GPT Engineer和Reflexion——构建AI工程和prompt的利器

GPT Engineer和Reflexion——构建AI工程和prompt的利器

山行AI
发布于 2023-06-26 10:45:32
发布于 2023-06-26 10:45:32
前言
众所周知,今天GPT发布了王炸级更新,主要功能有:新函数式调用功能、16K上下文、更低的价格等。在ChatGPT引领的AI浪潮下,涌现了一大批优秀的AI应用,AI正在不断地重塑一个又一个行业。在基于AI大模型构建应用时,大家应该也都逐渐意识到,一个好的prompt对于基于大模型的AI应用的重要性。本文将从今日居github热榜榜首的gpt-engineer出发,引申出对与该项目比较相关的Reflexion项目的介绍。相信大家能够从这两篇文章中学习到如何基于GPT进行工程开发以及如何构建一套提示词模型系统。
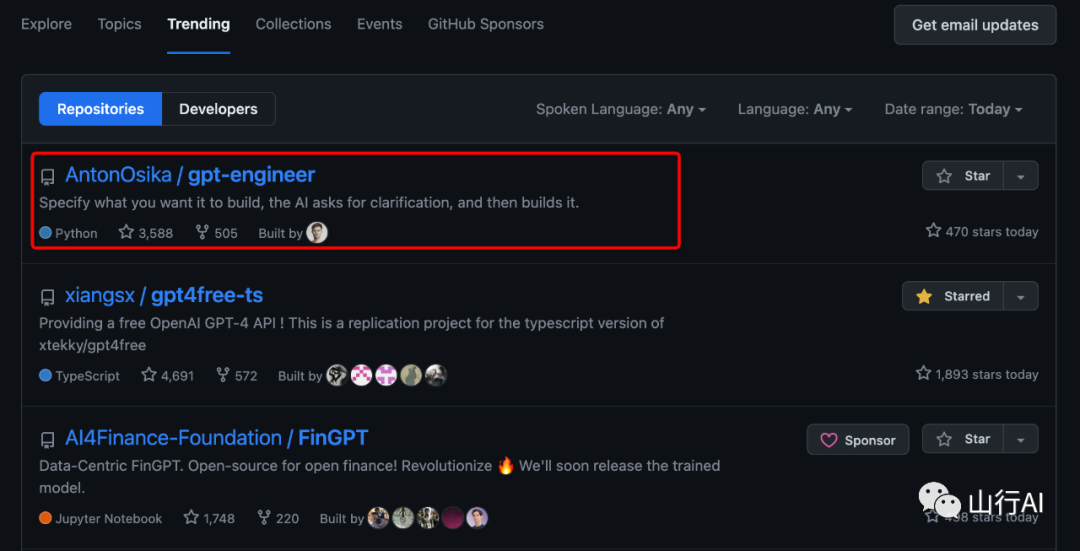
GPT Engineer
指定你想要构建的内容,AI会询问澄清问题,然后进行构建。
GPT Engineer的设计初衷是易于适应、扩展,并让你的代理学习你希望代码看起来的样子。它可以根据提示生成整个代码库。
项目理念
•简单获取价值•灵活且易于添加新的"AI步骤"。请参见steps.py。
•逐步构建以下用户体验:1.高级提示2.向AI提供反馈,让它随着时间的推移记住这些反馈•AI和人类之间的快速交接•简单性,所有的计算都是"可恢复的"并持久化到文件系统
使用方法
设置:
•pip install -r requirements.txt•export OPENAI_API_KEY=[你的api密钥] 使用具有GPT4访问权限的密钥
运行:
•创建一个新的空文件夹,并创建一个main_prompt文件(或复制示例文件夹cp example -r my-new-project)•在你的新文件夹中填写main_prompt•运行python main.py my-new-project
结果:
•查看在my-new-project/workspace中生成的文件
限制
实现额外的思维链提示,例如Reflexion[1],应该能够使其更加可靠,不会在主提示中遗漏请求的功能。
欢迎贡献者!如果你不确定要添加什么,可以查看GitHub仓库中的Projects标签页中列出的想法。
特性
你可以通过编辑identity文件夹中的文件来指定AI代理的"身份"。
编辑身份,并发展主提示,目前是你在项目之间让代理记住事情的方式。
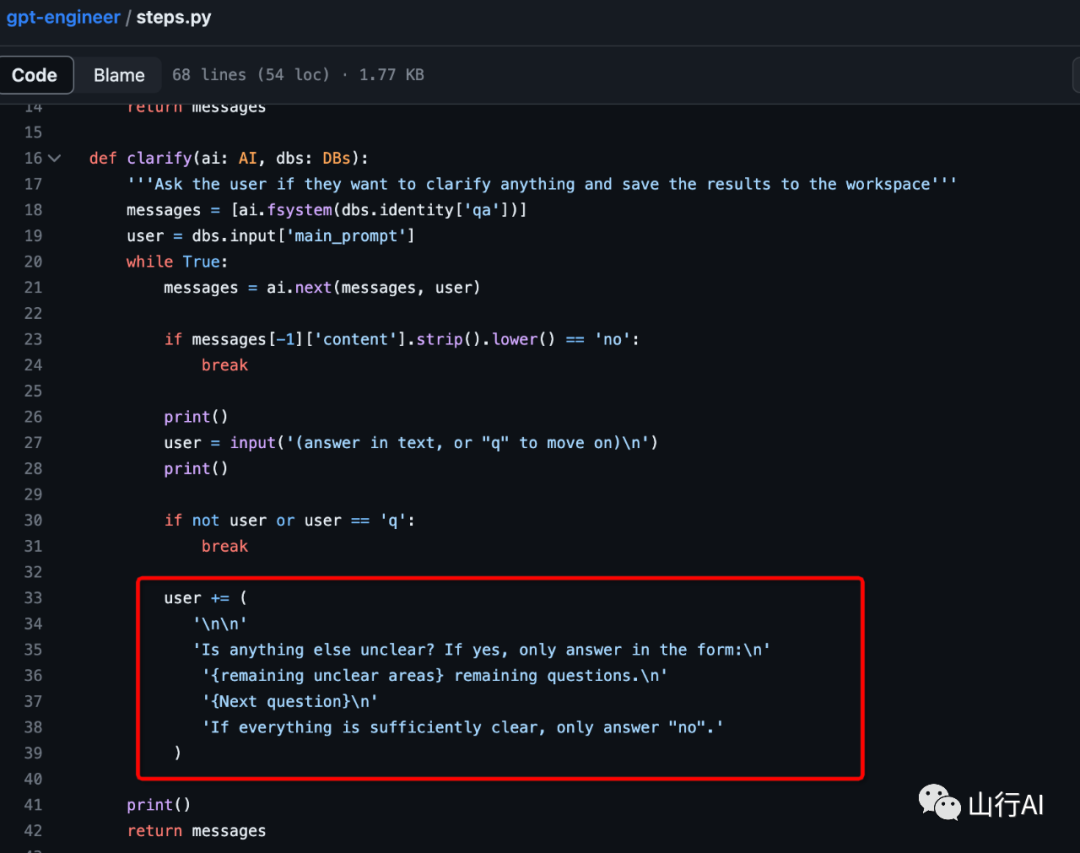
steps.py中的每一步都会将其与GPT4的通信历史存储在日志文件夹中,并可以通过scripts/rerun_edited_message_logs.py重新运行。
演示
演示视频链接[2]
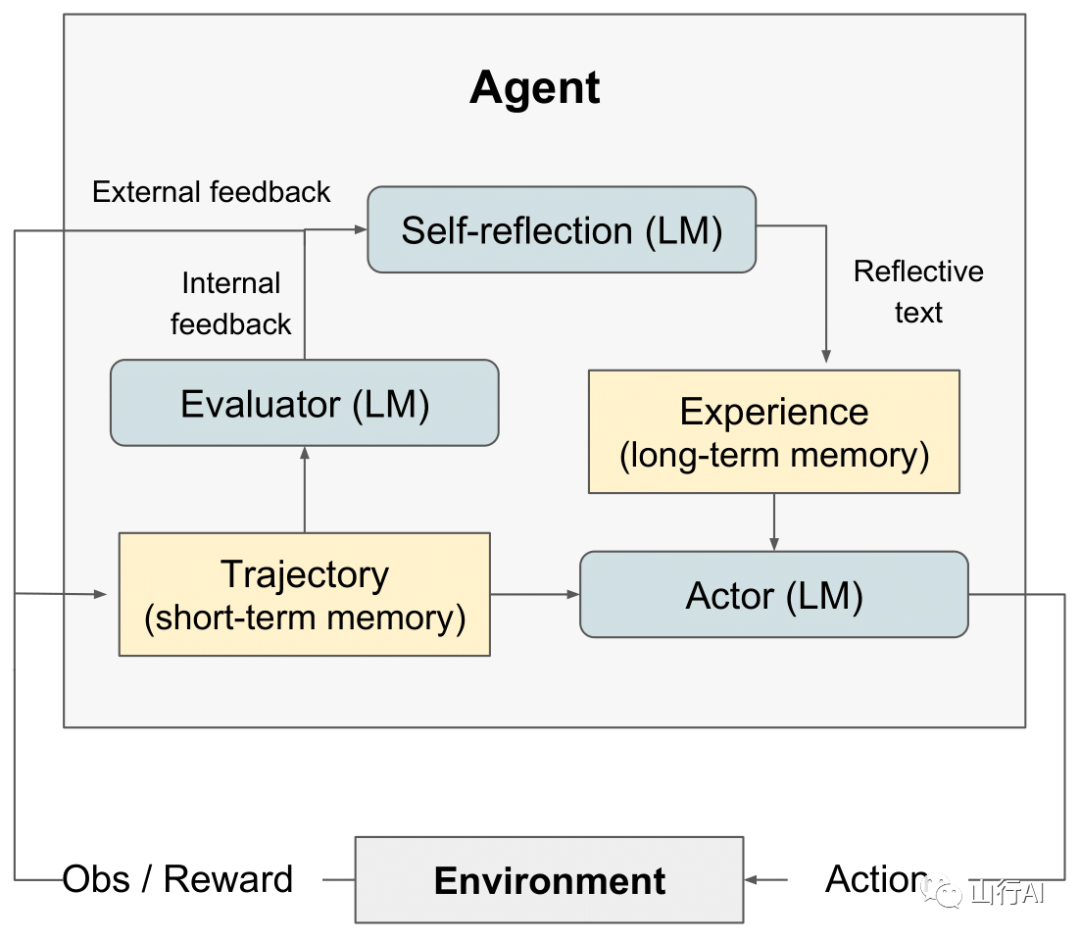
Reflexion是什么?
Reflexion:使用口头强化学习的语言代理
这个仓库包含了由Noah Shinn, Federico Cassano, Beck Labash, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao撰写的Reflexion:使用口头强化学习的语言代理[7]的代码、演示和日志。
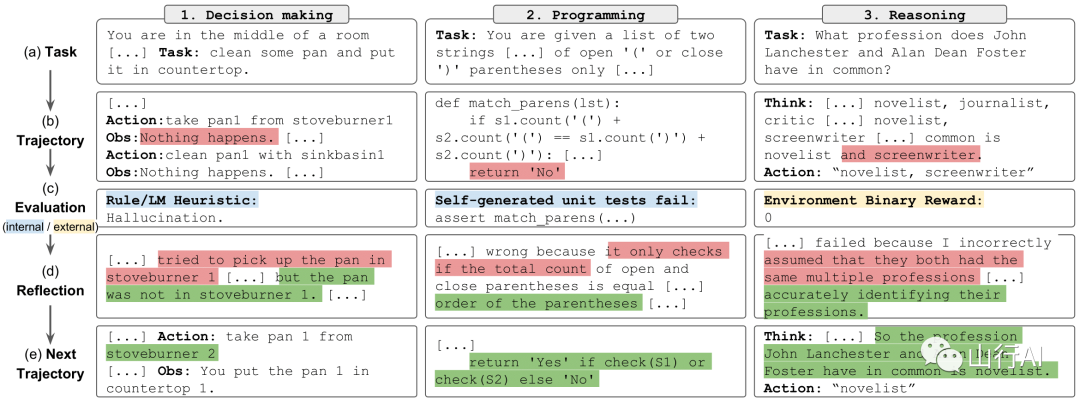
我们在这里[8]发布了LeetcodeHardGym。
运行:推理(HotPotQA)
我们提供了一套笔记本,方便您轻松运行、探索和与推理实验的结果进行交互。每个实验都包含了HotPotQA distractor数据集中随机抽取的100个问题的样本。样本中的每个问题都由具有特定类型和反射策略的代理尝试。
设置
开始之前:
1.克隆此仓库并移动到HotPotQA目录:
git clone https://github.com/noahshinn024/reflexion && cd ./hotpotqa_runs2.将模块依赖项安装到您的环境中:
pip install -r requirements.txt3.将OPENAI_API_KEY环境变量设置为您的OpenAI API密钥:
export OPENAI_API_KEY=<your key>代理类型
代理类型由您选择运行的笔记本确定。可用的代理类型包括:
•ReAct - ReAct 代理•CoT_context - CoT 代理,给出关于问题的支持性上下文•CoT_no_context - CoT 代理,不给出关于问题的支持性上下文
每种代理类型的笔记本都位于./hotpotqa_runs/notebooks目录中。
反射策略
每个笔记本都允许您指定代理使用的反射策略。可用的反射策略(在Enum中定义)包括:
•ReflexionStrategy.NONE - 代理没有得到关于其最后一次尝试的任何信息。•ReflexionStrategy.LAST_ATTEMPT - 代理得到了其最后一次尝试问题的推理追踪作为上下文。•ReflexionStrategy.REFLEXION - 代理得到了其对最后一次尝试的自我反思作为上下文。•ReflexionStrategy.LAST_ATTEMPT_AND_REFLEXION - 代理得到了其推理追踪和自我反思作为上下文。
运行:决策制定(AlfWorld)
克隆此仓库并移动到AlfWorld目录
git clone https://github.com/noahshinn024/reflexion && cd ./alfworld_runs在./run_reflexion.sh中指定运行参数。 num_trials:迭代学习步骤的数量 num_envs:每次试验的任务-环境对的数量 run_name:此次运行的名称 use_memory:使用持久内存来存储自我反思(关闭以运行基线运行) is_resume:使用日志目录恢复以前的运行 resume_dir:从中恢复以前运行的日志目录 start_trial_num:如果恢复运行,那么开始的试验编号
运行试验
./run_reflexion.sh日志将被发送到./root/<run_name>。
另一项注意事项
由于这些实验的性质,个别开发者可能无法重新运行结果,因为GPT-4的访问权限有限,且API收费显著。所有来自论文的运行和额外结果都记录在./alfworld_runs/root(决策制定)、./hotpotqa_runs/root(推理)和./programming_runs/root(编程)。
其他注意事项
查看原始草稿的代码这里[9]
阅读原始博客这里[10]
查看一个有趣的类型推断实现:OpenTau[11]
对所有问题,请联系noahshinn024@gmail.com
引用
@misc{shinn2023reflexion,
title={Reflexion: Language Agents with Verbal Reinforcement Learning},
author={Noah Shinn and Federico Cassano and Beck Labash and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao},
year={2023},
eprint={2303.11366},
archivePrefix={arXiv},
primaryClass={cs.AI}
}声明
本文翻译整理自:https://github.com/AntonOsika/gpt-engineer和https://github.com/noahshinn024/reflexion
References
[1] Reflexion: https://github.com/noahshinn024/reflexion
[2] 演示视频链接: https://github.com/AntonOsika/gpt-engineer/assets/4467025/6e362e45-4a94-4b0d-973d-393a31d92d9b
[3] Reflexion:使用口头强化学习的语言代理: https://arxiv.org/abs/2303.11366
[4] 这里: https://github.com/GammaTauAI/leetcode-hard-gym
[5] Reflexion:使用口头强化学习的语言代理: https://arxiv.org/abs/2303.11366
[6] 这里: https://github.com/GammaTauAI/leetcode-hard-gym
[7] Reflexion:使用口头强化学习的语言代理: https://arxiv.org/abs/2303.11366
[8] 这里: https://github.com/GammaTauAI/leetcode-hard-gym
[9] 这里: https://github.com/noahshinn024/reflexion-draft
[10] 这里: https://nanothoughts.substack.com/p/reflecting-on-reflexion
[11] OpenTau: https://github.com/GammaTauAI/opentau
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号