谈谈那些R处理结果中非常小的p值


这周转录组专辑将讨论,使用R语言进行分析,结果出现p值非常小的情况。这个问题来自上上周推文的留言区,而我们将从此入手进行探索,且并不局限在差异表达分析得到的p值。 问题来源:(DESeq2) Why are some p values set to NA?

这个问题,其实转录组专辑前面也有谈到
在开始生信菜鸟团的转录组专栏撰写之前,我认为做转录组差异分析比较简单,仅仅是流程上换个数据重复罢了,结果上应该大差不差。结果要么分组效果好(PCA效果好),差异基因数量比较显著,有继续分析的必要;要么分组效果不行(PCA效果不行),试试剔除显著离群样本或者去除批次效应,若再不行,分析意义不大。但是!!!,当我真正地去跑有文献对应的数据集时,我才发现自己太年轻了。活久见,前几天,我随机挑选了一个乳腺癌最近发表的转录组数据集做差异分析,飘飘然地以为就很快就能完成。但差异分析完后,我发现许多差异基因的p值竟然窜天高为零。这p值为零的现象真把我整不会了,我分析了挺多转录组数据,自己一直认为流程没问题。难道这时候发现我的流程有问题吗,那我怎么好意思和曾老师讲。吓得我战战兢兢的各种尝试,起初用的是edgeR包进行差异分析,换了DEseq2包分析之后发现p值还有一堆基因为零。战战兢兢的我只能向老师汇报了,老师说DEseq2与edgeR算法上比较相似,可能对于这些p值为零的基因判定比较松,给的p为零值。但是第三种差异分析的方式limma就不是,它用芯片分析的方法去做,给p值的判定比较严格。于是如获至宝的我,按照老师的指导进行了p值窜天高现象的探索与分析。
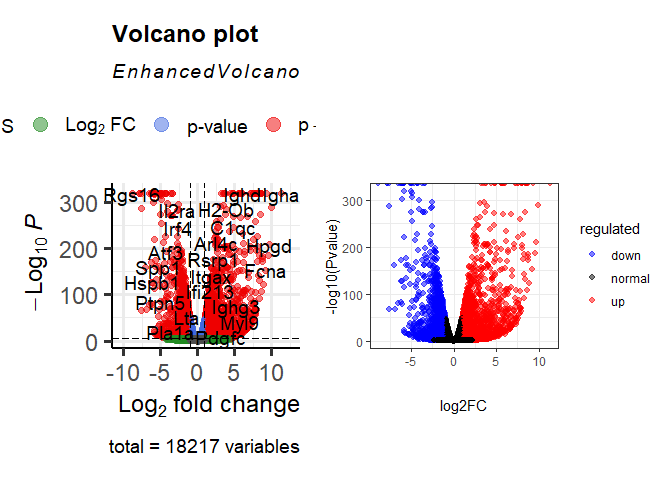
edgeR火山图
limma火山图
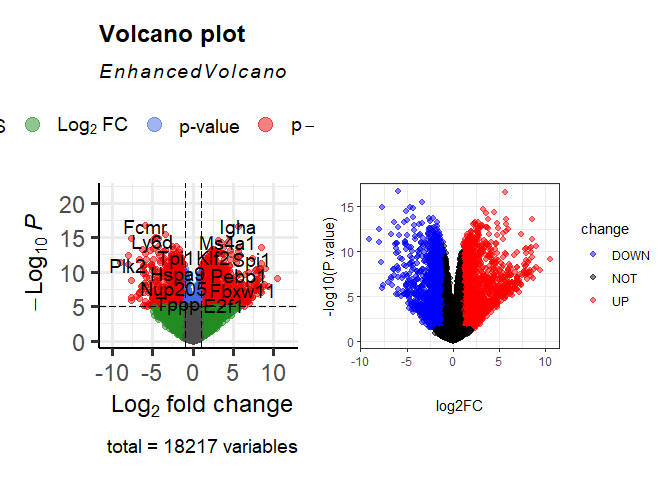
可以发现不同的工具对p值有着不同的控制程度,在DESeq2\edgeR中我们甚至可以发现p值为0的情况,那么p值小到什么程度会变成0呢,跳出p值,这么小的数在R中计算有意义吗?关于这些问题,我们将根据下面这个问题的回答展开讨论
How should tiny p-values be reported? (and why does R put a minimum on 2.22e-16?)
Q:对于R中的一些测试,p值计算有一个下限2.22E-16,我不知道为什么是这个数字,它是否有有充分的理由,或者只是随意的。许多其他统计数据包的精度仅为0.0001,因此这是一个更高的精度水平。但我没有看到太多的文章报道,p<2.22E-16或者p=2.22E-16。 https://stats.stackexchange.com/questions/78839/how-should-tiny-p-values-be-reported-and-why-does-r-put-a-minimum-on-2-22e-1
根据高赞回答

2.22E-16这样的一个下限可以通过下面的代码找到:
noquote(unlist(format(.Machine)))

AI回答参考:(部分解释我感觉还是不精确,这里仅作参考)
这段R语言代码的作是输出.R语言环境的硬件和软件配置信息,通过使用 .Machine变量来访问这些信息,然后使用 format函数对其进行格式化处理,再通过 unlist函数将其转换为向量,最后使用 noquote函数对向量中的元素进行输出,而不添加引号
这些返回结果给出了R语言环境的硬件和软件配置信息。以下是对每个返回结果的解释:
double.eps:双精度浮点数的机器精度,表示两个可表示的最近数字之间的最小非零间隔。double.neg.eps:双精度浮点数的负精度,即最接近零的非规约浮点数与零之间的最小差异。double.xmin:双精度浮点数的最小规约值,可表示的最小正数。double.xmax:双精度浮点数的最大规约值,即可表示的最大数。double.base:双精度浮点数的基数,通常为2。double.digits:双精度浮点数的有效位数。double.rounding:计算浮点数时的四舍五入规则。double.guard:保护位的个数,在具体情况下,可用于提高浮点运算的精度。double.ulp.digits:浮点数的单位最后一位的位数。double.neg.ulp.digits:负浮点数的单位最后一位的位数。double.exponent:双精度浮点数表示的数字的基数的指数范围。double.min.exp:双精度浮点数的最小指数。double.max.exp:双精度浮点数的最大指数。integer.max:整数的最大值。sizeof.long:long类型在字节数上的大小。sizeof.longlong:long long类型在字节数上的大小。sizeof.longdouble:long double类型在字节数上的大小。sizeof.pointer:指针类型在字节数上的大小。
通过 ?".Machine" 进一步了解
Note that on most platforms smaller positive values than .Machine$double.xmin can occur. On a typical R platform the smallest positive double is about 5e-324.
手动看看这个边界的-log10值
-log10(5e-324)
# [1] 323.3062
想到前面那个用edgeR差异分析绘制的火山图好像也是这个边界
数据集edgeR分析结果
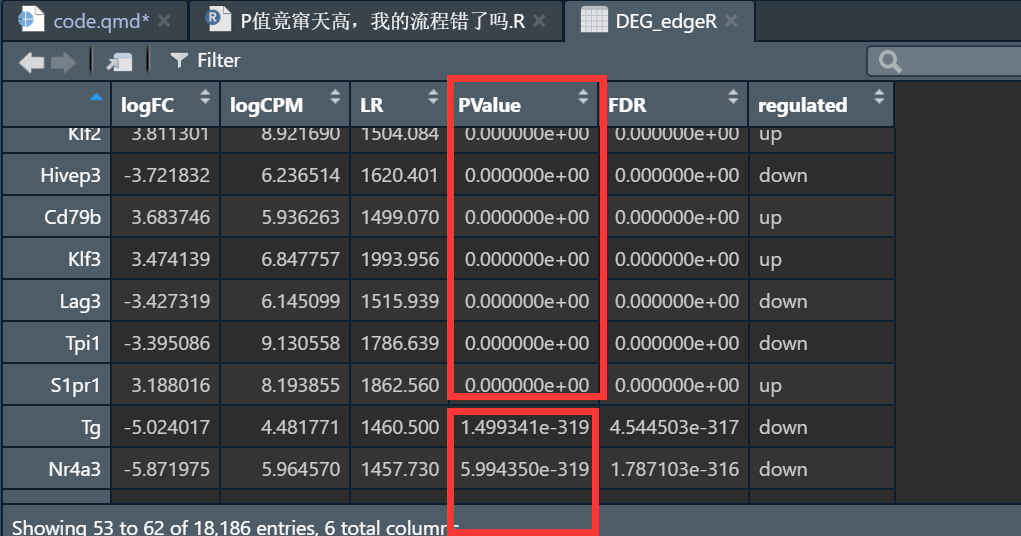
可以发现确实在5e-324范围内,超出这个范围就显示为0.000000e+00
这就是为什么我们有时发现-log10Pvalue可以达到两三百
这样,我们就知道了p值小到什么程度会变成0
回到这个问题:“How should tiny p-values be reported? (and why does R put a minimum on 2.22e-16?)”, 来看看,这么小的数在R中计算有意义吗?
double.eps:双精度浮点数的机器精度,表示两个可表示的最近数字之间的最小非零间隔
double.eps the smallest positive floating-point number x such that 1 + x != 1. It equals double.base ^ ulp.digits if either double.base is 2 or double.rounding is 0; otherwise, it is (double.base ^ double.ulp.digits) / 2. Normally 2.220446e-16.
根据前面 noquote(unlist(format(.Machine)))返回的结果2.220446e-16,我们来在自己的机器上验证这个最小加数
> 1+2.220446e-16==1
[1] FALSE
> 1+2.220445e-16==1
[1] FALSE
1+2.220446e-17==1
[1] TRUE
1+2e-16==1
[1] FALSE
1+1e-16==1
[1] TRUE
貌似仍不太精确,继续阅读

于是试一试1.110223e-16,这个数在 noquote(unlist(format(.Machine)))返回的结果中属于double.neg.eps(最小减数),并且恰为double.eps的一半

1+1.110223e-16==1
[1] TRUE
1+1.110224e-16==1
[1] FALSE
可以发现我的机器R语言中真正最小加数确实是1.110223e-16,那么真正最小减数是多少呢?
double.neg.eps:双精度浮点数的负精度,即最接近零的非规约浮点数与零之间的最小差异
double.neg.eps a small positive floating-point number x such that 1 - x != 1. It equals double.base ^ double.neg.ulp.digits if double.base is 2 or double.rounding is 0; otherwise, it is (double.base ^ double.neg.ulp.digits) / 2. Normally 1.110223e-16. As double.neg.ulp.digits is bounded below by -(double.digits + 3), double.neg.eps may not be the smallest number that can alter 1 by subtraction.
1-1.110223e-16==1
[1] FALSE
1-1.110222e-16==1
[1] FALSE
1-1.110223e-17==1
[1] TRUE
貌似也不是很精确,根据前面发现的一半的关系
1-(1.110223e-16/2) ==1
[1] TRUE
1-(1.110225e-16/2) ==1
[1] FALSE
发现真正的最小epsilon是我们 noquote(unlist(format(.Machine)))返回的结果的一半
有关机器精度可以阅读这份维基百科文档Machine epsilon https://en.wikipedia.org/wiki/Machine_epsilon
eps <- 2.220446e-16 # 初始估计
while (1+eps!=1) {
eps <- eps * 0.5
}
print(eps)
这段代码可以帮助我们快速估计自己的机器当前环境的计算精度所在范围
对于我们来说,p值作为统计显著性的重要指标,一般都很小,就如前面那样,如果大家使用DESeq2或者edgeR差异分析获取到非常小的p值,一般也在前面谈到的这些精度范围内
那么如何在文章中报道这些p值也是一门学问,这个问题的高赞回答认为:
没有一个通用的规则可以适用于所有情况,因为众多因素会影响到确定显著性水平的边界。这些因素包括具体的计算方式、假设的违背程度、审稿人和期刊的偏好等。由于不同人对结果的偏好和重视程度不同,所以无法提供一个确定的用来报道的截断点。 在具体操作中,有几种常见的方法可以处理非常小的p值。其中一种方法是区分p值是否小于某个特定的边界值,比如10^-6。对于小于该边界值的p值,我们通常仅强调其非常小而不赋予具体意义。另一种方法是将其一般化为比较小的区间,如10^-5到10^-4之间,并指出p值远远小于该区间。也可以进行模拟分析,通过违反假设的模拟结果来评估p值的稳健性,从而为选择截断点提供参考。 在提交至期刊时,最好期刊是否有特定的规定。如果期刊没有规定,可以根据个人偏好进行选择,并在等待审稿人的意见时进行调整。 总之,确定值的截断点是一个复杂的问题,需要考虑多方素。没有一个通用的答案,这取决于具体情况和人们的偏好。
事实上,我们也可以看到一些报道所用的p值非常小
所以如果你真的对在文章中使用非常小的p值很介意,可以从以下几个方面入手
- 使用其他对p值更严格的分析方法,如差异表达分析中使用limma
- 或者使用多重检验校正后的p值,上周我们介绍了一个不基于p值的非参数打分控制FDR的工具clipper,使用Clipper控制FDR应对高通量数据分析p值失真问题,你也可以看看这样的工具
- 看看自己投稿的期刊有没有相关规定
- 在正文中强调p值小于该领域内常用截断阈值,如基因组中常见的5E-08、1E-05
小结
在这篇推文中,我们讨论了以下几个问题:
- 如何检查自己机器的机器精度
- R中p值小到什么程度会变成0
- 多大的数在R中计算有意义
- 如何在文章中报道很小的p值
以上,就是本篇全部内容
参考:
How should tiny p-values be reported? (and why does R put a minimum on 2.22e-16?) https://stats.stackexchange.com/questions/78839/how-should-tiny-p-values-be-reported-and-why-does-r-put-a-minimum-on-2-22e-1
Sanity check: how low can a p-value go? https://stats.stackexchange.com/questions/11812/sanity-check-how-low-can-a-p-value-go
Machine epsilon https://en.wikipedia.org/wiki/Machine_epsilon
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号