方案(下部面板),以因子图的形式呈现。请注意,图4只是图3的扩展。在较高级别,从图3中隐藏状态到结果的可能性映射(A)被替换为从较高级别的隐藏状态到较低级别初始状态的映射(由D表示)。这些映射允许较高级别的状态与较低级别的状态发生交互作用。
与图4的精神相呼应,图5显示了图2中的“二十个问题”生成模型的特定Forney风格因子图。在这里,隐藏状态已经被分解为它们的因素,其中可控状态以红色标记。如前所述,可控状态的转移概率由策略指定。例如,对于语义因子名词,可用的策略可以将语义状态“方形”移动到“三角形”。在这里,策略在一系列状态转换中仍然有效。换句话说,一旦推断或选择了一个策略,它就在预测后续结果方面保持有效。例如,如果我承诺语义状态为“方形”,那么它将成为下一个问题和随后回答的主题。请记住,策略是被选择为最小化预期自由能的(第3.1节)。
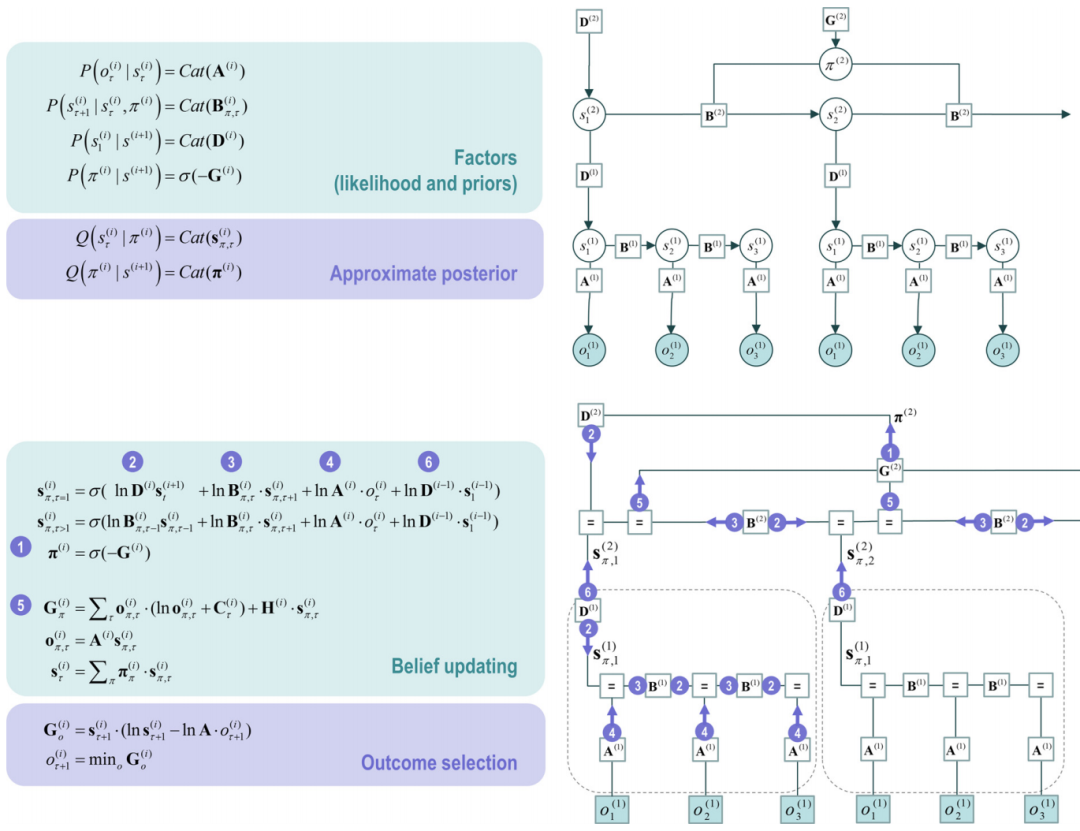

图4. 深层时间模型。左侧面板:该图提供了深层时间模型的贝叶斯网络和相关的Forney因子图,左侧描述了因子和信念更新。图表采用与图3相同的格式;然而,在这里,模型在层次上进行了扩展,其中(括号内)上标索引了层次级别。该模型的关键方面是其分层结构,代表了随时间或时期的隐藏状态序列。在该模型中,更高层次的隐藏状态生成更低层次的初始状态,这些状态展开以生成一系列结果:见,联想链接(Page和Norris,1998)。关键是,较低层次的循环在上面一级的每次转换中重复。这由虚线框中的子图表示,这些子图被“重用”为更高层次展开。正是这种调度赋予了模型深层时间结构。初始状态的概率分布现在取决于上一级别的状态(当前时间)。在实践中,这意味着D现在变成了一个张量,而不是一个向量。从相应的因子节点传递的消息基于贝叶斯模型平均值,这些平均值需要预期的策略[消息 ❶]和在每个策略下的预期状态。然后使用得到的平均值来组成下行[消息 ❷]和上升消息[消息 ❻],分别调节不同层次之间的经验先验和后验的交换。经许可改编自(Friston等人,2017c)。
配备了这个模型和变分消息传递方案,我们现在可以模拟对话;无论是在信念更新方面还是在相关的神经消息传递方面。当代理人在倾听时,结果可以由另一个代理人生成,以模拟二元交换。相反,当代理人在说话时,结果被选择为使代理人的信念下的自由能最小化。换句话说,当代理人在说话时,它选择的是在其对当前句法和语义的信念下最不令人惊讶的词语。请注意,代理人并不“知道”谁在说话——它只是期望听到与其信念一致的事物。如果它听到令人惊讶或意外的事情,代理人将更新其关于当前场景和语义学的信念。更重要的是,代理人对所说的内容的信念取决于所推断的政策。这些政策最小化了预期的自由能,这意味着代理人期望遇到突出的、信息丰富的答案,关键的问题。换句话说,它期望听到解决不确定性的问题和答案,这与它可能提出的问题和提供的答案相同。
在考虑语言处理的分层生成模型时,我们面临着线性化问题(Bornkessel等人,2005):即,结果如何提供给生成模型的更高层次,以及更高层次如何对较低层次的证据收集提供约束?换句话说,如何从顺序刺激中积累证据,以形成关于不随时间变化的事物的信念?令人高兴的是,上述类型的深层时间模型已经解决了这个问题。在接下来的部分中,我们通过模拟一个代理玩“二十个问题”的游戏来展示支持这种(线性化)证据积累的隐式消息传递和信念更新。
4. “Twenty questions” simulations“二十题”模拟
为了说明信念更新及其神经对应物,我们使用了一个简化版本的“二十个问题”。具体来说,我们模拟了由六个交换组成的对话,每个交换包括三个短语或句子。这些短语总是遵循相同的顺序:提示、问题,然后是答案a prompt, a question, then an answer。这个顺序是通过对叙事状态之间的转换指定非常精确的先验条件来固定的。每个短语包含最多六个词,每个词都使用方程式3描述的信念更新进行处理。这些更新在16个时间步长(大约为实际时间的16毫秒)内进行评估。这意味着每256毫秒生成一个词,因此四个词的句子大约需要一秒钟来表达。在这些模拟中,人工智能代理可以扮演提问者或回答者的角色:代理要么听取提示、提出问题,然后听取答案,要么发出提示,听取问题,然后提供答案。在所有情况下,代理(略微)更喜欢肯定的答案(“是”)而不是否定的答案(“否”)。这些偏好是通过设置“是”的先验成本为C = -¼,而“否”的先验成本为C = ¼来指定的(见表1)。这意味着在一切相等的情况下,代理将提出它认为会得到“是”回答的问题。

在这些模拟中,代理开始时对两个位置(上方和下方)的颜色和形状都持有均匀的先验信念。在前四个交换中,它扮演了提问者的角色,之后它对两个对象的颜色和形状都有了高度的信心。在更新了其信念之后,它随后转变角色回答了两个问题。为了让代理在这些模拟中扮演提问者和回答者的角色,我们将代理的生成模型与生成过程分开;实际上,这意味着代理与生成过程进行了“对话”。生成过程与生成模型具有完全相同的形式,只是生成过程对场景的信念更加精确。在这里,由于代理没有关于自己是在说话还是在倾听的信念,我们通过在交换的适当阶段对代理或生成过程的输出进行采样来模拟轮流说话。
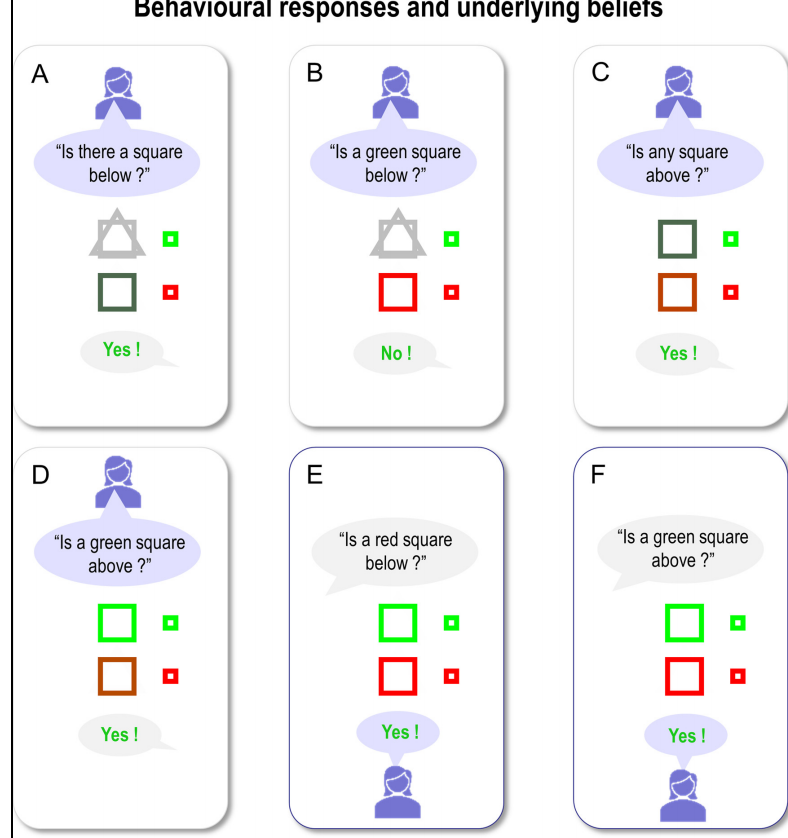
图6显示了信念更新的结果。每个面板显示了在每个六个问题的回答之后对两个隐藏对象的后验期望。问题显示在面板顶部的黑色文本中,而答案显示在面板底部。在这个示例中,所有的答案都是正确的(即与真实场景相符),因此显示为绿色。在每个面板中,代理对两个位置的形状(方形与三角形)和颜色(绿色与红色)的信念用大图标表示。真实(叙述)场景用右侧的小图标显示。
在前四个问题中,代理积累证据并建立了关于手头场景的真实信念。起初,它对两个位置的形状和颜色没有特定的(即均匀的)信念。首先,它选择询问形状的问题,因为这样比同时询问形状和颜色更有可能得到肯定(首选)的回答。在第一个答案之后,它知道下方是一个正方形(见第一个面板),随后询问关于形状和颜色的组合的问题。
在第二个答案之后(见第二个面板),它知道方块不是绿色,因此必须是红色。然后,它继续对上方的位置提出类似的问题,在此之后,它对两个位置的形状和颜色持有精确的信念。当它回答第五和第六个问题时,代理可以对特定场景组件的问题提供真实的答案(这些答案以绿色文本显示表示答案是正确的)。请注意,在第一次推断下方是一个红色的正方形之后(比较第二和第三个面板),对下方正方形颜色(红色)的期望变得不太明确。这是因为我们减慢了信念的更新,使其时间常数大致与实际观察到的时间相对应(见下文)。这阻止了在信念更新过程中完全收敛到自由能最小值。随之而来的不确定性随后传递到下一个交换。此外,请注意,在正确回答有关下方正方形颜色的问题(第五个问题;下部中间面板)后,由于答案提供了关于先前信念的确认性证据,代理的信念得到了更新。
正如预期的那样,人工代理在仅仅四个问题后就解决了关于隐藏场景的不确定性,这表明提出了适当的问题。例如,第一个问题确定了下方是一个正方形,而第二个问题揭示了它是红色的事实。它本可以选择只问“什么”问题,但那样可能需要多达8个问题才能推断出正确的场景。还要注意,第二个问题并不多余:它是在知道下方对象是正方形的情况下提出的。可能的第二个问题是问:“下方有一个圆吗?”,但考虑到(i)代理已经知道下方的对象是一个正方形,(ii)在这种情况下,每个位置只有一个对象存在,这个问题不会减少关于场景内容的不确定性。最终,在这些模拟中展示的行为之所以出现,是因为代理选择了减少关于场景的不确定性的策略。这只能发生,因为生成模型考虑了未来的状态,使得代理能够评估未来的预期结果。例如,对第二个问题的任何答案(“下面是一个红色的正方形吗”)都会完全解决有关其颜色的不确定性。代理甚至在提出问题之前就知道这个问题将解决不确定性。因此,这种类型的问题具有认知价值。

请注意这种认知行为的微妙性质:代理使用语义状态(名词、形容词和副词),它(相信自己)控制着这些状态,来解决关于景观状态的不确定性,而这些状态(它相信自己)无法控制。在这种情况下,代理通过产生结果(例如问题)来施加控制;它会生成在不确定性解决策略下最不令人惊讶的结果。这种间接的信念更新是当前公式中的核心,当考虑通过语言交流如何在他人中安装信念时尤其如此。
4.1. Message passing and neurophysiology消息传递和神经生理学
Fig. 7说明了上述模拟中六个问题的电生理和多巴胺反应。这些反应以各种格式显示:
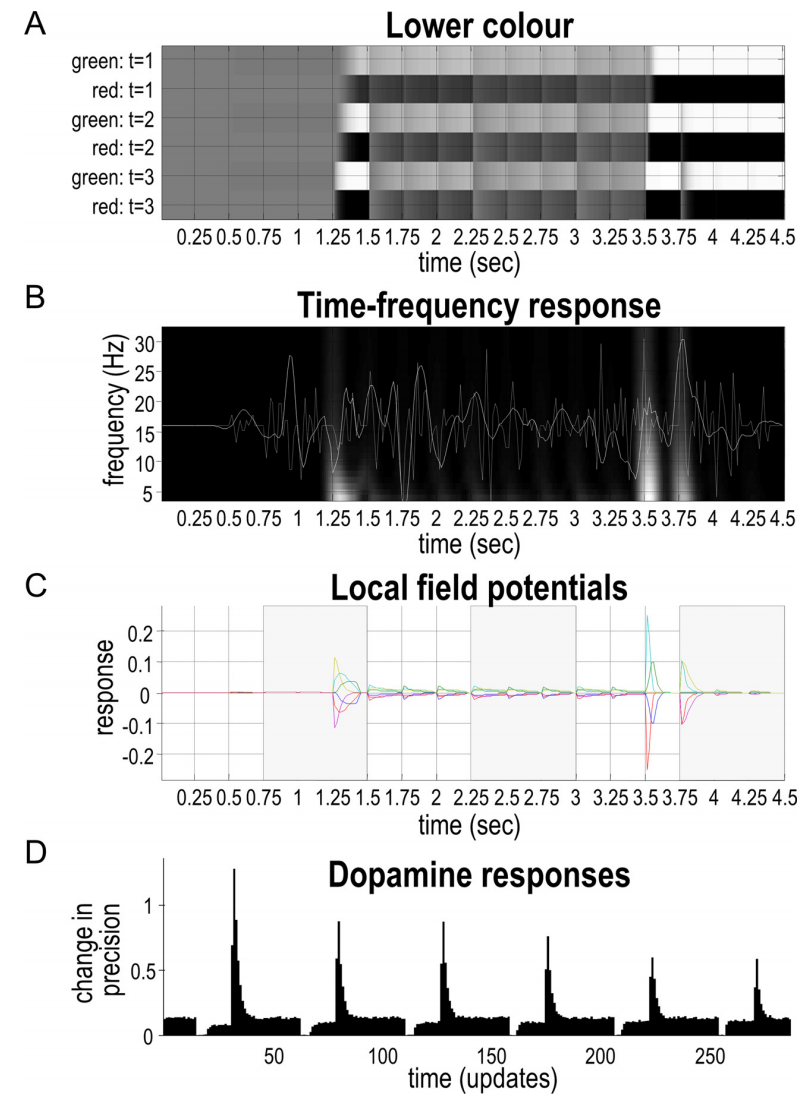

图7A以光栅图的形式显示了在六个叙述序列中的不同时间点下对下方物体颜色的后验期望。信念更新具有两个时间尺度:每次新刺激后收敛到最小自由能的速度,以及支持该收敛的更快动态。通常,假定新刺激每250毫秒采样一次。这段时间允许16轮变分消息传递收敛到自由能的最小值,其中每一轮或迭代大约持续16毫秒。这些假设使得合成的神经元反应与大脑中ERP的时间常数一致(Friston et al., 2017a, d)。为简单起见,此图仅显示颜色状态。Y轴上标有不同的单位;即在每个交换内的连续时期(1、2和3)中的绿色或红色。
在对应于第一个问题和答案(0-0.75秒)的时间窗口内,图7A呈灰色阴影,表明在第一个问题期间,即询问形状而不是颜色时,代理的颜色信念是均匀的。第二个问题询问下方物体的颜色。这个问题的答案是“否”(即不是绿色),表明下方位置的正方形必须是红色。图中显示,这个答案引发了深刻的信念更新;关于下方正方形是红色的信念非常准确,并且在整个交换过程中(即绘图剩余时间内)保持不变(即“记住”)。在此期间,图中的阴影使我们能够可视化对对象为红色的信念精度的降低,以及在第五个问题之后对精度的恢复,正如前面部分所讨论的那样。
请注意,在图7A中,对于试验开始时的期望,信念更新的潜伏期比结束时要长 - 这是由于时间上的消息传递(图4中的消息❸)。正如上文所述,这些后验信念会在随后的试验中稍微衰减,直到代理再次确认下方颜色确实为红色。
图7B以不同的格式显示相同的数据。在这里,经过在4至32赫兹之间进行滤波后的汇总期望被显示为白色线条。这与一个时频热图相叠加,以说明在信念更新期间频率特定能量的突发。我们稍后将更详细地研究这种表征,参考下一个图。
图7C说明了神经活动的模拟波动,经过带通滤波后。这可以被看作是模拟的局部场电位或事件相关电位(Leonard等人,2016),大致对应于方程3中的电压波动。在本文的后面部分,我们将重新审视这些合成ERP,以表征对意外结果的响应。当前的模拟仅显示了模拟ERP的幅度与结果传达的信息量有关 - 它对叙述中更具信息量的部分显示出更大的响应。
最后,图7D显示了模拟的多巴胺反应(即对政策信念的预期精度),如(Friston等人,2014)所述。有趣的是,这些短暂响应的高峰与答案给出的时间相一致。从这些短暂响应中得出的关键观点是,对正在追求的政策信念的隐含信心的变化取决于答案解决了多少不确定性并实现了先前的偏好。每当代理接收(以及在较小程度上提供)一个答案时,它对自己正在做的事情就会变得更有信心。然而,对隐藏场景变得更有信心会削弱“信心提升”(即短暂多巴胺反应)。据说,这似乎与“二十个问题”的主观体验一致,在游戏开始时,每个确认的答案都是令人满意的。
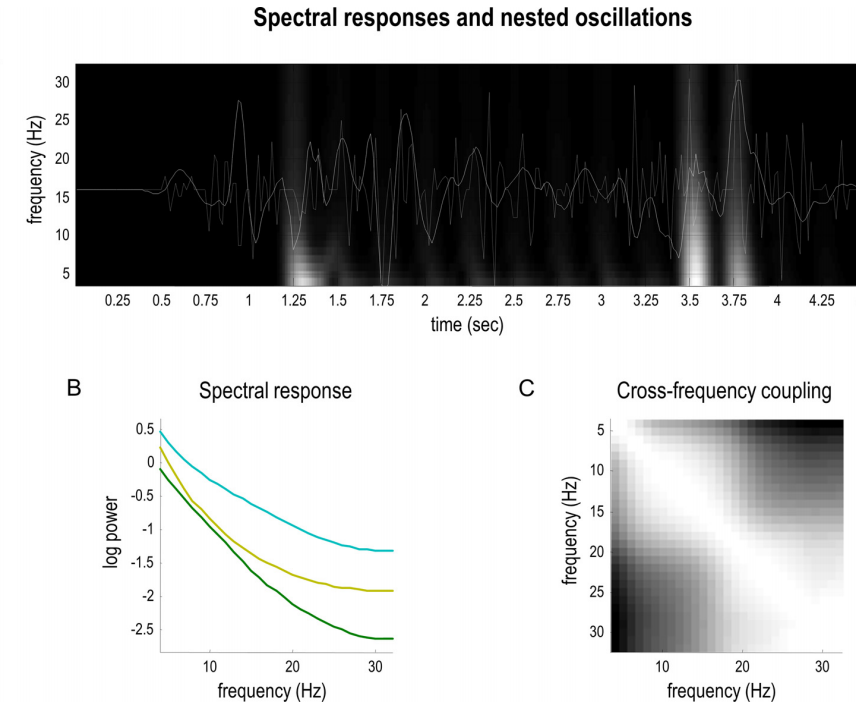

图8以分析在信念更新期间从更高层次区域的频谱响应时的预期为基础,呈现了图7的模拟电生理反应。下部面板显示了频谱响应。图8B报告了六个单位(即神经元群体)的对数频谱密度,其事件相关响应显示在图7C中。这表明频谱响应显示出一定程度的无尺度宽带活动,反映了模拟的神经动力学具有多个嵌套时间尺度。
在图8C中,不同频率的波动之间的随后的非线性耦合以交叉频率耦合的形式进行了总结。这种简单的表征是响应幅度之间的相关性,涵盖了从4到32赫兹的频率范围(基于下部面板的时频响应)。从该面板中需要注意的关键事项是其非对角结构:图中左下和右上象限中较浅的阴影表示存在零以上的相关性,表明低频率和高频率之间存在相关性—换句话说,是θ和γ响应之间的振幅到振幅耦合。这种耦合是因为在这种分层模型下,不同时间尺度上的信念更新很可能同时发生(即在相同的时间)。
在这种分层模型下的信念更新也需要产生被解释为反映相位-振幅耦合的响应。这些类型的响应源于在生成模型的不同分层级别上进行的信念更新,这些更新发生在不同的时间尺度上。神经动力学对变分自由能进行梯度下降,因为每次新的结果变得可用时(对于更高级别来说,即每个短语被说出时),都会进行更新。由于这种时间安排,必然存在嵌套振荡,即快速(例如,γ波)的波动以缓慢(例如,θ波)的节奏展开(Friston等人,2017a):听到每个词会引发一系列包含高频组分的瞬变,并且这些瞬变会以词汇呈现的较低频率重新出现。在这类分层生成模型中,更高层次的每个转换都伴随着较低层次状态的“重置”(Friston等人,2017c)。在当前应用中,短语级别的推断会生成短语中包含的单词,然后较低层次会为下一个短语“重置”。这种嵌套自然地导致相位-振幅耦合—这是最常研究的交叉频率耦合类型之一(Canolty和Knight,2010)。
图9展示了较高和较低层次的神经元群体的模拟神经元放电和相关局部场电位的嵌套情况。图9A展示了上层的模拟单位响应,图9B展示了下层(符号语义)的相同响应,图9C叠加了上层和下层的模拟局部场电位。在这里需要注意的关键一点是,较低层次的瞬变(青色线)比伴随的较高层次的瞬变(红色线)更快。这意味着对每个单词或短语的频率特定响应振幅的波动必然会产生相位-振幅耦合。从现象学上来看,这意味着人们不会感到惊讶,看到在较高层次的β活动爆发与在较低层次的γ活动爆发同时发生。有关相关现象的讨论,请参见(Arnal和Giraud,2012;Giraud和Poeppel,2012)。
从这个角度来看,幅度到幅度和相位幅度耦合是量化非线性耦合的两种方式,它们都源自于在层次生成模型下的瞬态嵌套。如果受到标准的实证分析程序的影响,例如双相干分析或相位同步测量,这些瞬态的嵌套将被解释为某种形式的非线性或相位幅度耦合:例如,参见(Giraud和Poeppel,2012;Lizarazu等,2019;Pefkou等,2017)。在解释这些效应时,有一个微妙的区别值得注意:在理想化的情况下,相位幅度耦合和幅度到幅度耦合是不同的。相位幅度耦合是层次建模的必然结果,因为伽马频率的更新安排在较慢的θ频率下。然而,θ和伽马之间的幅度到幅度耦合是由于离开了完美的伽马瞬态的θ速率,因为θ活动的幅度必须变化以产生幅度到幅度耦合。正如图8和图9所显示的那样,在这里模拟的电生理响应的常规分析中,这两种数据特征都会出现。然而,从实际角度来看,真实数据中区分不同类型的交叉频率耦合是困难的,这是由于海森堡不确定性原理的影响(例如,参见(Aru等,2015;Munia和Aviyente,2019;Nakhnikian等,2016))。换句话说,表面上的幅度到幅度耦合反映了人们量化这种耦合方式的方式。因此,相位幅度耦合是我们描述的层次生成模型中更有趣的特征。总的来说,这种非线性耦合与“证据表明人类听觉感知的时间调制传递函数(TMTF)不仅仅是低通的”是一致的(来自(Edwards和Chang,2013)p113)。
4.2. Deep violation responses深度违规响应
到目前为止,我们已经专注于通过时间频率分析来测量的消息传递及其神经生理学相关性。在这里,我们考虑了相同的计算架构如何为诱发响应生成预测。特别是,我们展示了违反期望的刺激会产生差异(不匹配)波形,这是许多实证研究的重点;例如,(Coulson等,1998;Friederici,2011;Pulvermuller等,1995;Van Petten和Luka,2012;Ylinen等,2016)。
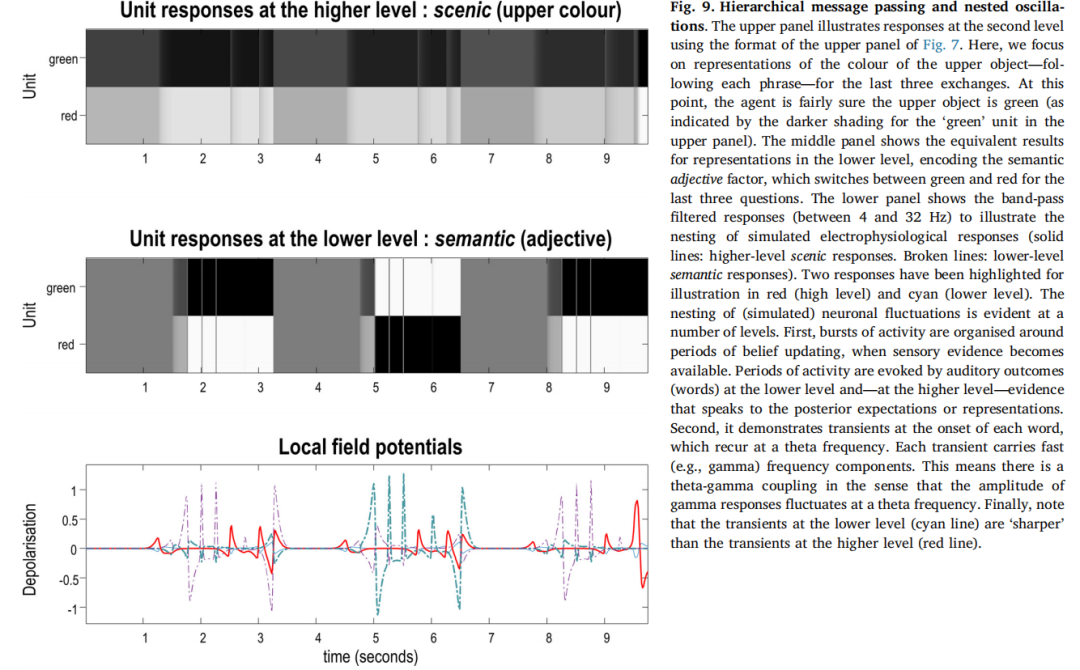
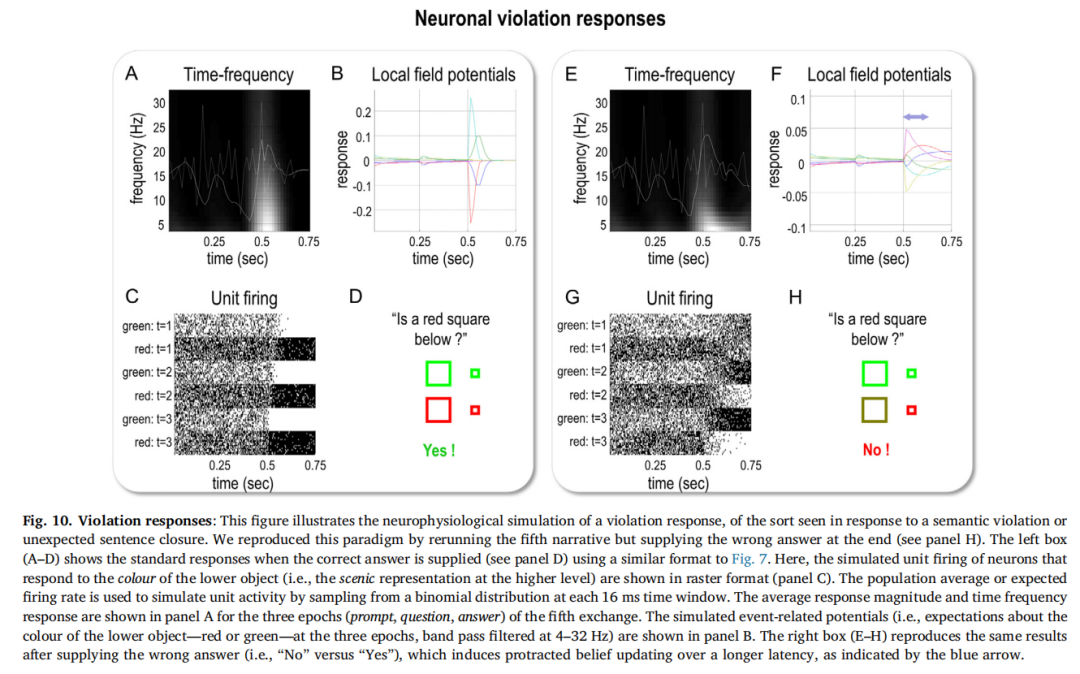
图10展示了对违反响应的神经生理模拟;例如,对语义违反或意外句子结尾的P300或N400响应。在这里,我们通过重新运行前一次模拟的第五个交换,并在最后给出错误答案来重现违反范例。请记住,在第五个交换开始时,代理方对下方形状的颜色为红色非常有信心:它从第2个问题的答案中获得了这一信息。左侧面板显示了标准响应,采用与图7类似的格式。模拟的事件相关电位(即,在三个时期内的下方颜色的带通滤波期望)显示在右上方。产生这些波动的基本单元活动以模拟的单元发射的方式显示在左下方。值得注意的是,右侧面板中模拟的事件相关电位(即,在0.5秒时给出错误答案)具有较长的潜伏期(如蓝箭头所示)。这些长潜伏期响应在形态上与实验违反范式中的P300(Donchin和Coles,1988;Van Petten和Luka,2012)和N400(Kutas和Hillyard,1984;Van Petten等人,1999;Van Petten和Kutas,1990)波形分量非常相似。在这里,它们只是反映了人工代理方必须改变其主观看法并撤销下方方块为红色的确信,因为证据有利于绿色;换句话说,更新其信念。正如从右下方面板中可以看到的那样,代理方对颜色的确定性降低了,并且稍微倾向于相信下方对象的颜色是绿色。这种后验信念与听到对问题“下方有一个红色的方块吗?”的否定回答完全一致。
5. Synthetic communication综合传播
在上述模拟中,通过从生成过程中采样,外部事务被用来对前四个问题提供真实的答案。换句话说,外部状态代表了回答或提问者的信念。在接下来的部分中,我们进行了重要的改变,用另一个合成主体替换了外部状态。这具有一个有趣的后果,即将外部状态排除在外:结果是从一个或另一个主体的(后验)预测中生成或采样的,因此在任何时候我们都不需要参考(外部的)世界状态(见图1)。这是允许代理生成彼此共享的结果的直接结果。从启发式的角度来看,解决不确定性的必要性(即,最小化预期自由能)现在体现在信念状态的同步上;换句话说,是一种“心灵的交会”和相互理解。
5.1. Questions and answers问题与解答
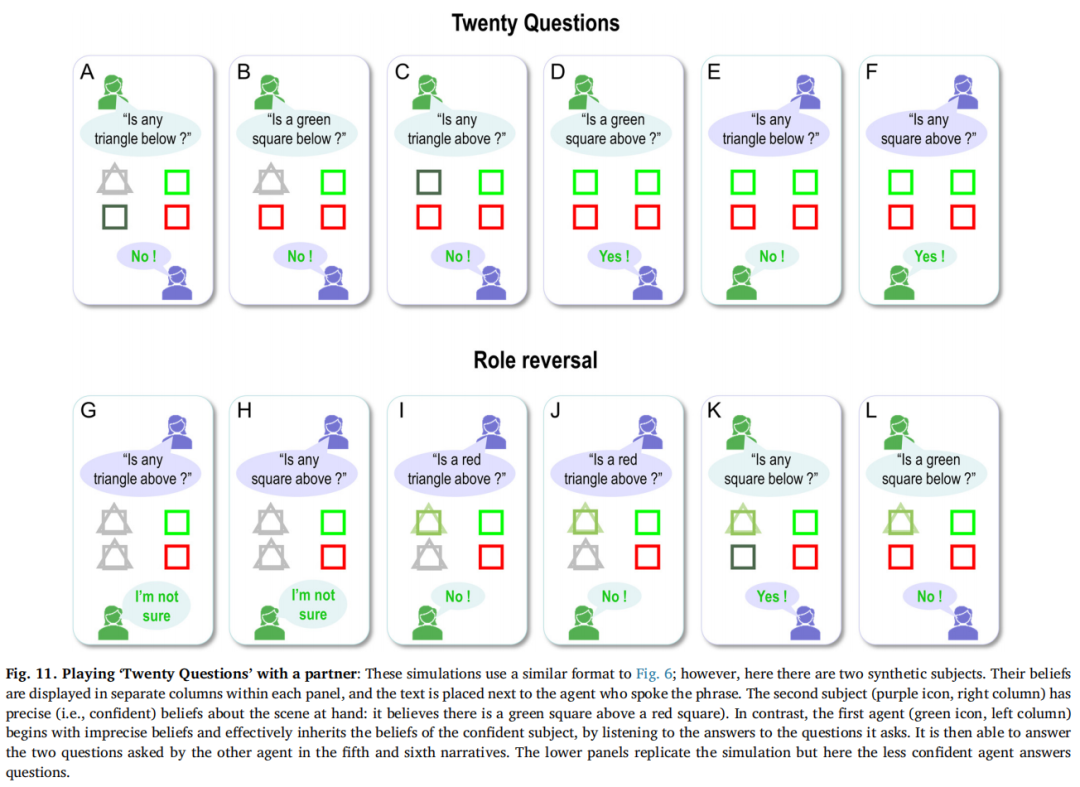
图11中报告的模拟采用了类似图6的格式;然而,这里有两个合成主体。第二个主体对手头的情景有着确切的(即自信的)信念(即,上方是绿色正方形,下方是红色正方形)。相比之下,第一个主体在交换开始之前信心不足,并通过听取对其提出的问题的回答来有效地继承了自信主体的信念。类似于图6,在第四个答案之后,第一个主体对自信主体的信念有了准确的理解,并且能够正确回答最后两个问题。
在这个例子中,第一个代理人精心选择了问题,以尽量消除不确定性。在下部面板中,我们颠倒了角色,使得第二个(自信的)代理人提问,而信心较低的代理人提供答案。模拟结果显示在下部面板中(标题为角色颠倒)。与上部面板相比,在第四个答案之后,第一个代理人对第二个代理人的信念收集得更慢,而且两个代理人在第四个答案之后不再分享相同的信念。第二个代理人提出的问题对困扰第一个代理人的特定不确定性不敏感,因此第一个代理人只能对前两个问题回答“不确定”,当时它的信念在红色和绿色状态之间是一致的。对于第三个问题,它回答“否”。与前两个问题不同,第三个问题询问了上方位置的颜色和形状属性的组合,有四种可能的选项,因此根据概率平衡,最可能的答案是“否”。在听到自己的否定答案后,该主体确信上方的形状不能是红色三角形,更可能是绿色正方形,这在其对(相同的)第四个问题的后续回答中得到了进一步的支持。只有在观察到明确和真实的答案后,它才能开始积累关于其他主体信念的适当信念。
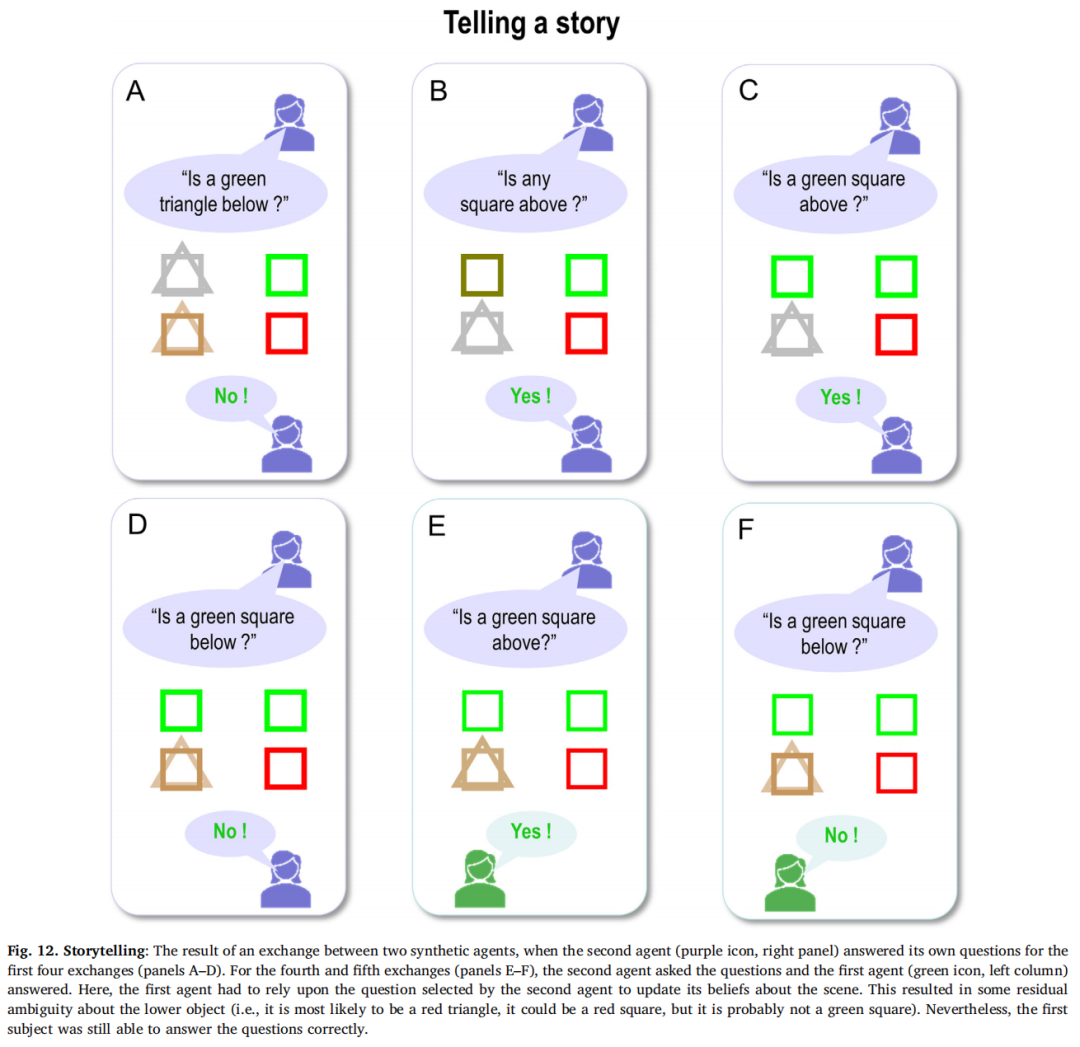
5.2. Storytelling讲故事
我们可以使用上述完全相同的方案来模拟指令或叙述:在这个主动推断的框架中,所有形式的交流都具有相同的基本联合信念更新特征。我们重新运行了上一节中的模拟,但这次第二个代理人回答了自己的问题(见图12),而第一个代理人在前四次交流中只是倾听,并在最后两次交流中提供答案。与上面类似,第一个代理人从第二个代理人那里继承了情景信念,但这里只是通过倾听第二个代理人的独白。经过四个问题和答案后,第一个代理人对场景已经足够自信,能够正确回答;尽管它不确定下方的对象是红色正方形还是红色三角形。这种歧义反映了之前的问题和答案并未被选择以减少第一个代理人的不确定性——它们是由具有非常明确信念的第二个主体选择的。
5.3. Making your mind up下决心
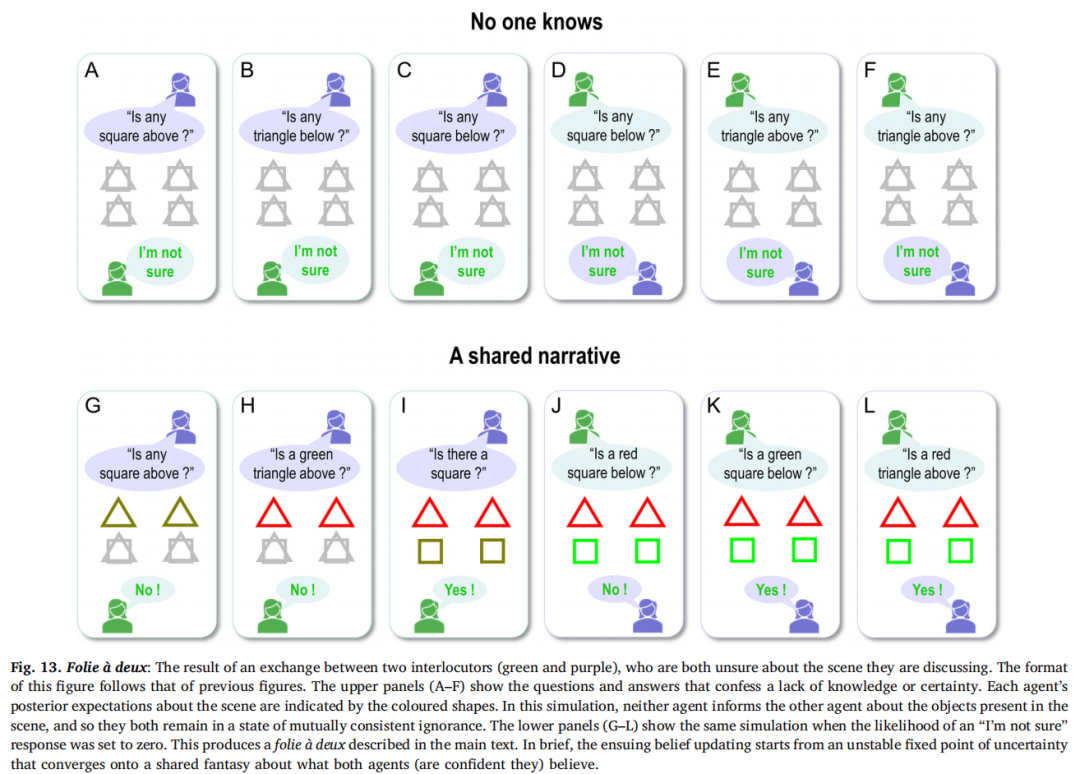
如果我们降低先验信念的精度,使得两个主体对场景都感到不确定,情况就会变得有趣起来。回想一下,合成代理人有三种可能的回答:“是的!”,“不是!”和“我不确定”。当在这种情况下允许彼此提问时,他们只是诚实地回答说他们不确定答案(见图13的上部面板)。然而,当我们降低“不确定”响应的先验概率时,两个主体有效地告诉彼此他们的信念,直到他们持有相同的信念(见图13的下部面板)。在这一点上,不确定性被排除,因为每个人都可以预测对方和他们共同的理解。这是一种神经诠释学(Frith and Wentzer, 2013),在没有“指向真理”的情况下。正如上面所指出的,这是一种广义同步化(Friston and Frith, 2015a),在这种同步化中,作为语言交流基础的信念状态的轨道变得相互可预测,因为(预期的)自由能被最小化。从拟人化的角度来看,这两个合成主体简单地达成了关于如何描述某个共享构想的共识。关键是,这个构想(即场景)不存在,从我们的角度来看,因此,它可以被描述为一种共病性妄想(Arnone et al., 2006)。从更积极的角度来看,它也可以被解释为一种联合的创造性思维活动。虽然这里没有进行,但人们可以考虑这种模拟的扩展,可以将其构架为艺术交流和创造力,从而使我们回到通过认识探索、新奇和乐趣来解决不确定性的问题(Schmidhuber, 2006)。
回到图13的上部面板,这个例子说明了不确定信念的共同维持。这很有趣,因为这些基本的代理人没有正式的元认知能力(请参见讨论部分)。换句话说,他们的不确定性是通过编码不确定的信念分布的神经状态来隐含的,而不是具有编码关于信念精确性的后验信念的神经状态。no formal metacognitive capacity (see discussion). In other words, their uncertainty is implicit in neuronal states encoding uncertain belief distributions, rather than possessing neuronal states that encode posterior beliefs about the precision of their beliefs.对于信念精确性的信念听起来可能相当复杂;然而,具有深层结构的统计模型往往会明确地编码不确定性。例如,当我们报告统计检验的自由度时,实际上是在报告我们对不确定性估计的置信度;例如,一些参数估计的标准误差(Friston et al., 2007)。在当前的模拟中,没有这样的元认知推理——然而,这两个代理继续回答他们对被询问的隐藏状态感到不确定,这是贝叶斯最优的。
支撑这种“已知未知”的明显确认的机制很简单。它建立在一个非平凡的“我不确定”的可能性上,无论一个人的信念如何。考虑以下情况:我正在想一个介于一和一百之间的数字,我可以报告一个数字或选择“不确定”选项。如果报告数字的可能性为90%,并且我对数字确信无疑,那么我报告我心中的(确切)数字的可能性是选择“不确定”的9倍。相反,如果我对数字一无所知,那么报告任何数字的可能性就等于选择任何其他数字的概率;因此,报告任何单个数字的概率降低到小于1%,因为概率分散或稀释到100个数字选项上。在这种情况下,我更有可能报告“不确定”而不是任何单个数字。在贝叶斯模型选择中,这种现象被称为证据稀释(Hoeting et al., 1999)。图13上部面板中的例子突显了对不确定性宣言的涌现但简单的后果。请注意,这种不确定性依赖于共享的生成模型,在这种模型中,即使在没有不确定性的情况下,也可以选择不具信息的响应。当我们取消生成这种不可知响应的机会时,就会出现一种不同的相互理解模式(见图13的下部面板)。
6. Discussion讨论
总之,我们阐述了一些沟通的可信相关性,这些相关性是在特定类型的生成模型下通过主动推理而产生的。这个生成模型的动机是语言在传达叙事中的作用。这个模型的关键特征涉及到共享叙事的概念,以减少不确定性。在第4节(“二十个问题”模拟)中,我们模拟了一个正在与自己交谈的代理(即,与生成过程“对话”),在第5节(合成通信)中,我们使用完全相同的生成模型来模拟两个主体,他们在互相提问和回答问题。在这些情况下,推理和感觉证据是相同的:唯一的区别是代理(即,谁在说话)。一般而言,这些模拟表明,即使最初两个合成代理的先验信念不同,它们的信念也会收敛。这只是反映了一个代理根据来自另一个代理的答案(即,观察)更新其信念的事实,并且因此会推广到其他情况,其中两个合成代理的先验信念不同。
在我们的模拟中,分层推理导致了类似于θ-γ相幅耦合的信念更新(图8),这在语音感知研究中经常被观察到;例如,参见(Giraud和Poeppel,2012;Lizarazu等,2019;Pefkou等,2017)。与我们的模拟神经元反应相关的是,它反映了模型反演下的信念更新——对应于语音感知而不是产生。在这个框架下,θ和γ频率之间的相幅耦合是因为听到每个单词会诱发一系列包含高频(γ)成分的瞬态(即,信念更新),而这些瞬态以单词呈现的频率重现,处于θ范围内。这产生了被解释为相幅耦合的模拟响应。其他人提出了一个多时间尺度嵌套过程作为合理的解释(Arnal和Giraud,2012;Giraud和Poeppel,2012),因为已经注意到这些节奏的时间与语言中的重要时间尺度相对应。先前对该现象建模的方法(Hovsepyan等,2018;Hyafil和Cernak,2015)是数据驱动的——包括明确的θ和γ“单位”。在这里,我们采取了理论方法,并展示了θ-γ耦合可以通过信念更新产生,考虑到代理的目标是从对话中理解场景的内容。
我们的模拟还预测了违反电生理响应,类似于P300和N400研究中观察到的类型。P300在奇异球范式中被观察到,在这种范式中,重复出现的刺激与意外的偏差刺激交替出现。在这种情况下,P300被解释为反映了高层次上下文的违反(Donchin和Coles,1988)。N400在语言研究中常常被观察到。当参与者听到频率较低的单词或与高概率单词语义相关的单词时,它就会被引发(Kutas和Hillyard,1984;Van Petten等,1999;Van Petten和Kutas,1990)。这些类型的不匹配波形已经在先前将主动推理应用于语音感知时得到了证明(Friston等,2020)。在这里,我们展示了一个能够生成这些类型的不匹配响应的分层模型也能够模拟θ-γ耦合。在先前的工作中,我们在局部-全局范式中显示了分层生成模型不同层级生成的ERP的区别(Friston等,2017d)。在未来的工作中,使用当前的生成模型来模拟层次结构中不同层级的违反,然后将这些与显示不同类型的违反会生成不同ERP的实证数据进行比较,这将是有趣的(例如,参见Connolly和Phillips,1994;Osterhout等,1996)。
我们所介绍的生成模型代表了一种思考语言语义或语境方面的不同方式,与先前的解释相关。考虑到这一领域中大量的心理学、哲学和计算文献,概括当前语言理解的实证和理论先驱将是一项巨大的工作。在这种情况下,有三点观察是相关的。首先,在当前框架中,信念更新是分层的:关于场景内容的信念保持在更高的层次。其次,一个代理人对其关于世界当前状态的信念的不确定性会影响信念更新的程度。最后,在这里,我们将语言理解描述为一种主动过程——允许代理人提出尽可能解决他们对事态的不确定性的问题。虽然模型中状态的细节有些简化,但我们的目标是提供一个可以用于模拟基本语言交流的通用计算架构。
在评论与相关工作的一些重要联系之前,我们将通过以下观察来限定这一讨论:如果一个人致力于主动推理(隐含地,自由能原理),那么关于语言处理的性质和形式的假设空间是很小的。这是因为所有感兴趣的内容在操作上都由生成模型和生成模型定义,而生成模型又是由我们想要解释的内容——即语言交流来定义的。换句话说,简单地定义推理问题就决定了所需生成模型的形式,即通过什么方式结果是由世界的状态(或其他状态)引起的。此外,一旦生成模型被指定,信念更新就由标准的信念更新方案来规定;这里,是变分或边缘信息传递。
这意味着如果某些假设或构建与上述形式或基本的信念更新架构不一致,那么就没有余地来容纳替代假设或构建。简而言之,在主动推理中,唯一的问题是:什么样的生成模型能够解释这些响应?严格来说,这排除了有关语言处理的实施和神经生理学相关性的问题。虽然这些内容在各自的领域可能特别有用,但除非神经生理学相关性可以与信念更新(即通过交流来理解)联系起来,否则它们无法用于模拟——因此无法理解——交流。在类似的情况下,任何在不涉及信念状态更新的情况下无法用于创建传播工具的计算神经语言学的新进展都无法使用 not deal explicitly with belief states updating cannot be used to create artefacts that communicate。例如,在语音识别中使用深度学习可能会提供有关在听觉水平上的语言处理的计算架构的引人注目的见解;然而,语音识别并不构成理解。换句话说,仅仅将听觉输入映射到单词列表并不构成生成模型的反演。在机器学习领域,一些研究已经研究了类似于主动推理的方案,在部分可观察性框架内。例如,贝叶斯行动解码器(Foerster等,2018)使用近似贝叶斯更新来获得“公共”信念,该信念取决于环境中所有代理人的行动,在玩多代理人游戏时导致有效的交流。
在本文中,我们将结果指定为单词而不是声学时间序列,因为从单词到声学的映射已经从主动听的角度进行了考虑(Friston等人,2020年)。这使我们能够专注于与语言和交流特定的生成模型方面。将当前模型与主动听(Friston等人,2020年)结合起来——该模型将单词与声学时间序列之间进行映射——将使未来的工作能够系统地研究影响口头交流的其他因素,如噪声。尽管我们将当前工作框架化为说话和听话,但我们注意到,在其当前形式下,它也适用于书面交流,比如交换文本消息。
计算语言学中的重要发展可以为主动推断方案提供有用的信息。例如,使用分层狄利克雷过程来解决语言生成模型中的结构学习问题(MacKay和Peto,1995年;Salakhutdinov等人,2013年)可能是发展语言习得背景下的生成模型,并随后使用贝叶斯模型简化(Friston和Penny,2011年)的正确方法。我们在当前论文中没有涉及这个问题;然而,一旦建立了语言和理解的生成模型的基本形式,下一个挑战将是研究通过优化模型参数学习的过程;例如,似然映射由层次之间的A矩阵所固定。在解决了这个问题(学习)之后,下一个优化水平涉及模型本身的形式和结构。例如,应该包括多少隐藏因子,以及每个因子应占据多少层次或相互排斥的状态?这就是结构学习的问题(Catal等,2019年;Gershman,2017年;Tenenbaum等,2011年;Tervo等,2016年),通过非参数贝叶斯方法(Collins和Frank,2013年;Goldwater,2006年;Teh等,2006年)来解决这个问题是非常巧妙的,这些方法在计算语言学中很常见(请参见下文)。重要的是,生成模型中的隐藏因子是分解的,因此,如果添加了额外的因子,则应该保留本文中的信念更新。只有当额外的因子与其他状态相互作用以影响结果时,添加额外的因子才变得有趣——在这种情况下,当前框架将允许估计这些相互作用的行为和神经生理学后果。类似地,只是在一个因素中添加额外的相互排斥状态不会影响推断,除非它们在奥卡姆窗口内产生高概率策略——在这种情况下,信念更新可能会变慢。关于生成模型结构的问题将是未来工作的有趣课题。
在较低的层面上,我们将句法和语义分解为单独的因子。对于当前的应用来说,这是直观的,因为可以使用不同的语法来询问关于场景相同特征的问题(即形状、颜色和位置)。我们承认,关于句法和语义是否独立存在的争论已经存在很长时间(例如Dick等人,2001年;Kuperberg等人,2003年;Siegelman等人,2019年),对这个模型的扩展可能希望更加仔细地考虑这个方面。这个框架的一个优点是可以使用贝叶斯模型选择(Stephan等人,2009年)来比较关于模型结构的竞争假设。换句话说,这将允许研究人员测试他们的数据的最佳解释是句法和语义的因子化还是具有更复杂的依赖结构的某种替代方案。
在本文中,我们忽略了对主体性的归属(即,对代理人的推断);也就是说,元认知能力(Fleming等人,2012年;Shea等人,2014年)。这意味着每个合成主体都不知道谁在说话,我们模拟中的“轮流发言”需要手工制作。尽管如此,我们的合成主体仍然可以利用提供的信息来解决对世界状态(例如,场景中物体的配置)的不确定性。更复杂的生成模型将包括包括代理机构本身的隐藏因子。对于当前的示例来说,这并不是必要的,但对于模拟语言交换中的轮流发言(Garrod和Pickering,2009年;Ghazanfar和Takahashi,2014年;Wilson和Wilson,2005年)是必要的。这是我们早期使用模拟鸟类进行的工作的重点(Friston和Frith,2015a)。在当前的工作中,我们简单地将内部生成的语音替换为对话者的外部语音,以分别模拟提问和回答。然而,代理并不知道这一点。
元认知的一个重要方面是知道自己何时不确定。在上述模拟中,代理通过彼此提供不具信息性的(“不确定”)答案来保持他们的不确定性。然而,他们并不知道自己不确定(即,他们的生成模型没有隐藏的“不确定状态”)。更复杂的生成模型会意识到某些事情缺乏信心,并以“我真的不知道”的方式回应。这种表面上简单的能力建立在一个本质上是元认知的信心生成模型之上;因为反转这种深度生成模型会产生关于信念的(后验)信念。
使用离散状态空间模型(即,隐马尔可夫模型或马尔可夫决策过程)来表达元认知深度是一个有趣的挑战。在某种意义上,对策略信念的精度或置信度的编码是一种元认知表征(参见图7中的模拟多巴胺响应);然而,这种表示相当基础。此外,这种表示形式是一种连续(实值)变量,类似于用于解释强化学习范式中多巴胺波动的变量(Schwartenbeck等人,2015年)。如果能有“我不确定”或“我很困惑”的分步态状态就好了。这涉及到使用更高层次的级别,在下一级别的初始状态上预先设定统一(经验)先验。换句话说,可以基于对特定事态的确信信念和完全不确定(具有统一先验)的离散化生成关于较低级别背景的信念分布。原则上,这应该赋予代理人对其信念的元认知感知,并通过语言传达这些信念的方式。
我们忽略的语言的一个重要方面是其由叙述和句子的排列组合所提供的计算丰富性(例如,离散无穷)。此外,我们还忽略了表征实际语言处理的解析和转换,它们本身具有深层次的层次形式。这个问题提出了一些有趣的挑战,就是在阐明生成模型的结构方面,可能涉及将口语语言的序数方面与其内容分开生成。技术上,这将涉及到上面的概率转移矩阵(B)用高维数组替换,以便一个因子的级别之间的概率转移取决于另一个因子的级别。请注意,学习自然语言的因子结构是许多研究的重点:例如,使用循环神经网络进行神经语言建模(Bengio等人,2003年;Mikolov,2010年;Mikolov等人,2013年;Shang等人,2015年)或序列到序列建模(Bahdanau等人,2014年;Ghazvininejad等人,2018年;Sutskever等人,2014年;Vinyals和Le,2015年)。
我们没有考虑语言习得;例如,通过学习上述的A、B和D参数(Al-Muhaideb和Menai,2011年;Bengio等人,2009年;Friston等人,2016年)。原则上,通过倾听权威的一系列问题和答案,应该可以通过结构学习和贝叶斯模型缩减来模拟不同层次的语言习得(Tervo等人,2016年)。这在抽象规则学习的背景下已经被研究过(Friston等人,2017b年),但尚未应用在当前背景下。在这一点上,我们接近了计算语言学所涉及的问题,通过使用层次狄利克雷过程(MacKay和Peto,1995年;Salakhutdinov等人,2013年;Teh等人,2006年)。在这种情况下,关键问题是优化模型的结构和层次形式,并知道何时添加额外的因子或级别。这种结构学习问题可能可以通过现有的关于层次狄利克雷过程模型和非参数贝叶斯的工作来有效解决(Goldwater,2006年);结合本文中提出的更自上而下的方法。
最后,我们的语法因子过于简化,仅涵盖了少数可能性。这对我们提出的模拟来说是足够的,但在这种生成模型的应用中将变得重要。关于语法加工的认知模型有大量的文献(有关最近的综述,请参见Demberg和Keller,2019年),以及听者如何处理语义歧义的研究(Altmann和Steedman,1988年;Bever,1970年;Gibson,1998年,2000年)。一般而言,来自视觉范式的证据(Kamide等人,2003年)表明存在一种预测性过程,这与主动推断的广泛一致。还有人提出语法本身可能是分层的(Van Schijndel等人,2013年)。
总之,我们提出了一个能够模拟合成主体之间交流的生成模型和推断方案。这个生成模型是深层和分层的:在更高的层次上推断会影响在更低层次选择的词语,而这些层次是嵌套的,这样短语级别的推断将生成短语中包含的词语,然后更低的层次会为下一个短语“重置”。我们对“二十个问题”游戏的模拟显示,代理能够选择最佳问题——询问另一个人——以最大程度地减少他们对谈话主题的不确定性(以贝叶斯最优的方式)。我们还展示了,如果代理对场景的性质有明确的信念,它可以正确回答另一个代理的问题。这些类型的交流表明了信念的收敛,反映了成功的语言交流。我们还模拟了这样一种情况:如果代理的信念非常不确定,它将承认自己的不确定性。如果两个代理都从不确定的信念开始,那么它们的生成模型将会收敛,尽管两个代理都不知道场景的真实状态。这种情况可以被视为一种共病妄想或联合创造性思维的例子。
最后,这种通信的制定为基于信念更新的神经生理反应提供了预测。当答案与代理的信念不一致时,它预测了违反反应,例如P300和N400反应,并显示出信念更新的新兴特性,如θ-γ耦合。总体而言,我们设想这个模型将是模拟更复杂的语言交流的有用起点——包括元认知,或模拟语言习得。
附录 A. - 期望自由能:策略的变分自由能是关于在给定观察结果 o 下的近似后验分布
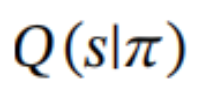
的泛函,在给定策略 π 的概率生成模型
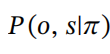
下。

第二个等式将自由能表达为Kullback-Leibler散度(即复杂度)和期望对数似然(即准确度)之间的差异,考虑到(观察到的)结果。

第一个等式以内在价值和外在价值的形式表达了期望自由能,而第二个表达式是对于预测偏好和先验偏好之间的差异(即风险)以及关于结果的预期不确定性的等效表述,考虑到它们的原因(即模棱两可性)。通过比较方程A.3和A.1,可以看出在特定策略下,风险是期望复杂度,而模糊性是期望的不准确性。
需要注意的是,为了完整和清晰起见,在上述方程式(以及表1中的表达式)中,我们已将先验偏好条件设置为策略。然而,在实践中,我们假设先验偏好不依赖于策略。
附录B. - 信念更新:近似贝叶斯推断对应于最小化变分自由能,关于构成后验信念的足够统计量。对于离散状态的生成模型,隐藏状态和策略的自由能可以表示为每个策略下的(时间相关的)自由能,以及关于(时间不变的)策略的后验信念所产生的复杂性,其中(经过一些简化)

Appendix C. Supplementary data
Supplementary material related to this article can be found, in the online version, at https://doi.org/10.1016/j.neubiorev.2020.07.005.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号