多级缓存架构一致性问题解决


但是这篇文章主要讲的是缓存数据库读写顺序问题,并没考虑实际搭建场景,这篇文章面向实际开发应用
上一篇文章说的更多的是基础的解决,但是要分析缓存一致性问题,还是得从多级缓存架构方面来收。
真正回答缓存一致性解决方案的话,肯定得说一下上篇文章的延迟双删策略,对于这个策略的起源等问题以及在上篇文章解决了
这里策略主要是在真正搭建缓存解决数据库、缓存一致性问题的解决方案基础,当然真正多级缓存搭建的时候可以规避这个问题,就是和上一篇文章讲的最后的思路差不多,把缓存同步数据交给数据库去做,而不是程序,当然这个只能发生在弱一致的情况,当然想要用这种避免一致性问题,且实时性也保证的话也是有方案的
这篇文章我们进阶一下多级缓存架构下,缓存和数据库搭建的策略
多级缓存架构就是,将不同的缓存结合到一起,一起完成对应用程序的保护(减少对DB的请求)
这里提供三个方案,和一个方案的实操,不做ppt大师~
方案一:springboot + 本地缓存 + 分布式缓存(延迟双删解决一致性问题)
方案二:nginx + lua + 分布式缓存(延迟双删解决一致性问题)
方案三:nginx + lua + canal + redis架构(规避一致性问题)
本地缓存与分布式缓存的那些事儿
在讲这些方案之前,有必要探讨一下本地缓存和分布式缓存的那些事儿
springboot引入的本地缓存,和分布式缓存读的先后顺序,有一些说法,是先读取本地缓存还是先读取分布式缓存,这是由说法的,
对于不要求一致性,允许存在中间状态的情况,我们可以先取读本地缓存,再去读分布式缓存,这样就存在一种问题,就是如果命中本地缓存,那么应用程序读到本地缓存,就直接返回了,不会尝试去读分布式缓存,甚至不会从数据库中同步新的数据,对于这个问题,可以通过配置过期时间来搞定,
比如热点key的解决方案,通过本地缓存这种方案,那就是先请求读本地缓存,再去请求分布式缓存,这样做的话,但是本地缓存过期就会有一个问题,热点key的来源就是击垮分布式缓存,所以过期还是会出现问题,所以对于热点key的问题,不能单单的仅靠配置过期时间就可以解决了,热点key这个问题是比较特殊的,比如明星出轨,内容的话一般不会涉及更新,可以将本地缓存设置成永久,即使有同步,可以设置程序来主动的更新缓存,而不是由springboot去请求分布式缓存,以免击垮缓存,
对于普通方案,要设置本地缓存,因为设置本地缓存的初衷就是来分摊分布式缓存的压力,对于数据一致性,肯定是有问题的,或者,就不要采用本地缓存!,用Nginx去做
对于先读分布式缓存,目前遇到的只有一种
这种方法是在不借助Nginx下,通过数据库主动像缓存推数据规避缓存、数据库一致性问题
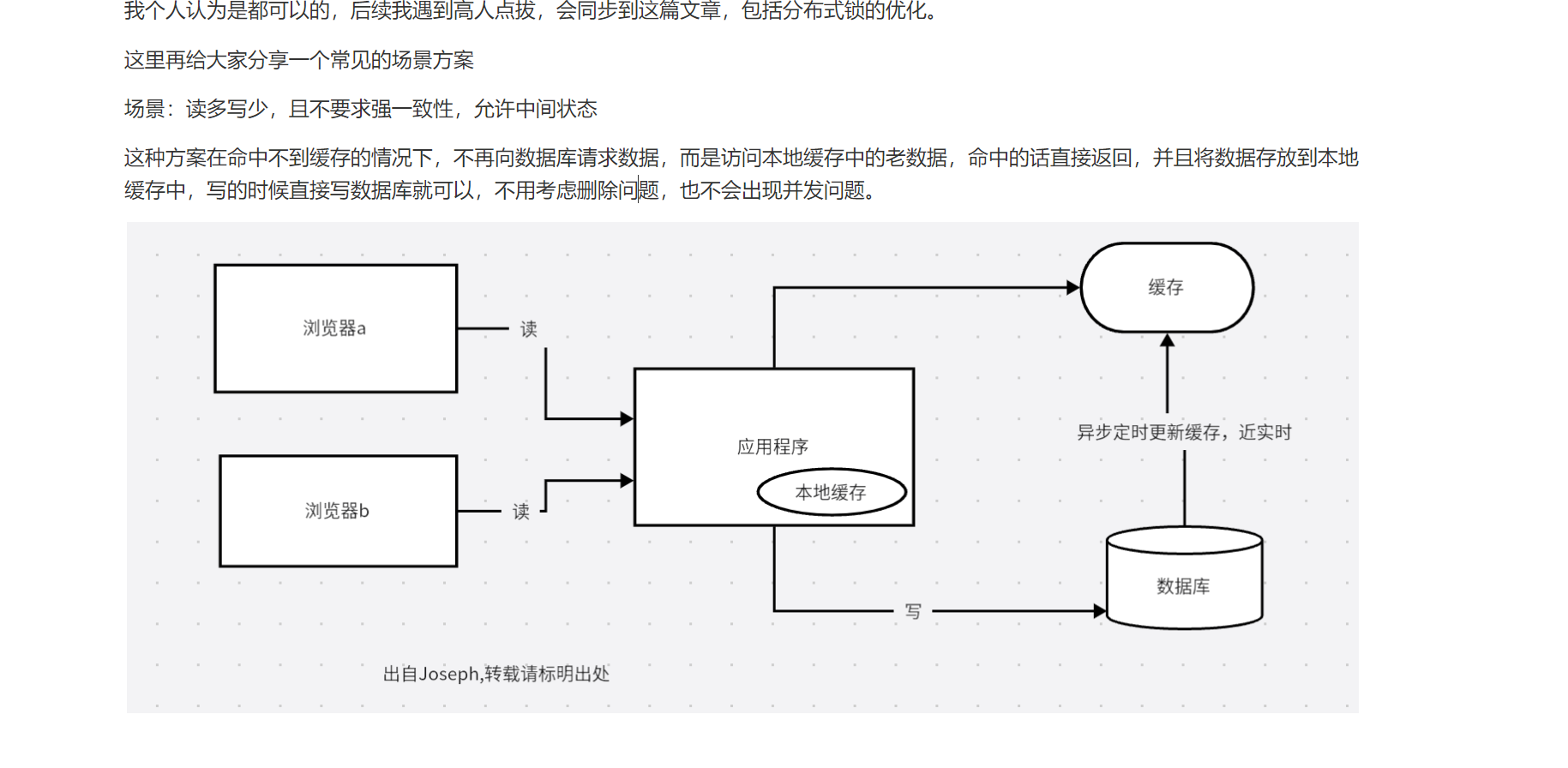
就是上一篇博客最后一部分讲的,这里需要通过本地缓存来实现缓存不命中的情况,缓存不命中,也就是说在分布式缓存中,key过期了,但是此时数据库还没推过来数据,就只能借助本地缓存来规避风险,本地缓存只是做了一个数据兜底,但是在近实时更新缓存的情况下,出现这种问题的概率不是很大。
在次的说一下,为啥方案二springboot中,没借助本地缓存呢?说的就是存在中间状态的情况,因为这样做,会出现说的,请求到本地缓存就直接返回了,且Nginx的性能是很高的,完全可以不借助本地缓存。通过Nginx的话,也有两种方案。下面着重分析这三种架构
至于本地缓存和分布式缓存的先后取舍,需要通过业务场景来决定
方案一:
springboot + 本地缓存 + 分布式缓存
对于本地缓存,需要通过springboot读取,基于tomcat,我们知道,tomcat线程池,以及连接池,默认最大的是200线程,我们调整最大连接数是1w,1w的连接,一个节点是1w,超过1w就会处理不了,几千万的日活,多部署几个节点两三w的qps,也是扛不住的,但是几十万日活的话,可以搞定
所以这种架构方案简单,但是通过springboot读取缓存,并发量是不高的
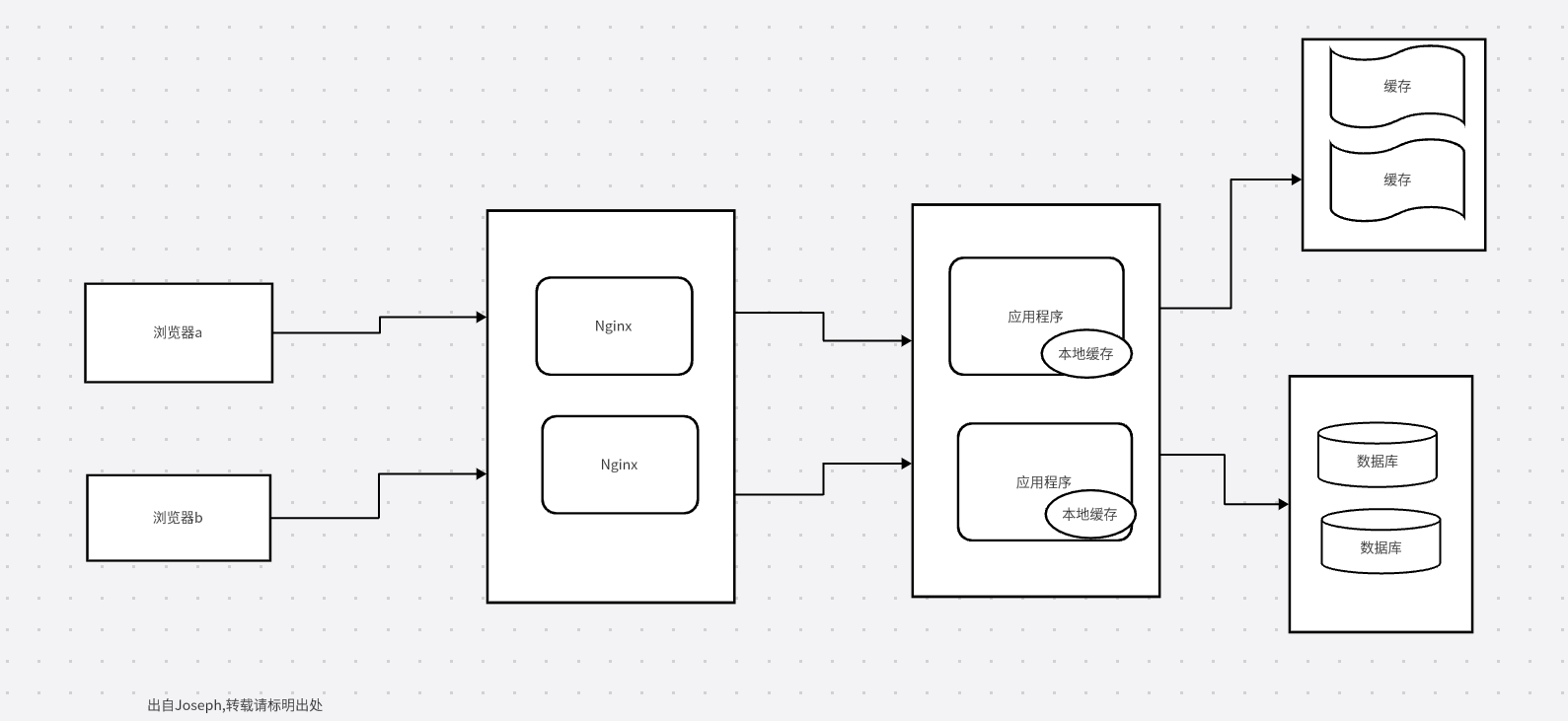
读取流程:采用的是延迟双删策略解决一致性问题,这里本地缓存和分布式缓存读取顺序策略是:先读本地缓存,读不到才去读分布式缓存,本地缓存与分布式缓存的一致性问题通过过期时间,或者分布式缓存定时更新来同步本地缓存来解决,所以我认为i这种方案是比较鸡肋的,但是架构简单,容易维护,,对应的缺点是并发量不高,存在一致性问题,既有数据库缓存一致性问题,也有本地缓存,
方案二
Nginx+lua+分布式缓存
这种方案,用Nginx,取消了本地缓存,也就没有了本地缓存与分布式缓存的一致性问题,Nginx的引入有这样一个好处,就是Nginx支持的并发是很高的,因为它直接是C语言编写,而spingboot是,java再到jvm,再到C语言,比如3个springboot节点,也只有3w的并发,但是一个Nginx,很轻松就能达到10w+,这性能提升的不止一倍,
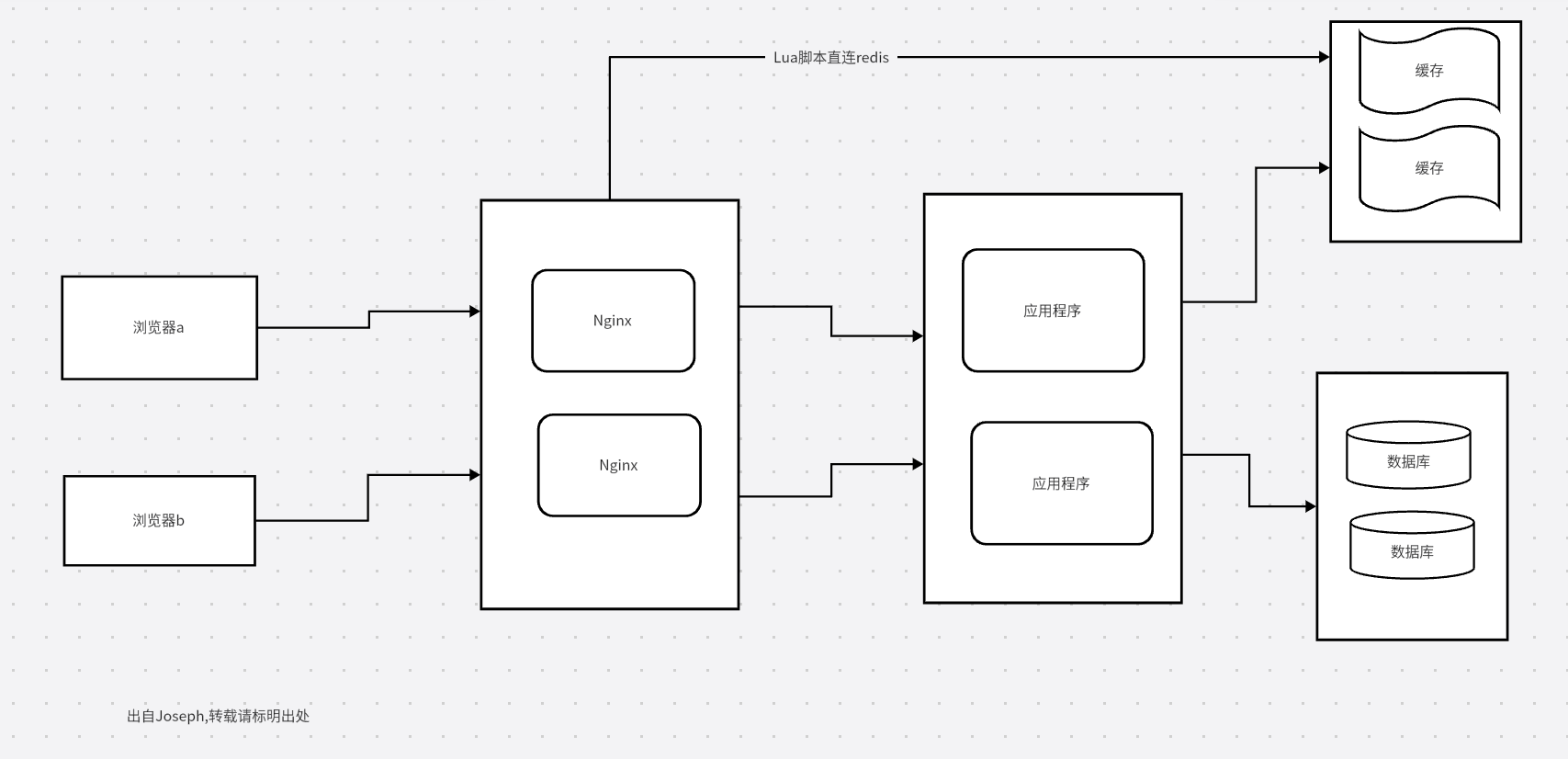
这种方案,在Nginx层处理大部分数据,小部分交给应用程序,但是这种方案,Nginx和应用程序都要去维护缓存与数据库的一致性,就比较繁琐,,那么下一种方案,就是来规避缓存与数据库的一致性!
方案三
方案1是一致性问题需要维护,以及并发量,方案2是解决了并发量,但是缓存一致性问题变的更复杂了,方案三,就是兼顾两者,通过canal推送,来规避一致性问题,nginx读缓存达到高的并发量
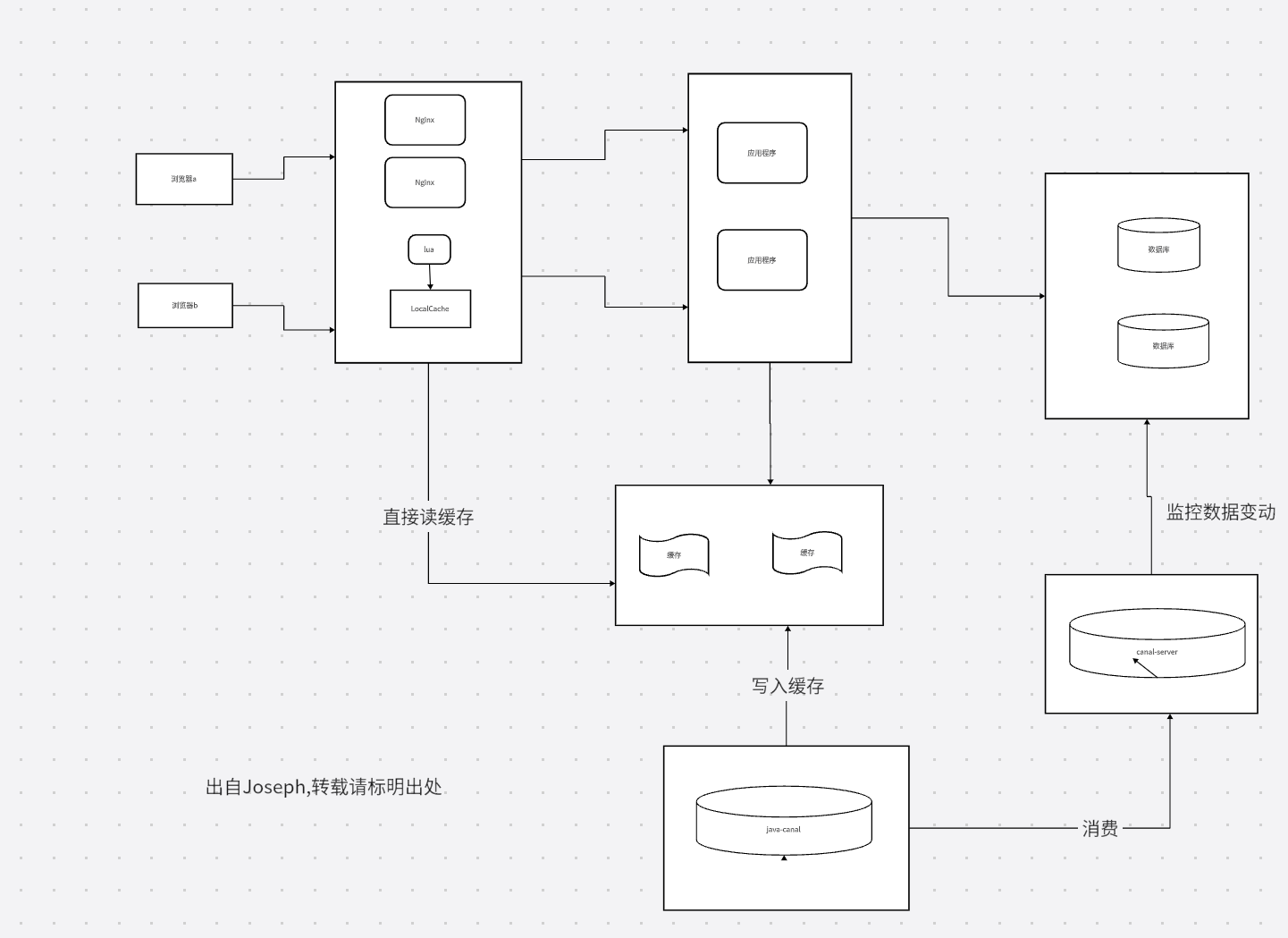
这个方案,通过canal监听数据的变动,通过java代码操作canal删除,再更新好redis缓存,避免了一致性问题,对应的缺点就是新增的逻辑,需要保证他们的可用。
实战为王:
这里实现下方案三,注意:应用程序到缓存,这里的兜底,不实现了因为这里是做兜底的,一般来说,nginx层都是可用去拦截到的,Nginx本地缓存,这里也不实现。
项目说明:
环境:springboot3.x mysql8.x jdk17
数据库配置:
CREATE TABLE `account` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(128) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL COMMENT '昵称',
`phone` varchar(524) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci DEFAULT NULL COMMENT '手机号',
`gmt_create` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC;
CREATE TABLE `product` (
`id` bigint NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`cover_img` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '封面图',
`amount` decimal(10,2) DEFAULT NULL COMMENT '现价',
`summary` varchar(2048) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '概要',
`detail` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_bin COMMENT '详情',
`gmt_modified` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`gmt_create` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin ROW_FORMAT=DYNAMIC;主从搭建,
cannal通过伪装成mysql的一个从节点,来完成对数据的监听,所以要像配置主从一样,对mysql进行配置,对于三种格式,我们选择row模式,
有statement格式,row模式,mixed模式,statement占空间小,是会有问题的,函数操作的时候,比如涉及到了uuid,这是肯定不可以的,这里点一个知识,RC隔离级别是不支持row模式的,因为它这个级别只有行锁,在主从同步下,会有问题,对应我在这篇文章有讲,检索”为何mysql把RR作为默认隔离级别”即可,mysql事物 | Joseph’s Blog (gitee.io)
对于搭建,我的mysql是通过这篇博客的方法搭建的,docker-mysql8.0踩坑敏感问题 | Joseph’s Blog (gitee.io)
所以配置文件,在这个基础上,再添加一些配置
# 开启 binlog, 可以不加,默认开启
log-bin=mysql-bin
# 选择 ROW 模式
binlog_format=row
#server_id不要和canal的slaveId重复
server-id=1添加进去,
[client]
#socket = /usr/mysql/mysqld.sock
default-character-set = utf8mb4
[mysqld]
log-bin=mysql-bin
binlog_format=row
server-id=1
#pid-file = /var/run/mysqld/mysqld.pid
#socket = /var/run/mysqld/mysqld.sock
#datadir = /var/lib/mysql
#socket = /usr/mysql/mysqld.sock
#pid-file = /usr/mysql/mysqld.pid
lower_case_table_names=1
datadir = /opt/datas/docker/mysql/data
character_set_server = utf8mb4
collation_server = utf8mb4_bin
secure-file-priv= NULL
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Custom config should go here
!includedir /etc/mysql/conf.d/vim /opt/datas/docker/mysql/conf/my.cnf
这个配置文件可用映射到容器中放进去就好了,然后重启容器
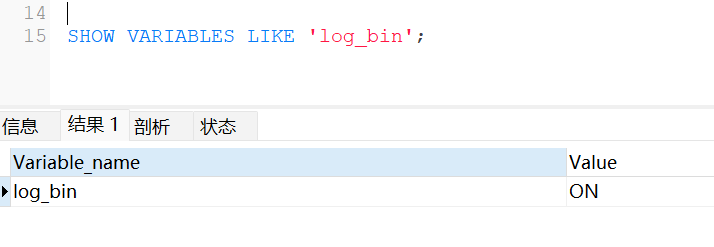
SHOW VARIABLES LIKE 'log_bin';
查看是否配置成功
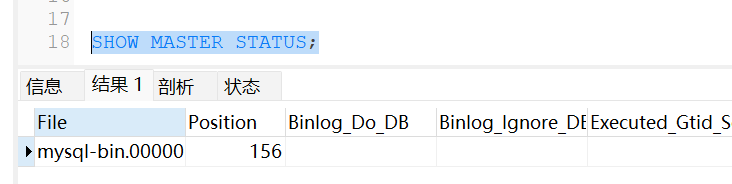
SHOW MASTER STATUS;
这个命令可用确定日志的文件名和位置,##只有root用户能查询binlog日志
好,继续,配置用户,给从节点授权配置,也就是给canal,(canal伪装成一个从节点)
-- 创建slave用户
CREATE USER 'joseph_canal'@'%';
-- 设置密码
ALTER USER 'joseph_canal'@'%' IDENTIFIED WITH mysql_native_password BY '123456789';
-- 授予复制权限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'joseph_canal'@'%';
-- 刷新权限
FLUSH PRIVILEGES;
#实际开发,当然要配置白名单,不能直接全部开放canal配置
将canal和mysql绑定
cannal容器
docker run -p 11111:11111 --name joseph_canal -d canal/canal-server:v1.1.4
#进入容器,配置文件修改
vi canal-server/conf/example/instance.properties注意修改注释的地方,手工修改
#################################################
## mysql serverId , 修改id,不要和mysql 主节点一致即可----------
canal.instance.mysql.slaveId=2
# enable gtid use true/false
canal.instance.gtidon=false
# 修改 mysql 主节点的ip----------
canal.instance.master.address=[你的ip]:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password 授权的数据库账号密码----------
canal.instance.dbUsername=joseph_canal
canal.instance.dbPassword=123456789
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# mysql 数据解析关注的表,正则表达式. 多个正则之间以逗号(,)分隔,转义符需要双斜杠 \\,所有表:.* 或 .*\\..*
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################重启容器,再进入容器
查看日志
tail -100f canal-server/logs/example/example.log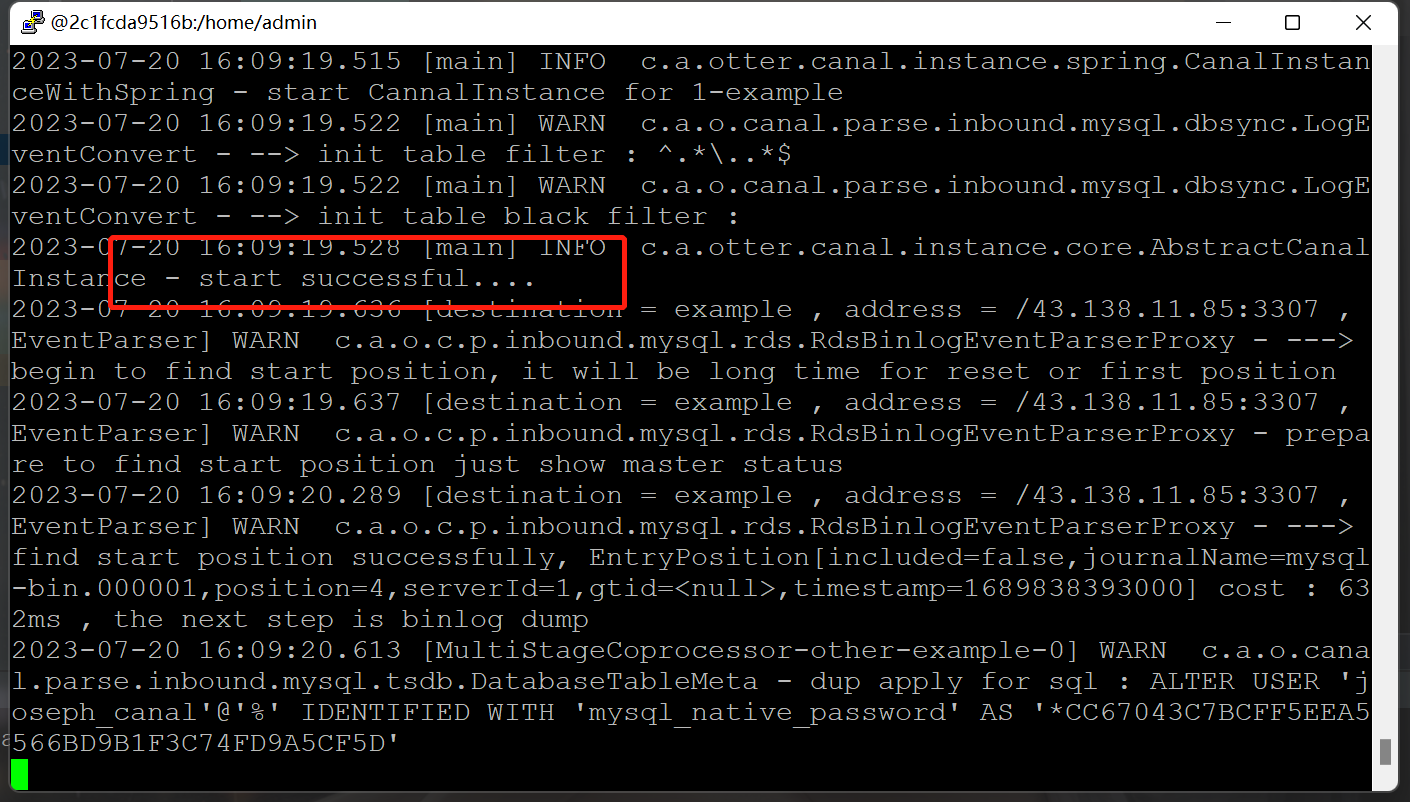
tail -10f /home/admin/canal-server/logs/canal/canal.log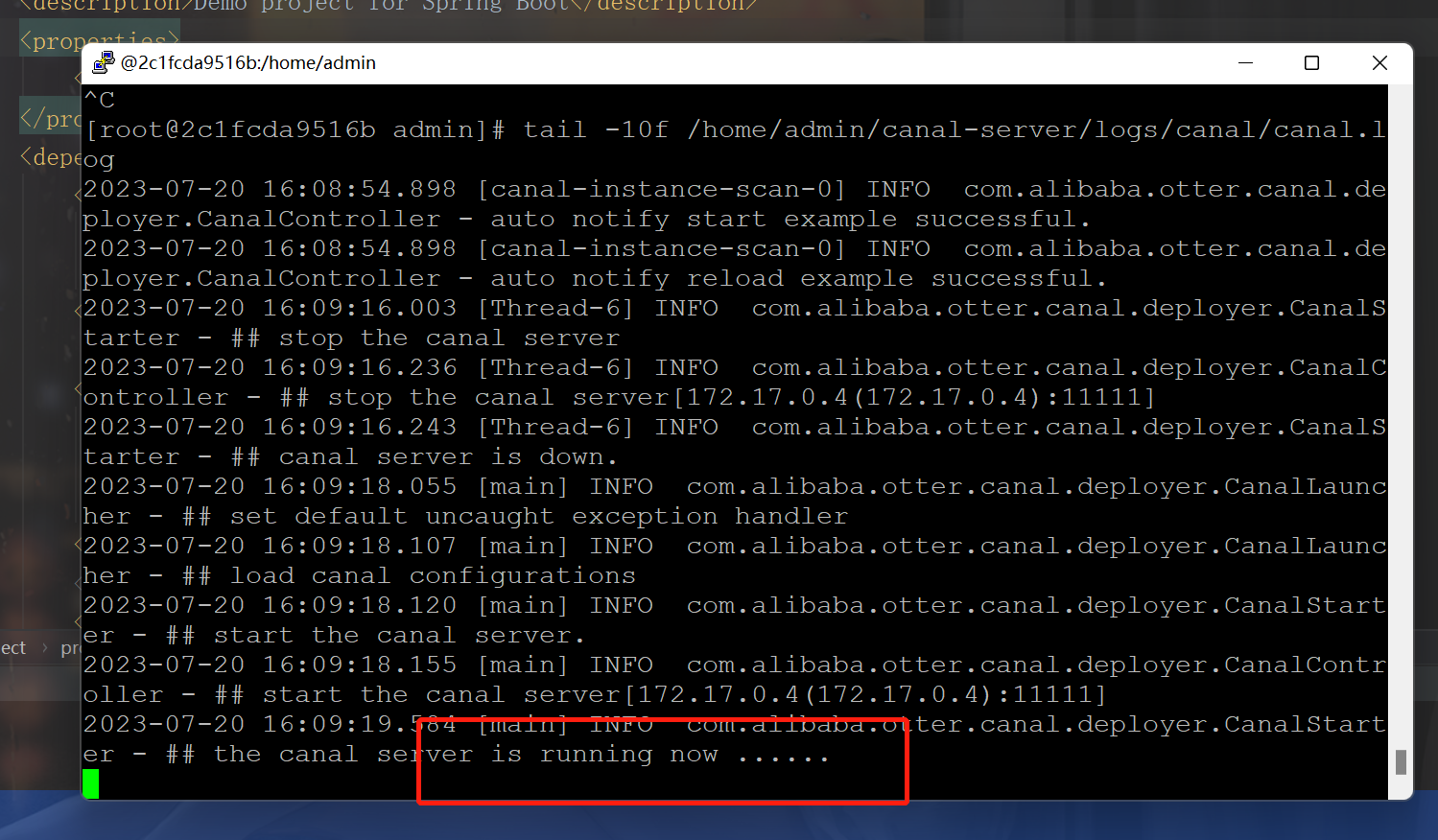
出现这两个就作对了
java实现
这里把除了Nginx操作缓存的部分,有关java程序的以及写好了,放在网盘里,需要的话自取
链接:https://pan.baidu.com/s/1Ry6SP1Y37hdChr3kHI6ltw
提取码:wl7y
--来自百度网盘超级会员V3的分享Nginx直连redis
Nginx是由C语言编写的,难以扩展,OpenResty,通过lua脚本,解决了这个问题,OpenResty继承了Nginx和lua的环境,我们想把Nginx直连缓存,只需要部署OpenResty就可以了
centos7.x安装
# add the yum repo:
wget https://openresty.org/package/centos/openresty.repo
sudo mv openresty.repo /etc/yum.repos.d/
# update the yum index:
sudo yum check-update
sudo yum install openresty
#安装命令行工具
sudo yum install openresty-resty
# 列出所有 openresty 仓库里的软件包
sudo yum --disablerepo="*" --enablerepo="openresty" list available
#查看版本
resty -V另外网关部署在云服务器,在网关层会做反向代理取请求应用程序的数据库,需要把程序打包到云服务器上,mvn install的jar包放上去好了,打包的话需要环境,我们程序是jdk17版本,所以要配置jdk17的环境

我是放到这个地方
jdk17放进去,配置环境
解压不说了,就是tar -zxvf

改个名
配个环境变量
#编辑文件,追加下面内容
vim /etc/profile
export JAVA_HOME=[你的jdk目录]
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#保存生效
source /etc/profile
#验证(如果还是旧的,需要重新进入终端)
java -version还需要把我发的网盘部署起来,mvn install,jar包运行到云上
lua直连
我的openresty放在这里/usr/local/openresty,进入nginx,然后mkdir一个lua文件夹
-- 引入需要使用到的库
local redis = require "resty.redis"
local redis_server = "【你的ip】"
local redis_port = 6379
local redis_pwd = "123456"
-- 获取 Redis 中存储的数据
local function get_from_redis(key)
local red = redis:new()
local ok, err = red:connect(redis_server, redis_port)
red:auth(redis_pwd)
if not ok then
-- 如果从 Redis 中获取数据失败,将错误信息写入 Nginx 的错误日志中
ngx.log(ngx.ERR, "failed to connect to Redis: ", err)
return ""
end
local result, err = red:get(key)
if not result then
ngx.log(ngx.ERR, "failed to get ", key, " from Redis: ", err)
return ""
end
-- 将 Redis 连接放回连接池中
red:set_keepalive(10000, 100)
return result
end
-- 获取缓存数据
local function get_cache_data()
-- 获取当前请求的 URI
local uri = ngx.var.uri
-- 获取当前请求的 id 参数
local id = ngx.var.arg_id
-- 将 URI 写入 Nginx 的错误日志中
ngx.log(ngx.ERR, "URI: ", uri)
-- 将当前请求的所有参数写入 Nginx 的错误日志中
ngx.log(ngx.ERR, "Args: ", ngx.var.args)
local start_pos = string.find(uri, "/", 6) + 1
local end_pos = string.find(uri, "/", start_pos)
local cache_prefix = string.sub(uri, start_pos, end_pos - 1) -- 截取第三个和第四个斜杠之间的子串
-- Redis 中键的名称由子串和 id 组成
local key = cache_prefix .. ":" .. id
local result = get_from_redis(key)
if result == nil or result == ngx.null or result == "" then
-- Redis 中未命中,需要到服务器后端获取数据
ngx.log(ngx.ERR, "not hit cache, key = ", key)
else
-- Redis 命中,返回结果
ngx.log(ngx.ERR, "hit cache, key = ", key)
-- 直接将 Redis 中存储的结果返回给客户端
ngx.say(result)
-- 结束请求,客户端无需再等待响应
ngx.exit(ngx.HTTP_OK)
end
end
-- 执行获取缓存数据的功能
get_cache_data()反向代理,以及已经命中不到缓存,去访问springboot配置
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#配置下编码,不然浏览器会乱码
charset utf-8;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
# 这里设置为 off,是为了避免每次修改之后都要重新 reload 的麻烦。
# 在生产环境上需要 lua_code_cache 设置成 on。
lua_code_cache off;
# 虚拟机主机块,还需要配置lua文件扫描路径
lua_package_path "$prefix/lualib/?.lua;;";
lua_package_cpath "$prefix/lualib/?.so;;";
#配置反向代理到后端spring boot程序
upstream backend {
server 127.0.0.1:8080;
}
server {
listen 80;
server_name localhost;
location /api {
default_type 'text/plain';
if ($request_method = GET) {
access_by_lua_file /usr/local/openresty/nginx/lua/cache.lua;
}
proxy_pass http://backend;
proxy_set_header Host $http_host;
}
}
}本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-06-15T,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号