R语言改进关联规则挖掘Apriori在超市销售数据可视化
原创
R语言改进关联规则挖掘Apriori在超市销售数据可视化
原创
拓端
发布于 2023-08-03 22:10:21
发布于 2023-08-03 22:10:21
超市业已成为商业领域最具活力的商业业态,竞争也变得日益激烈。数据挖掘技术越来越多地服务于超市营销战略,本文在数据挖掘的基础上,深入分析了关联规则算法,研究算法的基本思想、算法的性质,并对算法进行详细的性能分析,比较了Apriori算法和改进Apriori算法。最后,采用R软件对超市数据进行挖掘,为超市营销提供策略。
同时,关联规则也成功地应用到了电影、图书、超市购物、制造业等社会生活的许多方面。
因此,本文为了验证Apriori算法的可行性,使用了来自超市交易数据集,采用了顾客在超市购买的数据进行分析,从这些数据中找出有价值的规则,从而为超市提供有价值的营销策略。
关联规则
关联规则挖掘是数据挖掘领域成果颇丰而且比较活跃的研究分支,用于寻找给定数据集中数据项之间的有趣的关联或相关关系。关联规则揭示了数据项间的未知的依赖关系,根据所挖掘的关联关系,可以从一个数据对象的信息来推断另一个数据对象的信息。
简介
本文主要采用R软件进行数据挖掘。R是ISL公司开发的数据挖掘工具平台,能够高效分析海量数据,每一个环节中都支持CRISP-DM行业标准,为用户提供了大量的人工智能、统计分析的模型,如神经网络,关联分析,聚类分析、因子分析等。它可以帮助用户轻松获取、准备以及整合结构化数据和文本、网页、调查数据,快速建立和评估模型。
应用
本文分别用Apriori算法和改进Apriori算法对数据进行处理挖掘,具体结果如下所示。
Apriori算法
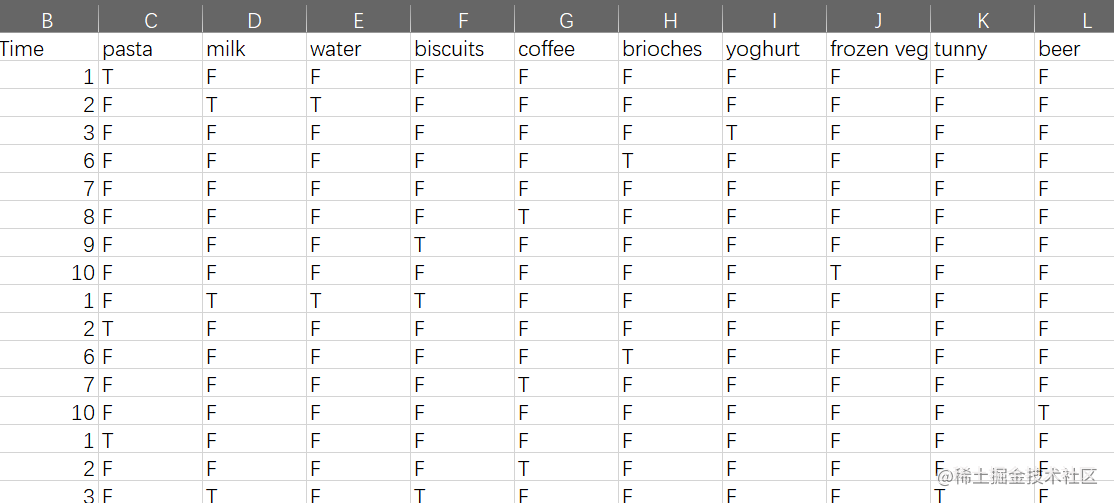
本数据采用了顾客在超市购买的数据进行分析,涉及意大利面、牛奶、水、面包饼干、咖啡、奶油蛋糕、酸奶、冷藏蔬菜、金枪鱼、啤酒、番茄酱、可乐、大米、果汁、咸饼干、油、冰冻鱼、冰淇淋、奶酪、罐装肉多种商品,如果顾客购买了该商品,则记为1,如果没有购买该商品,则记为0。
数据如图所示:
虽然 Apriori 算法可以直接挖掘生成表中的交易数据集,但是为了关联挖掘其他算法的需要先把交易数据集转换成分析数据集,构建的数据流如图 1 所示。
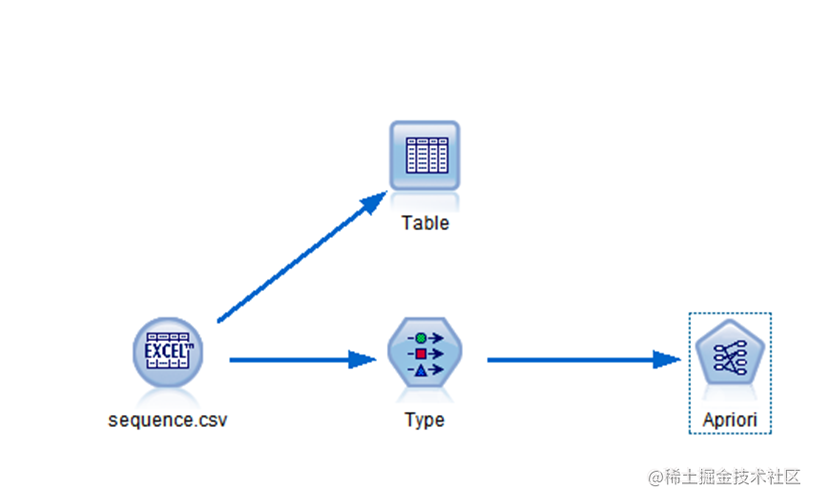
图 1 商品关联规则 Apriori 算法挖掘流图
1 commodity mining association rules Apriori algorithm flow graph
parameter=list(maxlen=10,support=support,confidence=confidence,minlen=i)
plot(rules为了找出每个物品在所有交易中出现的频繁程度,我们绘制了每个物品的频率直方图。
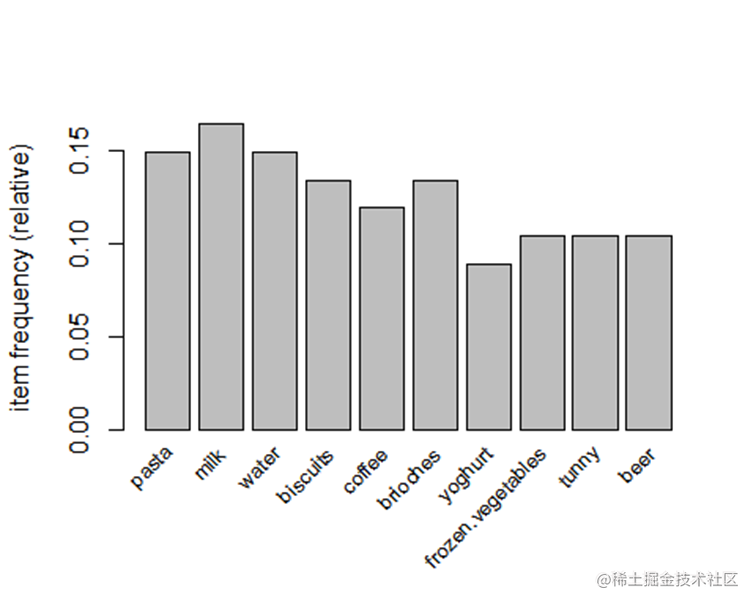
从上图,我们可以看到milk的出现次数是最多的,其次是water和pasta。而yoghurt的购买次数是所有物品中购买次数最少的物品。
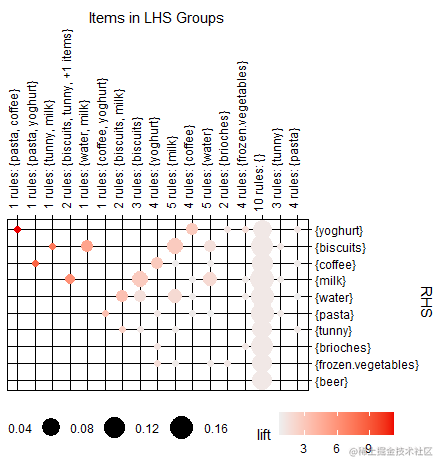
通过格式转换,发现数据源中共有二十种商品,设最低条件支持度为15%,最小规则置信度为30%,最大前项数为5,选择专家模式,挖掘出大类商品的15条关联规则,如下图所示。生成的15条规则如下所示:
inspect(rules.sorted)
从结果中可以看到,购买milk的顾客有52%的可能性会购买yoghurt,有51.53%的可能性会购买biscuit。
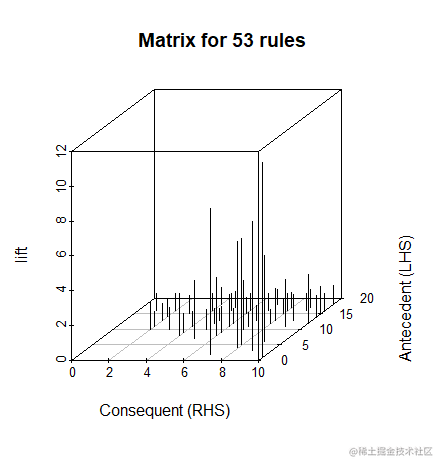
有49%的可能性会购买coffee。因此,把这些物品放在一起可能会促进销量。然后,我们将规则的LHS和RHS绘制成矩阵如下图所示。
plot(rules, methodft")
矩阵中的点的大小代表规则出现的频率。从矩阵中的点的大小,我们可以看到biscuite和milk在规则中出现的次数是比较多的,这也和它们在所有交易中出现次数较多一致。
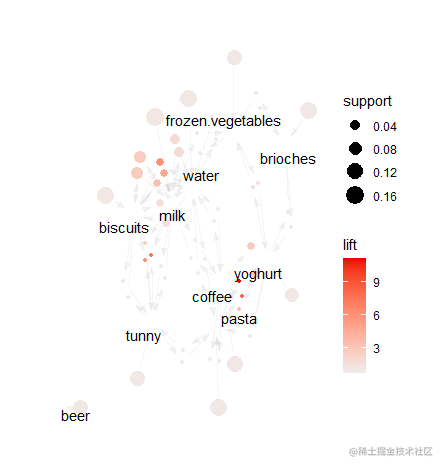
为了直观看出物品之间的联系,我们将规则绘制成网络图来表示。如下图所示。
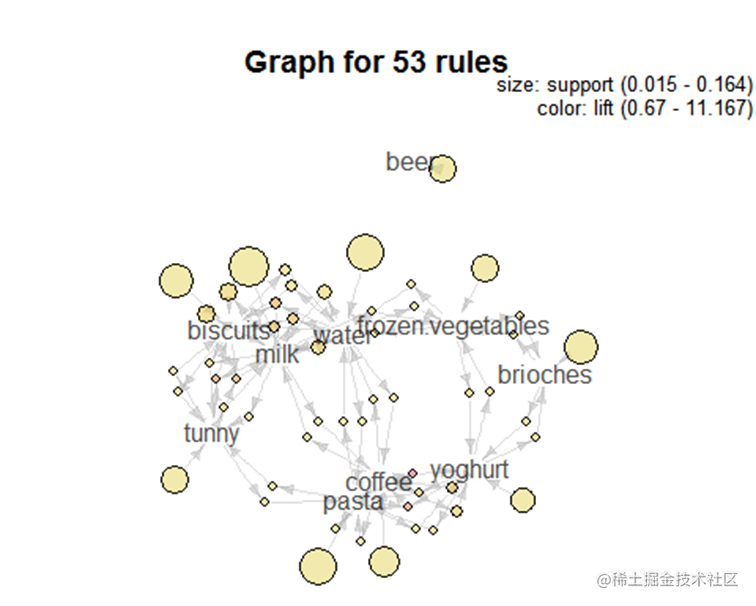
从上图可以看到milk和biscuit之间有较强的联系,说明顾客中同时购买两个商品的可能性较大。另外。Coffe和pasta的联系也较强,说明顾客同时购买pasta和coffee的可能性也较大。为了查看所有规则的总体情况,我们将规则用如下的散点图表示。从下图可以看到规则的置信度在0.2到0.7之间较多,支持度在0.1到0.2之间。总的来说,得到的规则具有较高的置信度。
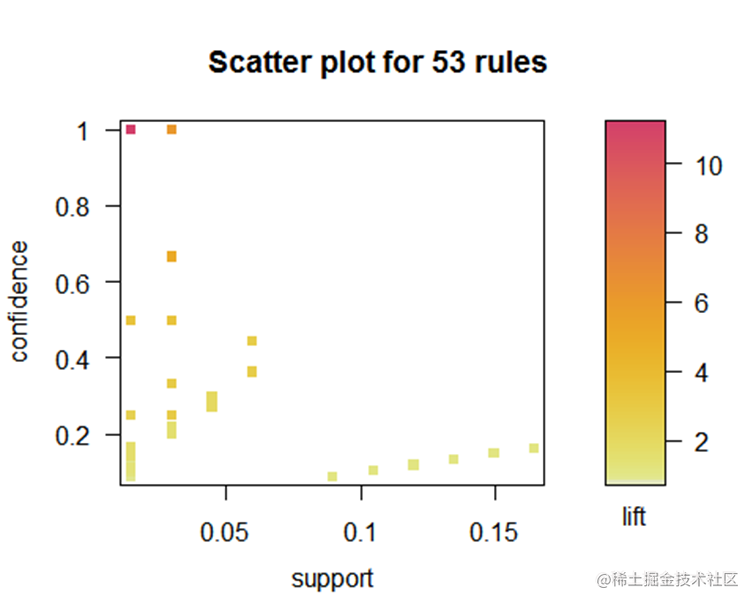
分析及建议: 通过图 2 可以清晰的看到购买牛奶、意大利面、水、咖啡的顾客比较多,建议超市可以加大对这些商品的采购,由上述结果可知,同时购买牛奶、意大利面的情况占总订单数的46.132%,水和牛奶或意大利面和水分别占总订单数的27.851%,购买牛奶的人有45.855%会购买意大利面,46.704%的人会购买水,购买意大利面的人有34.824%会购买牛奶,有34.296%的人会购买水,由此可见,意大利面、水、牛奶这三种商品关联度较高,可以将意大利面、水、牛奶摆放在一块,从而增加销量。此外,在符合支持度和置信度的条件下没有顾客购买冷冻食、果汁等,建议有关人员减少这几种商品的进货量,但为了保持商品的多样性,还是要适当地进货。根据上述规则,公司在营销时可采取了如下策略:(l)将牛奶和意大利面放置在一起或进行捆绑销售;(2)使小甜饼和咖啡、牛奶三种不同种类商品的货架相邻,方便顾客购买。(3)营业员在顾客购买了一种商品后,适当推荐另一种商品,如顾客购买了牛奶可以对其推荐小甜饼。(4)在生产与发货运输上将关联产品配套安排。采取这些措施后,顾客的交叉消费大为提高,商场与顾客的满意度也有所提高。
改进CRApriori
"CRApriori"是一个算法的改进版本,该算法是基于Apriori算法的一种频繁项集挖掘算法。
Apriori算法是一种用于挖掘频繁项集的经典算法。该算法通过扫描事务数据库来识别频繁项集,然后使用频繁项集生成关联规则。然而,Apriori算法在处理大规模数据集时效率较低,因为它需要多次扫描数据库。
CRApriori算法是对Apriori算法的改进。它通过压缩数据库的方式来提高算法的效率。具体来说,CRApriori算法使用压缩后的数据结构来存储事务数据库,这样可以减少扫描数据库的次数,从而提高算法的执行速度。
CRApriori算法的改进主要体现在以下几个方面:
- 数据库压缩:通过压缩事务数据库的方式,减少了算法需要扫描数据库的次数,从而提高了算法的效率。
- 频繁项集生成:CRApriori算法使用压缩后的数据结构来生成频繁项集,这样可以减少生成频繁项集的时间。
- 关联规则生成:CRApriori算法使用压缩后的数据结构来生成关联规则,这样可以减少生成关联规则的时间。
总而言之,CRApriori算法是对Apriori算法的改进版本,通过压缩数据库的方式提高了算法的效率,特别是在处理大规模数据集时具有较好的性能。
运用改进算法CRApriori删除事务集中不包括候选项集Ci即频繁i-1项集L(i-1):
改进算法CRApriori
CRApriori=function(support,confidence){
for(i in 1:2){
#parameter=list(support=support,maxlen=i)
frequentsets <- eclat(trans,parameter=list(minlen=i,support=support,maxlen=i))
inspect(frequentsets)#查看i项频繁项集
#这里如果支持度选的比较大,也许没有10这么多,这里就不能写[1:10].
inspect(sort(frequentsets,by="support")[1:10])#排序后查看按置信度排序,挖掘出大类商品的6条关联规则,如下图所示。生成的6条规则如下所示:

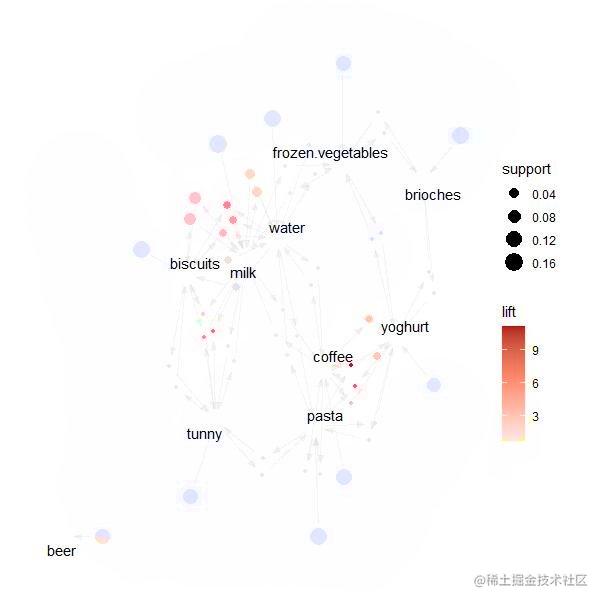
从上图可以看到milk和biscuit之间有较强的联系,说明顾客中同时购买两个商品的可能性较大。另外。Coffe和pasta的联系也较强,说明顾客同时购买pasta和coffee的可能性也较大。
总结
数据挖掘中的关联规则侧重于不同对象之间的联系,本文讨论了关联规则挖掘在超市销售中的应用。利用R 软件,通过实例分析了频繁项集及关联规则生成的过程,采用Apriori算法和改进Apriori算法对数据分别进行了解析挖掘,针对挖掘结果提出了相应的建议,对超市的发展有着重要的现实的意义。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号