机器学习中的期望风险、经验风险、结构风险是什么?


要区分期望风险、经验风险、结构风险这三个概念,需要先讲一下损失函数L(Y,f(x))的概念。在机器学习中,损失函数主要是用来衡量模型的拟合程度,即表示模型预测值与真实样本值之间的差距。损失函数越小,说明模型拟合的越好,该模型对未知样本的预测能力也就越强。常见的损失函数如下图所示。本文以常见的平方损失函数来举例说明。



总结经验风险和期望风险之间的关系:
经验风险是局部的,基于训练集所有样本点损失函数最小化。经验风险是局部最优,是现实的可求的。
期望风险是全局的,基于所有样本点损失函数最小化。期望风险是全局最优,是理想化的不可求的。
所谓的经验风险最小化,指的是经验风险越小,模型对训练集的拟合程度越好。那么是不是经验风险越小越好呢?其实并不是的,因为经验风险越小,越有可能出现过拟合,如下图所示:
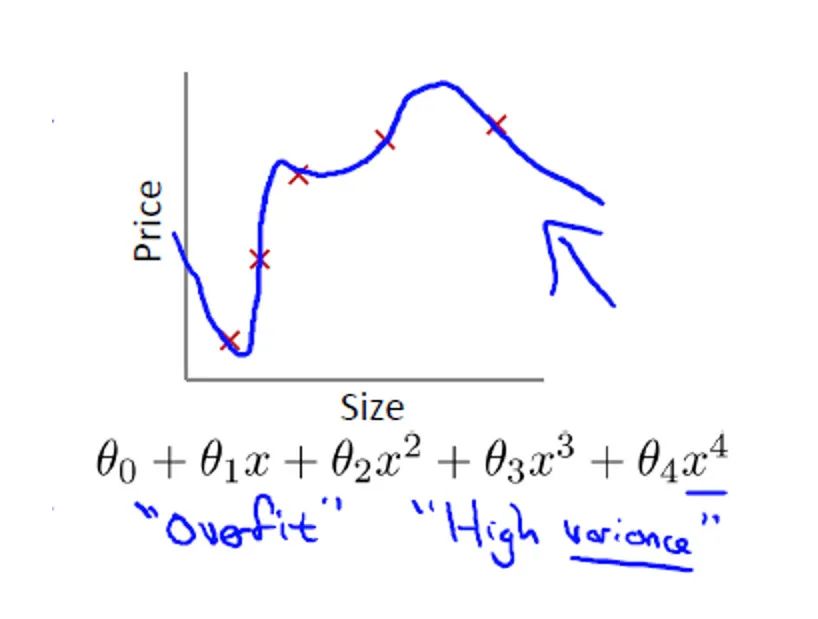

三、结构风险
所谓的结构风险指的是,在经验风险的基础上,加一个惩罚项(也叫正则化因子),从而减少模型出现过拟合的风险。公式如下:
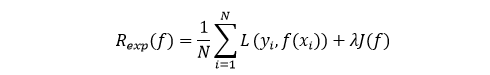
很多人看到这里可能会有点好奇,为什么加上一个惩罚项,就能降低模型过拟合的风险呢?第二部分介绍了经验风险最小化往往会出现过拟合,如下图最右侧所示。
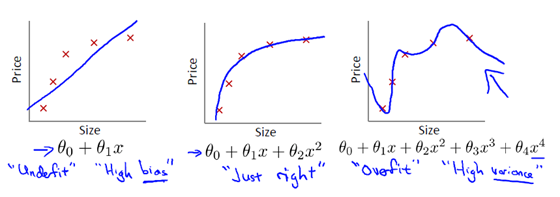
从上图中最左侧和最右侧对比中可以看出,模型出现过拟合的原因在于将原本一个低次项的函数拟合成一个高次项,提高了模型的复杂度。所以要想降低过拟合,办法就是要尽量使得和变小或者趋于0,从而降低模型的复杂度,使模型从一个高次项变成二次函数,如中间的图所示。
四、总结
1、期望风险,是全局的,针对所有的样本。是理想化的,不可求的。
2、经验风险,是局部的,针对的是训练样本。是现实的,可求的。
3、结构风险,是在经验风险的基础上加上惩罚项,目的是为了减少经验风险最小化带来的过拟合的风险。
Ps:
期望(或均值):是试验中每次可能结果的概率乘以其结果的总和。期望值是该变量输出值的平均数,期望值并不一定包含于变量的输出集合里。且大数定律规定,随着重复次数接近无穷大,数值的算术平均值几乎肯定地收敛于期望值。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-11-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号