分布式事务Seata(下)


4.1> 概述
- AT事务流程分为两个阶段,一阶段的主要流程如下所示:
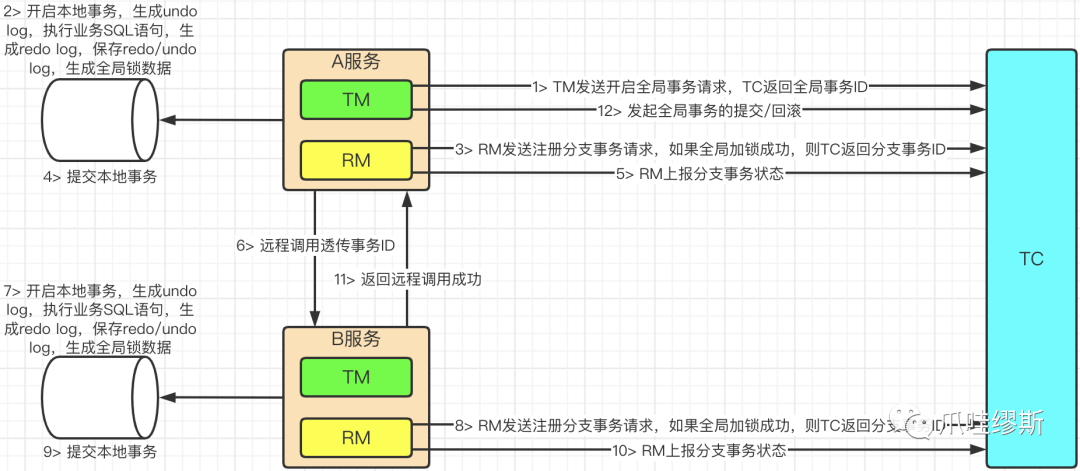
- 上面第一阶段执行完毕后。TC在收到全局事务提交/回滚指令后发起二阶段处理:
- 如果是全局事务提交,则TC通知多个RM异步地清理本地的事务日志。
- 如果是全局事务回滚,则TC通知每个RM回滚数据。
- 我们可以看到第二阶段中,针对于事务回滚的操作,是基于事务日志来实现的。那么下面我们来介绍一下事务日志表
4.2> 事务日志表结构分析
- 事务日志表——undo_log,表结构如下所示:
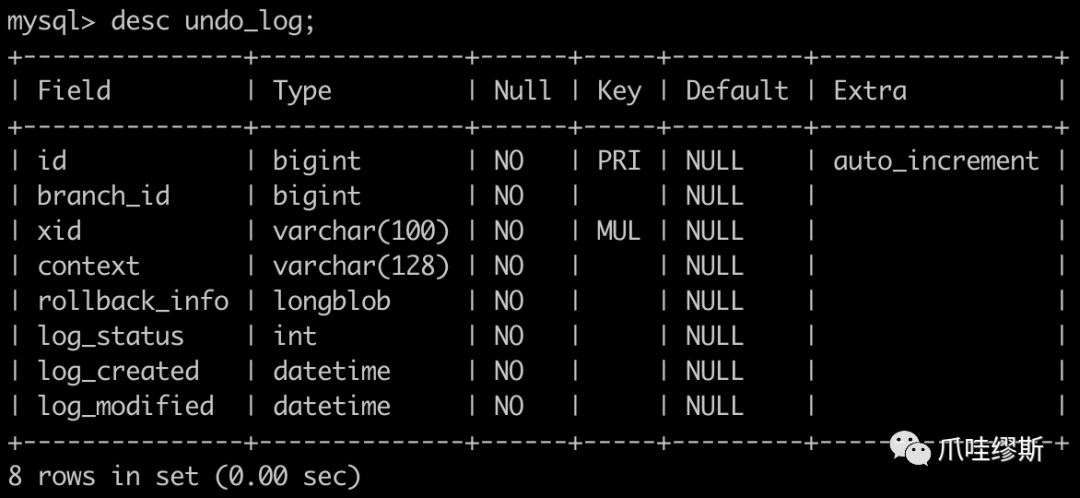
- undo_log中的rollback_info字段是整个表中的核心字段,里面保存着完整的undoLog信息
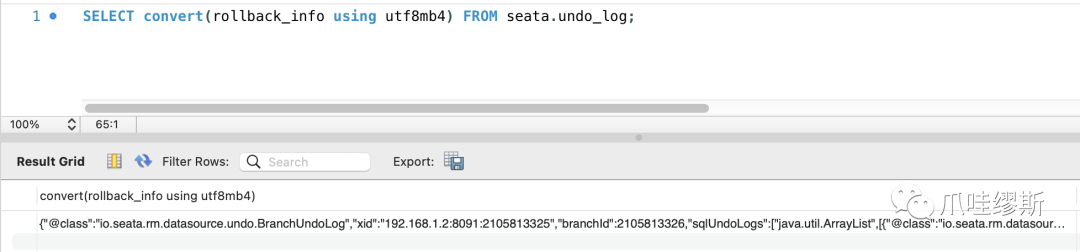
- undoLog表中rollback_info中存储的内容,如下所示:
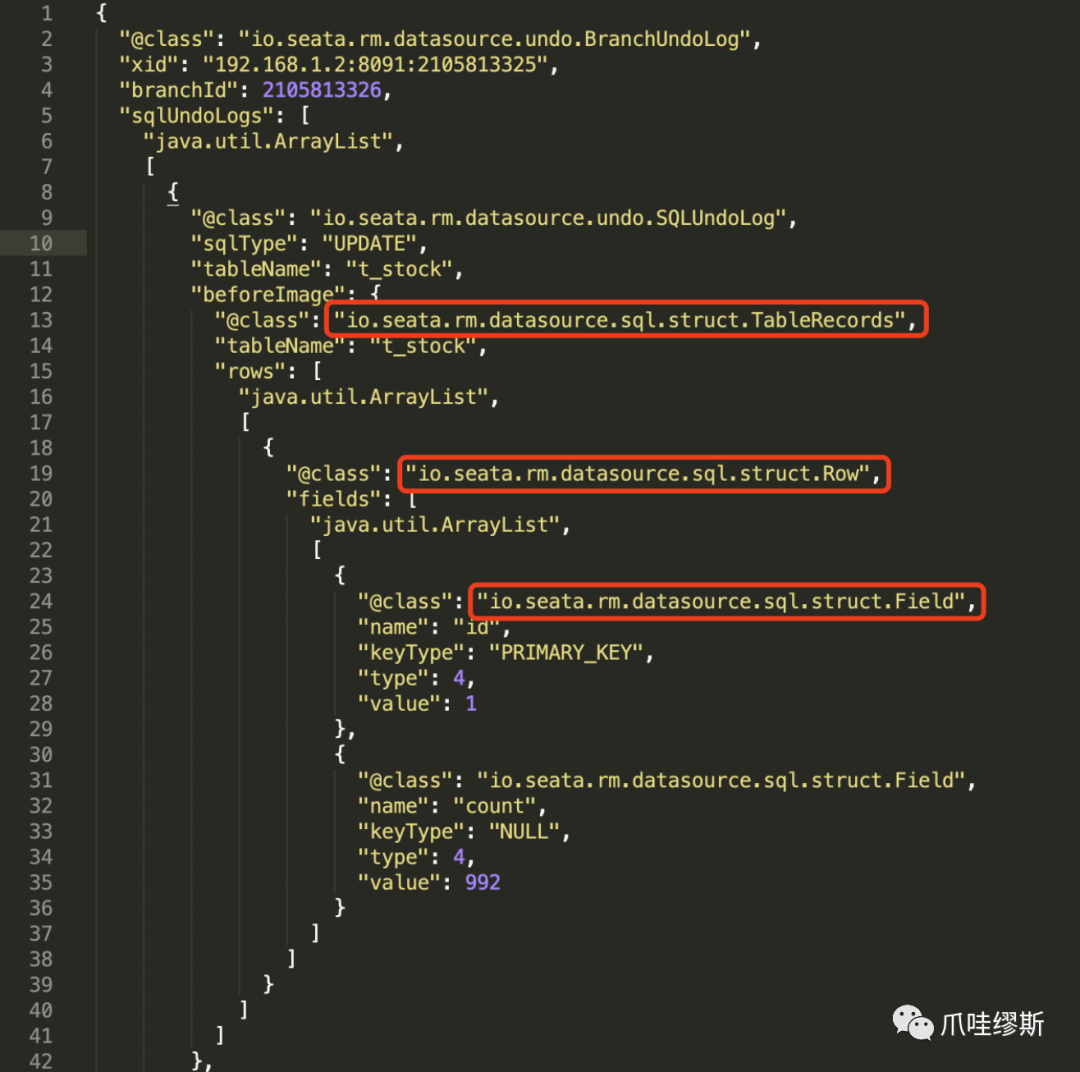
【解释】
- 从上图中,我们可以看到json中包含两个部分,分别是:beforeImage和afterImage。
- beforeImage就是“写”操作之前的数据备份,我们称之为:前镜像。
- afterImage就是“写”操作之后的数据备份,我们称之为:后镜像。
- 针对于insert操作来说,beforeImage为空,afterImage就是新插入行的数据。
- 针对于delete操作来说,beforeImage就是删除前的数据,afterImage为空。
- 针对于update操作来说,beforeImage就是更新前的数据,afterImage是更新后的数据。
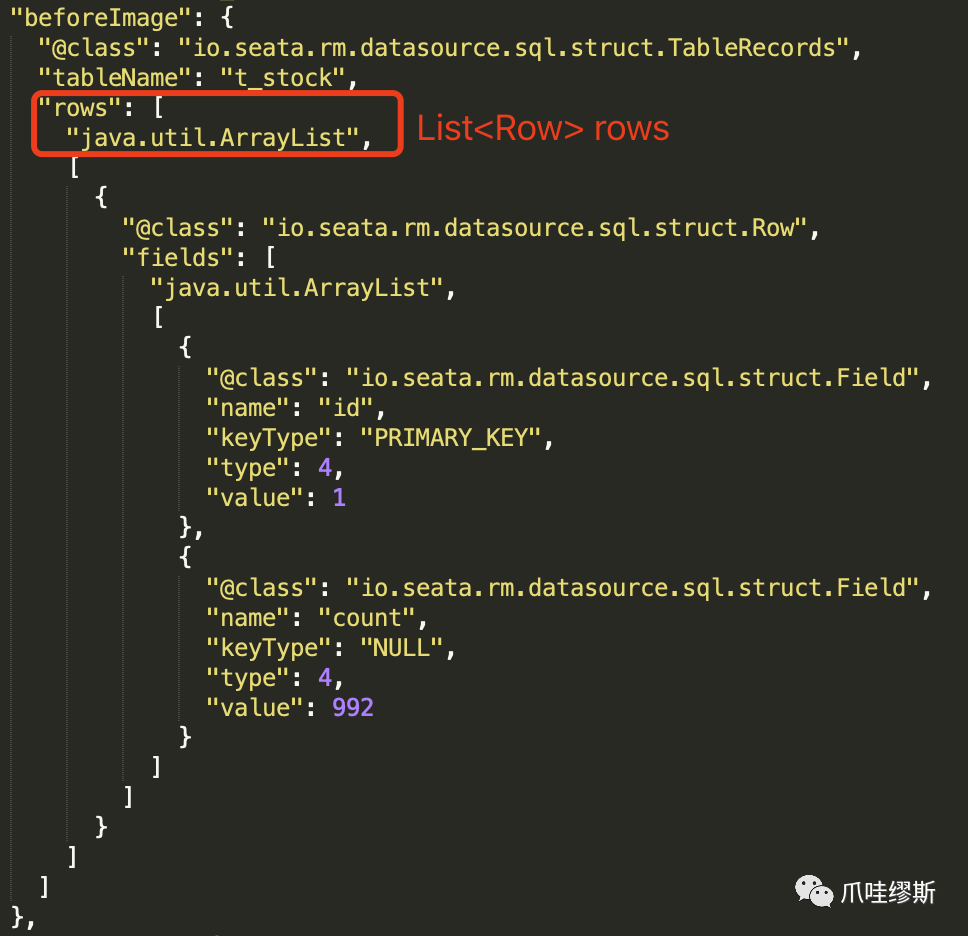
- 我们从上面json内容中,也可以看到,无论是beforeImage还是afterImage,都包含了以下3层的结构:
- 一个表的信息:io.seata.rm.datasource.sql.struct.TableRecords
- 一行记录的信息:io.seata.rm.datasource.sql.struct.Row
- 一行记录中每个字段的信息:io.seata.rm.datasource.sql.struct.Field
- 下面我们针对上面这3个类进行源码介绍。
4.2.1> TableRecords
- 我们来看一下Json中TableRecords的内容
- TableRecords源码如下所示:
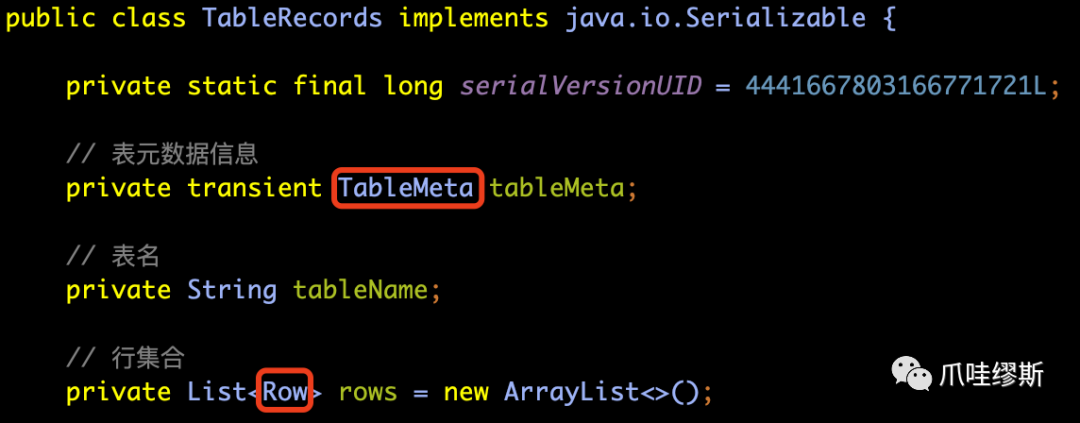
【解释】在上面这3个参数中,tableMeta表元数据是最重要的,在AT模式的很多处理环节中都要用到它。
a> TableMeta
a-1> TableMeta结构
- TableMeta源码如下所示:
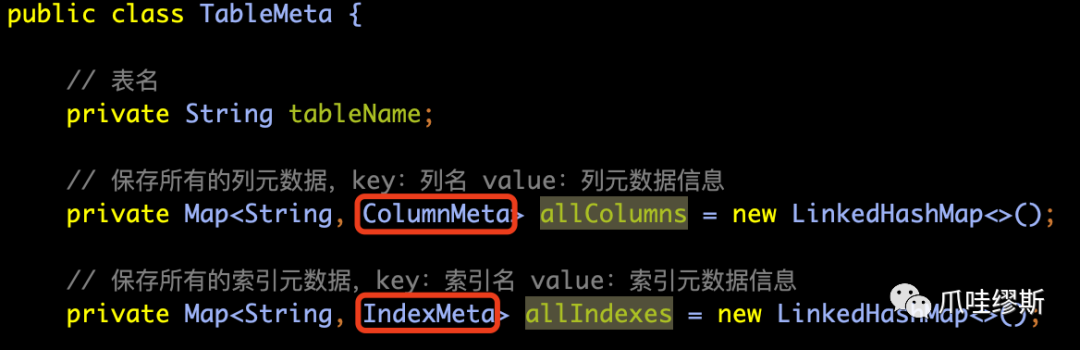
【解释】
- 列元数据(ColumnMeta)包含了很多的列信息,例如:列名、列数据类型、列是否允许为空、列是否为自增字段等。
- 索引元数据(IndexMeta)包括:索引名称、索引类型、索引所包含的列等等。
a-2> 获取TableMeta
- 表元数据获取步骤如下所示:
- 1> 从缓存中获取TableMeta。
- 2> 从数据库执行查询并生成TableMeta。
a-3> 从缓存中获取TableMeta
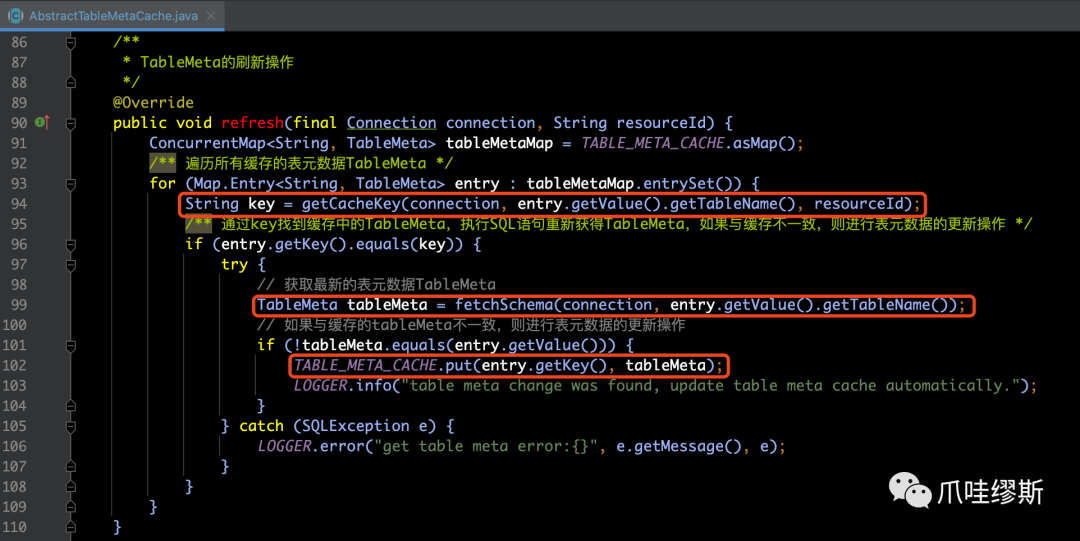
- AbstractTableMetaCache类的getTableMeta(...)方法用于实现表元数据的缓存操作,源码如下所示:
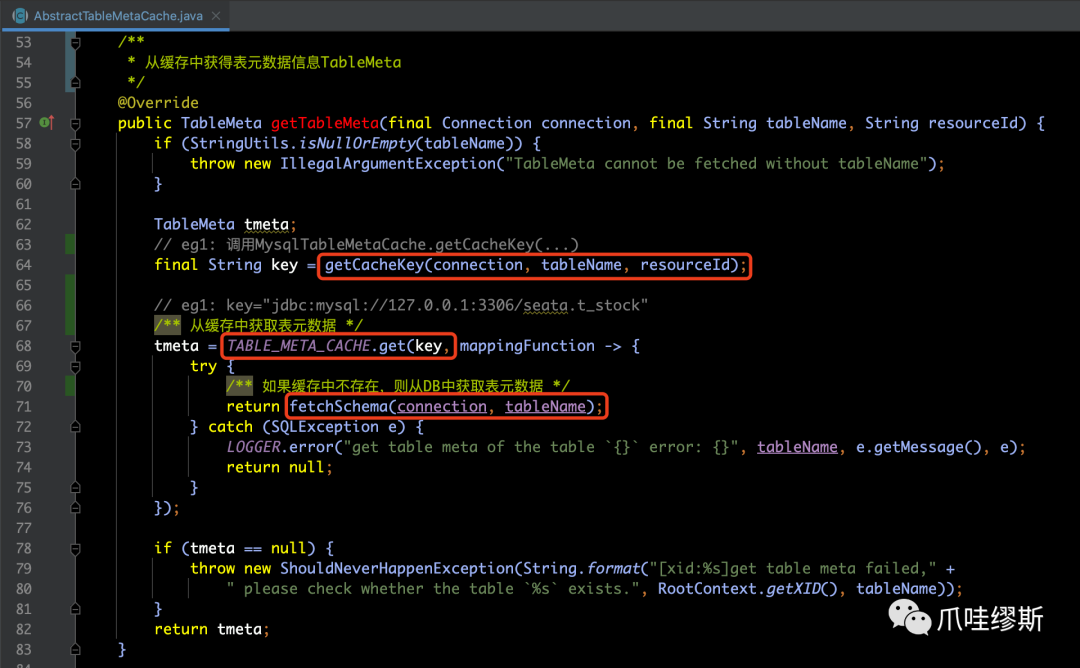
- 通过上图中第一个红框的getCacheKey方法获得缓存的key值,具体逻辑如下图源码所示:
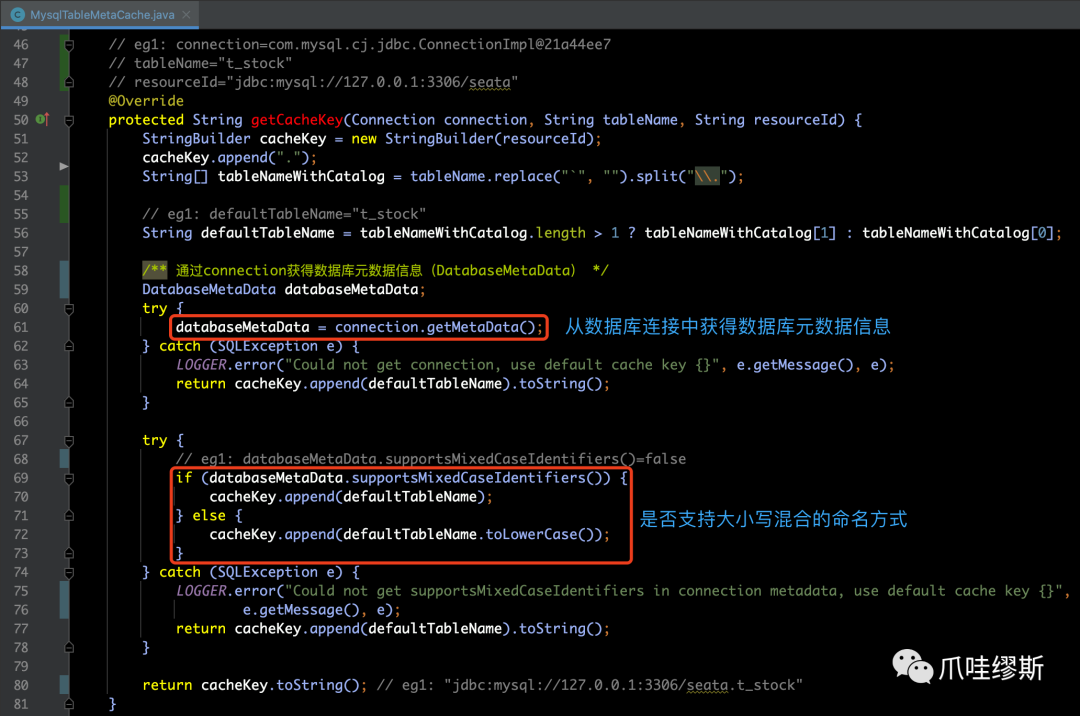
【解释】getCacheKey方法里面逻辑比较简单,主要就是拼装resourceId和特殊处理后的tableName
a-4> 从数据库执行查询并生成TableMeta
- 如果无法从缓存中获得表的元数据信息(TableMeta),则需要调用AbstractTableMetaCache的fetchSchema(...)方法从DB中获取,而该方法是抽象方法,具体由其子类实现,子类如下所示:

- 由于我们采用的是MySQL数据库,所以我们来看一下MysqlTableMetaCache的fetchSchema(...)方法,如下所示:
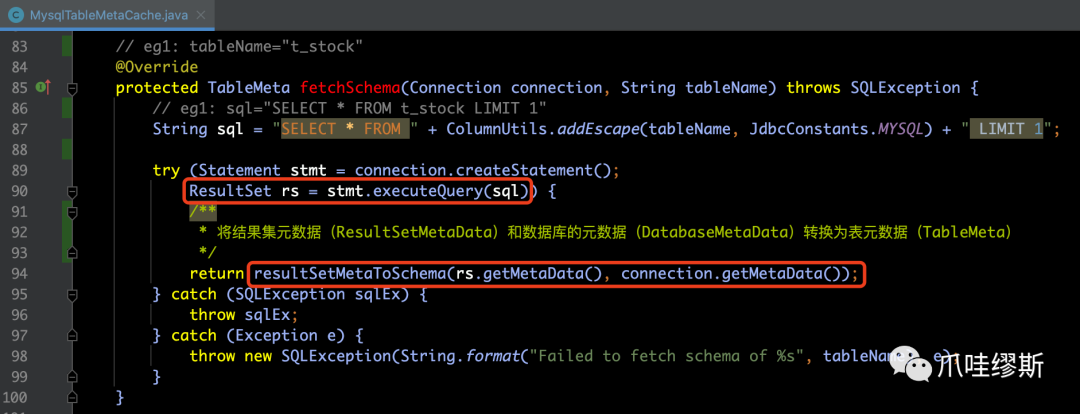
- 上图中第二个红框的resultSetMetaToSchema方法用于组装TableMeta,源码如下所示:
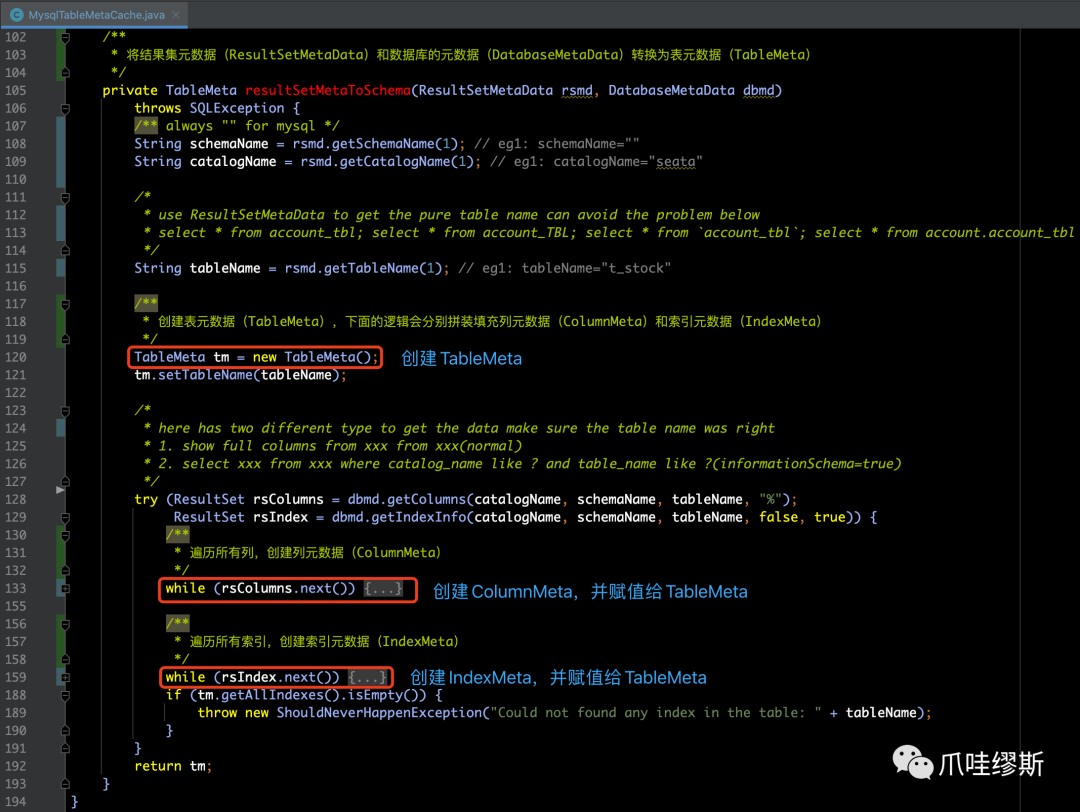
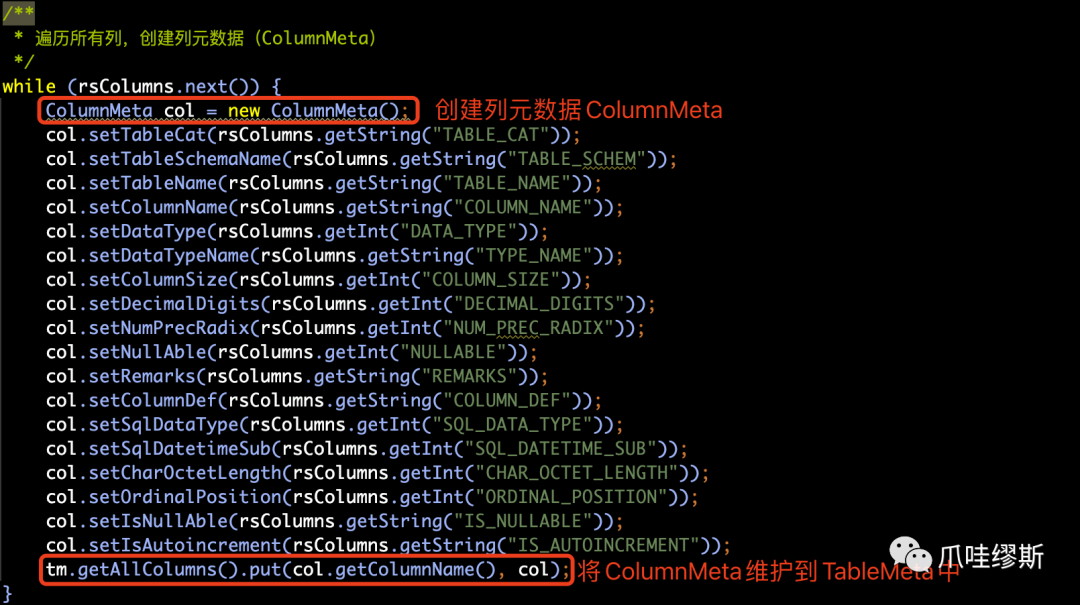
- 遍历所有列,创建列元数据(ColumnMeta)并维护到TableMeta的逻辑如下所示:
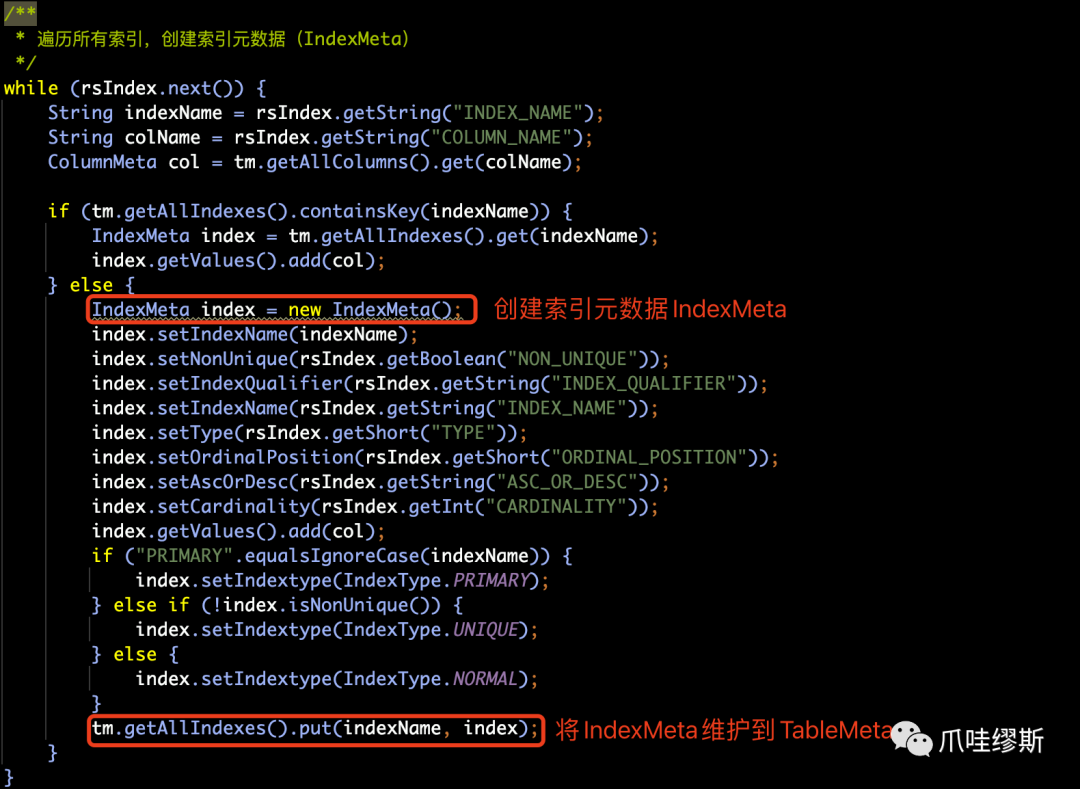
- 遍历所有列,创建索引元数据(IndexMeta)并维护到TableMeta的逻辑如下所示:
b> Row
b-1> Row结构
- 我们来看一下Json中Row的内容
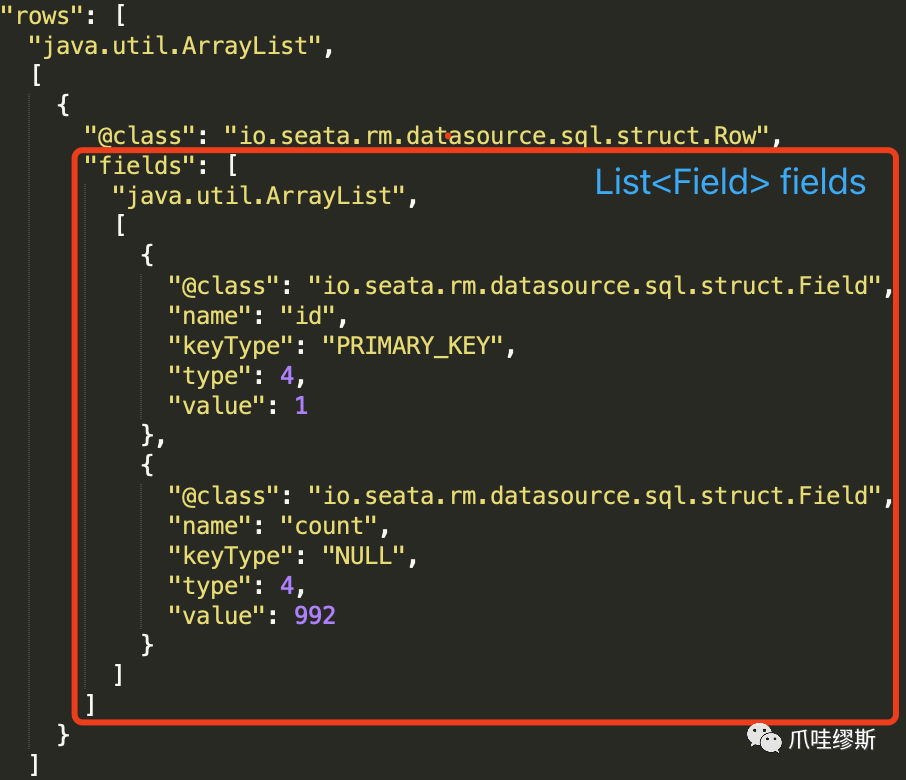
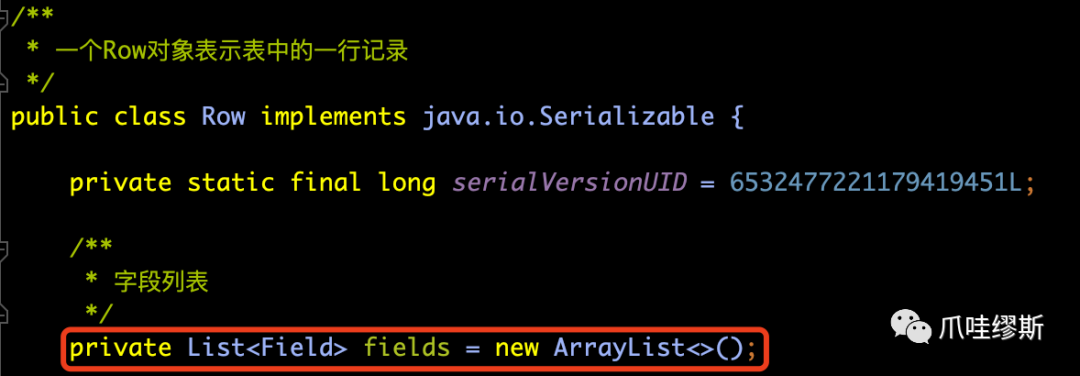
- 一个Row对象表示表中的一行记录,里面只包含字段列表List<Field>。Row源码如下所示:
b-2> Field
- 我们来看一下Json中Field的内容

- 一个Field对象表示一行记录的一个字段,源码如下所示:
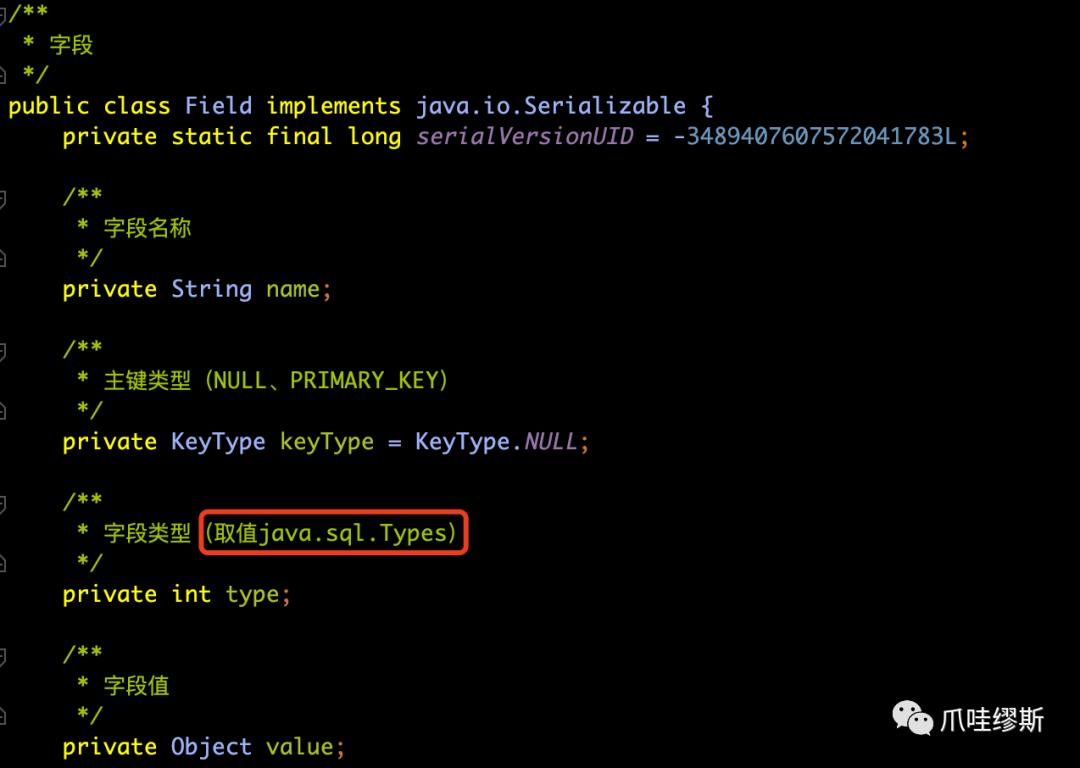
【解释】
- keyType字段的取值范围为:KeyType.NULL和KeyType.PRIMARY_KEY。
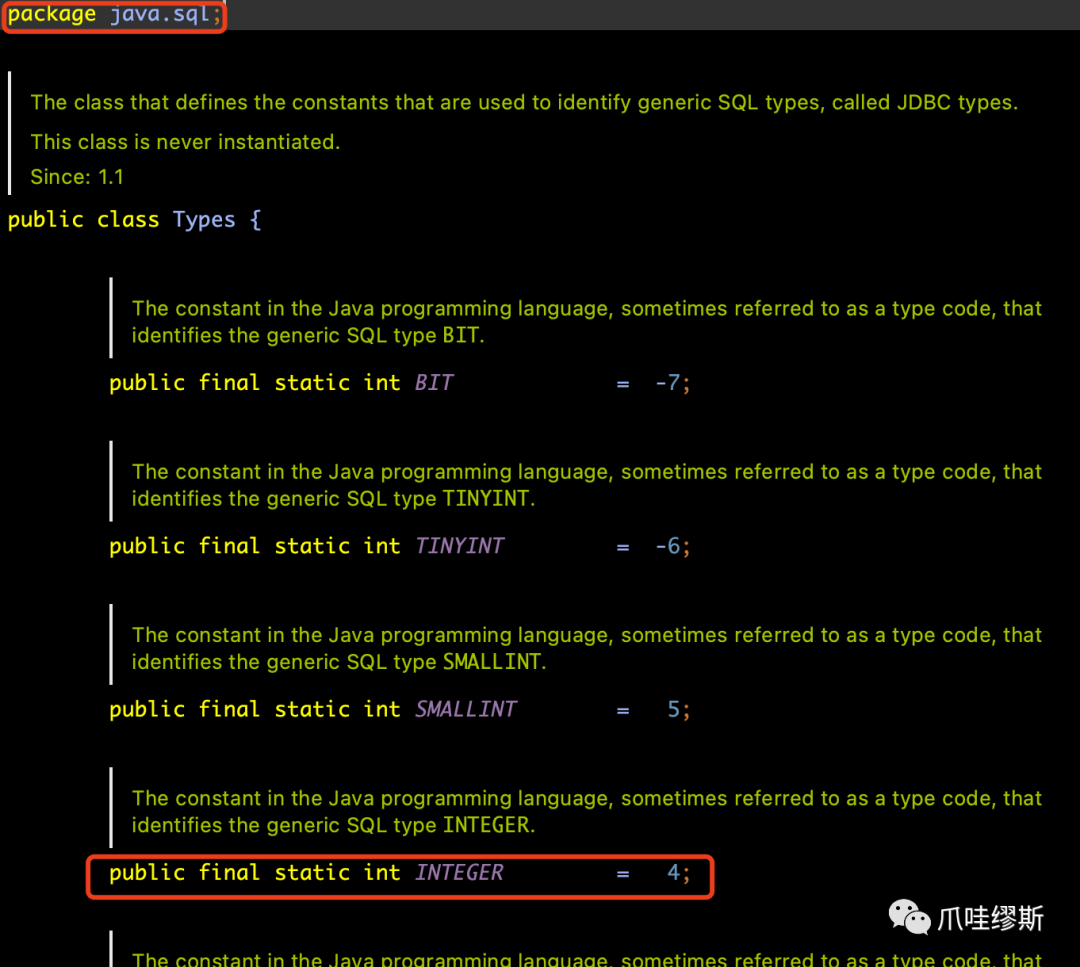
- type字段的取值范围为:java.sql.Types类中所定义的数据库字段类型。
4.2.2> 总结
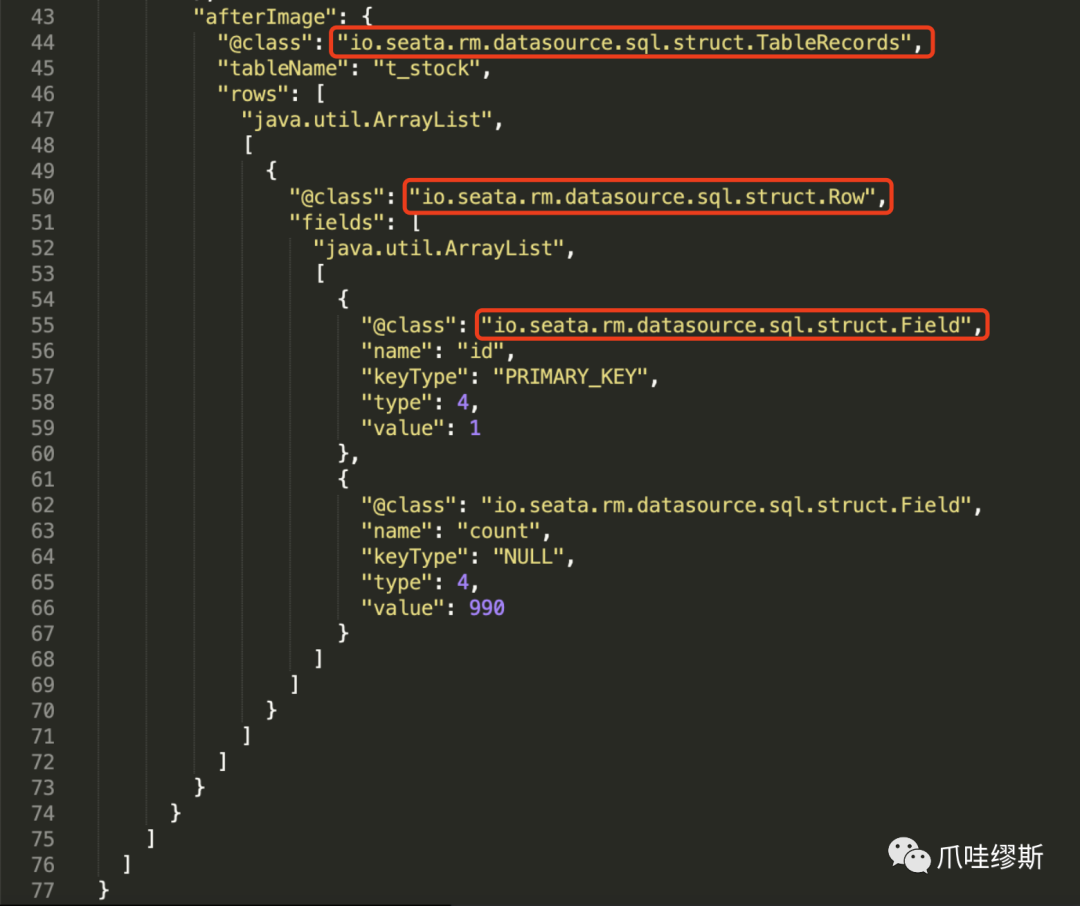
- 通过上面详细介绍的undoLog表中rollback_info列中的TableRecords结构内容,我们再看一下事务日志的前镜像内容表达的含义:
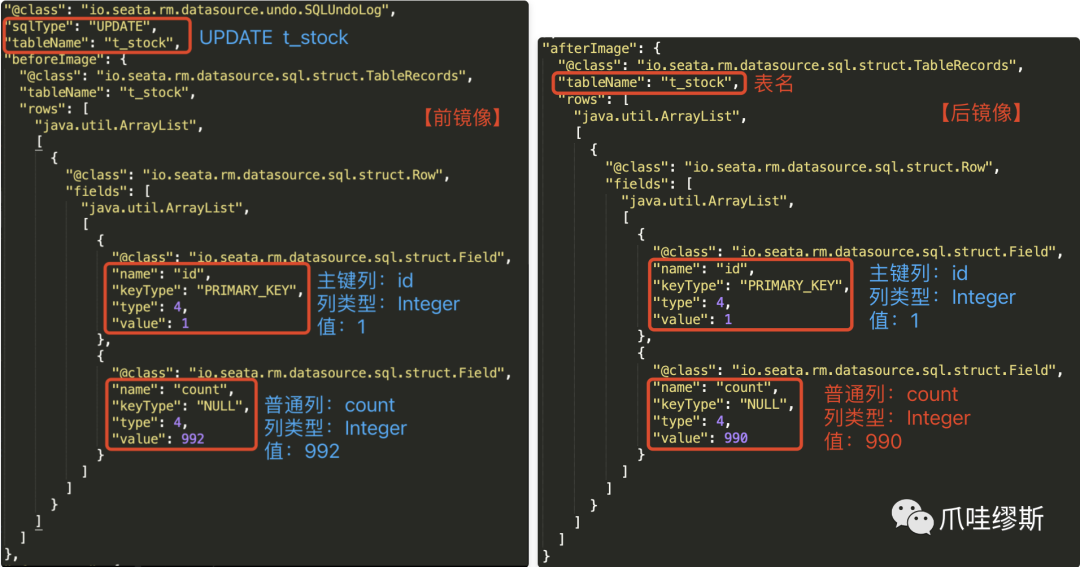
【解释】
- 事务日志记录的内容,是针对update操作语句
- 【前镜像】是针对表t_stock,主键id=1,count=992
- 【后镜像】是针对表t_stock,主键id=1,count=990
- 执行语句:update t_stock set count=990 where id = 1;
- 如果发生回滚,则可以从后镜像中得到业务SQL语句当时插入行的详细数据,判断当时的数据是否与当前数据一致。如果一致,则可以安全地完成该业务SQL语句的回滚。事务日志的相关处理逻辑,通过事务日志管理器UndoLogManager接口完成。下面我们来详细介绍一下这部分内容:
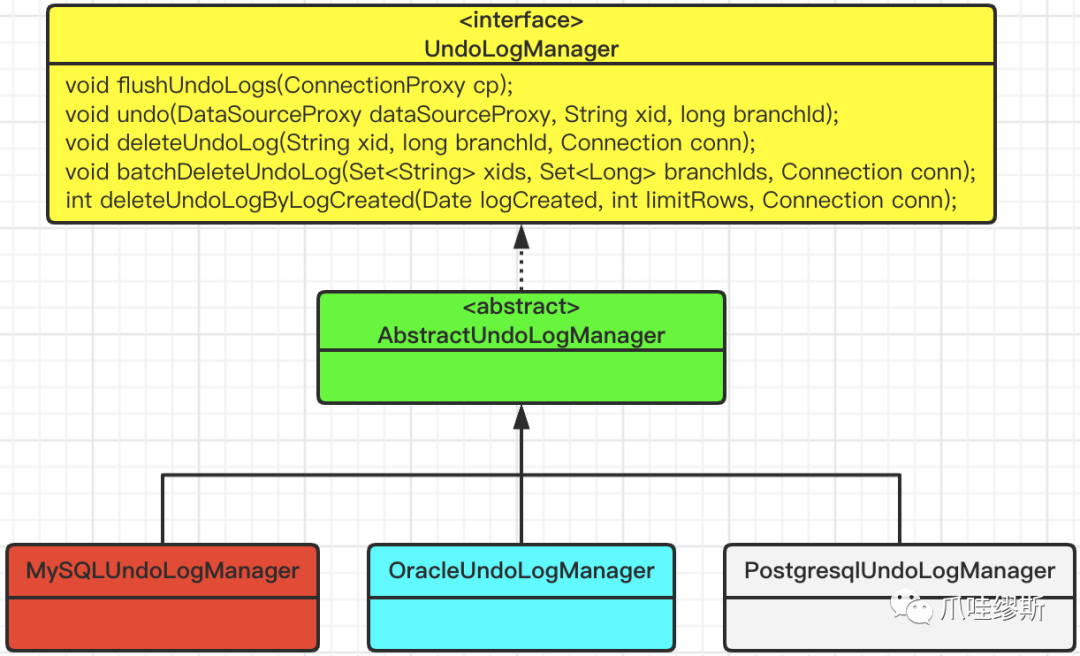
4.3> 事务日志管理器UndoLogManager
- 事务日志管理器定义了如下5个方法
- Seata实现了基于MySQL、Oracle和Postgresql这三个数据的事务日志管理器,该接口对应的实现类如下图所示:
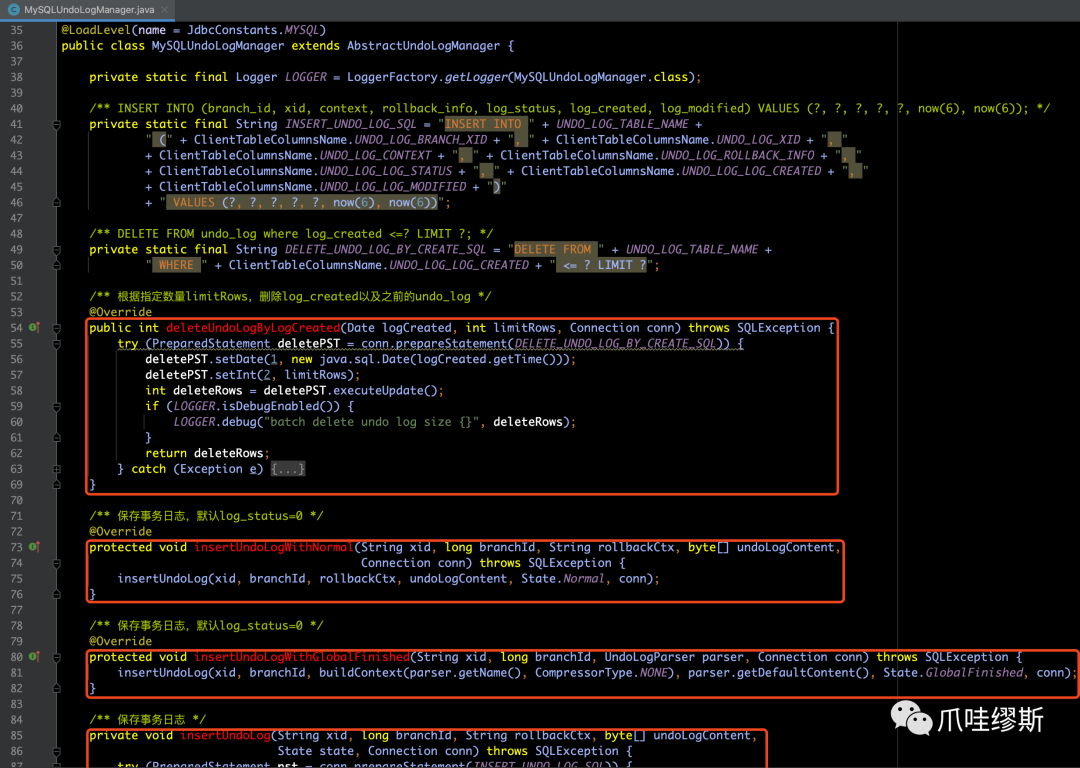
- 以MySQLUndoLogManager为例,如下所示:
4.4> Seata的数据源代理
- 数据源代理是AT模式的核心组件。
- 数据源代理的功能包括: 在SQL语句执行前后、事务commit或者rollback执行前后,进行一些与Seata分布式事务相关的操作。例如:分支事务注册、分支状态回报、全局锁查询、事务日志插入等等。
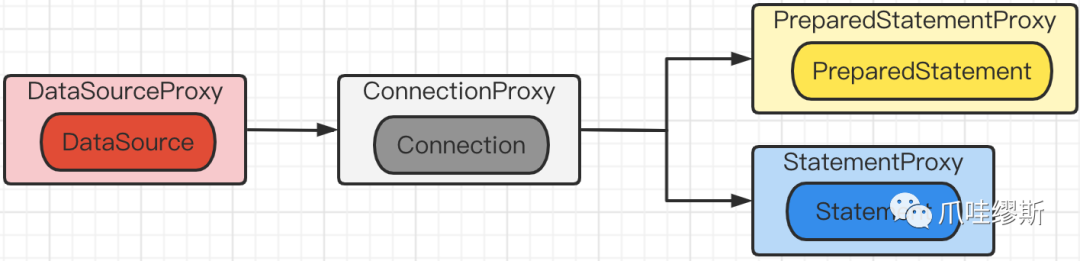
- Seata对java.sql库中的DataSource、Connection、Statement和PreparedStatement进行二次包装,生成了四个代理类(Proxy),如下所示:
4.4.1> DataSourceProxy
- 数据源代理类(DataSourceProxy)代理的数据源就是业务数据库。其类结构如下所示:
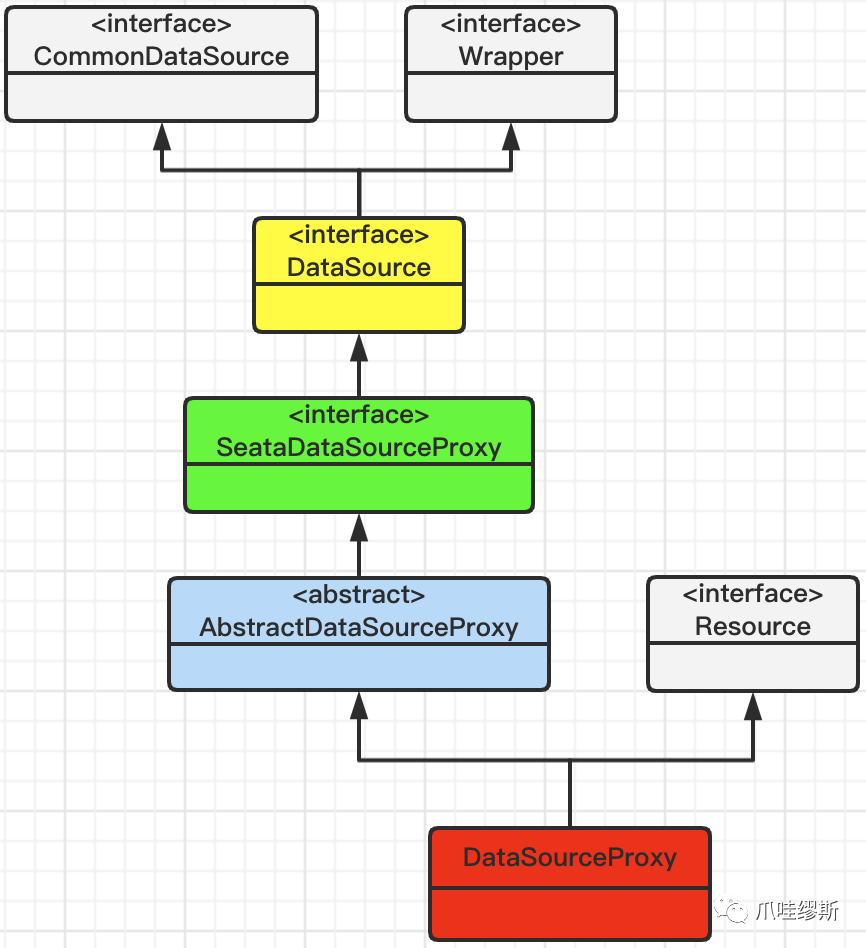
【解释】由于DataSourceProxy是DataSource接口的一个实现,这使得DataSourceProxy类可以分析要执行的SQL语句,以及生成对应的回滚SQL语句。
- AbstractDataSourceProxy类的源码如下所示:
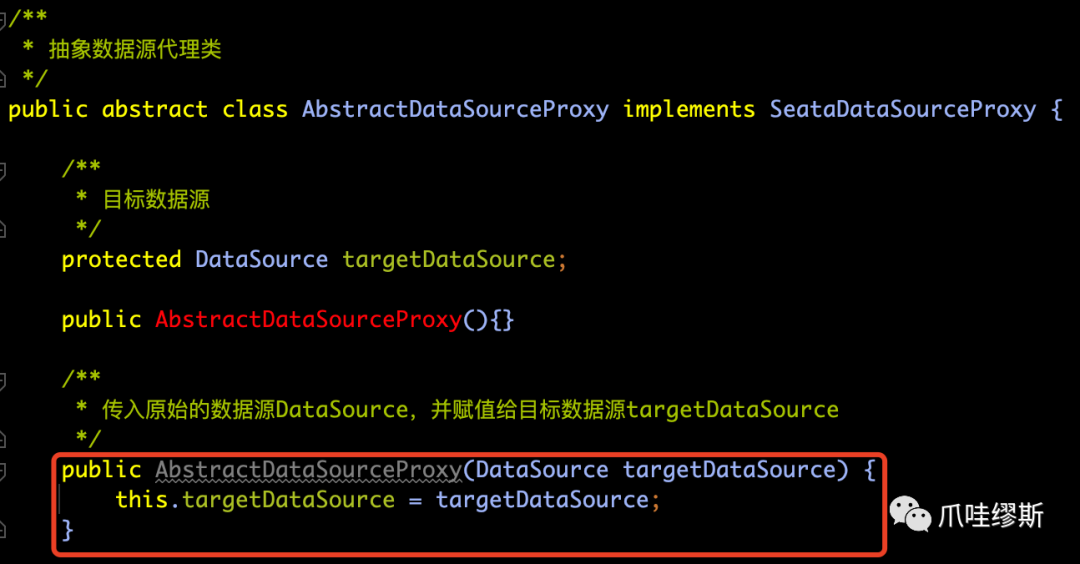
【解释】
- 可以看到AbstractDataSourceProxy提供了一个接收原始数据源DataSource的构造函数,并保存到targetDataSource中。其他方法直接调用原始数据源的相应方法。如下所示:
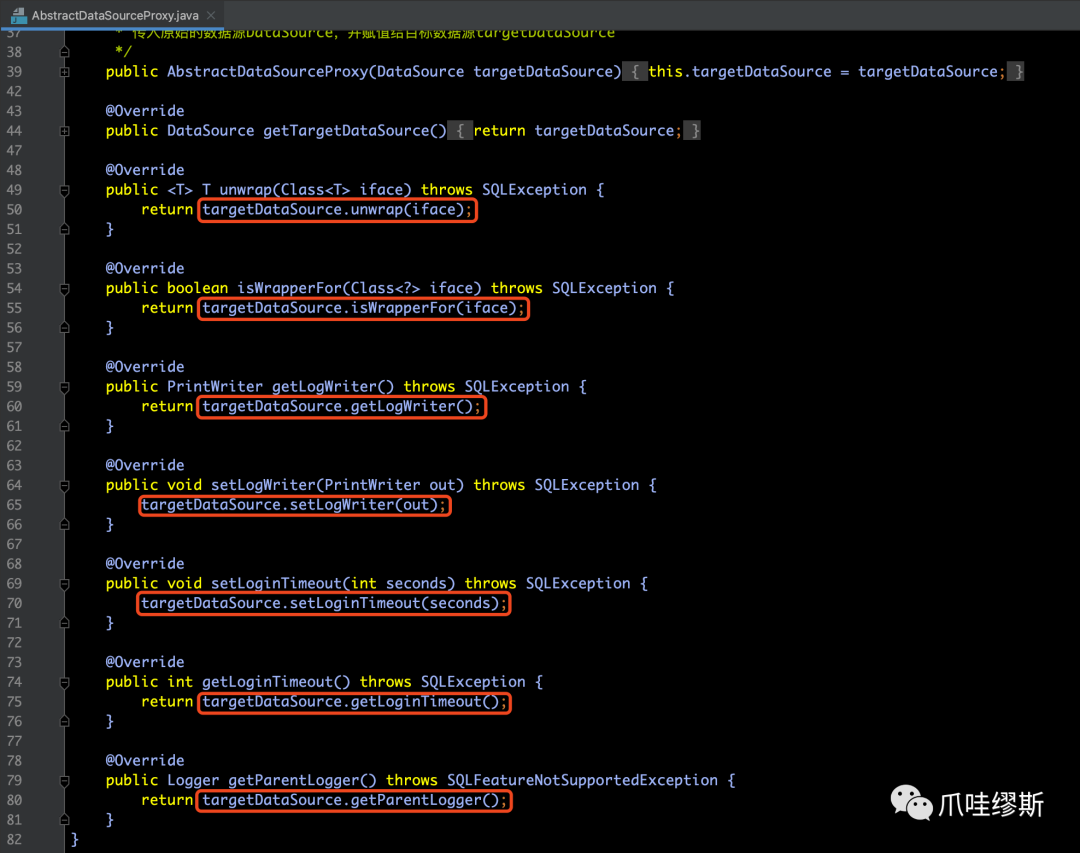
- AbstractDataSourceProxy类并未实现分布式事务的具体内容,而是由DataSourceProxy类的构造方法实现的,源码如下所示:
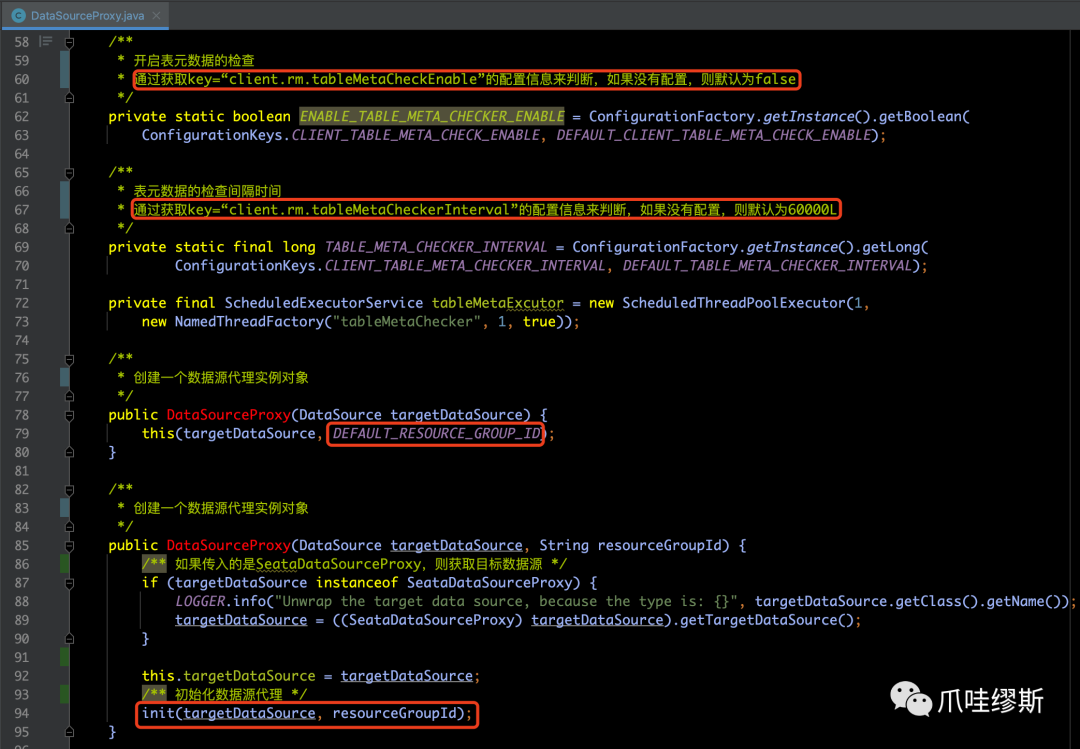
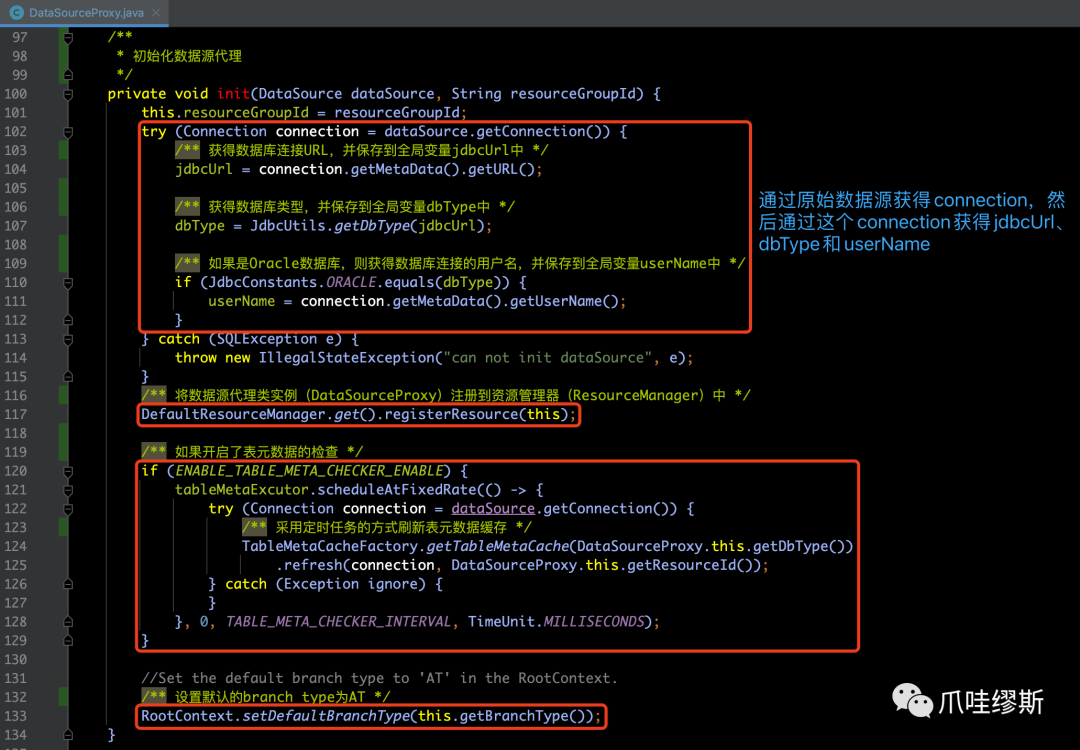
【解释】
- 在上方代码中,DataSourceProxy的构造函数将原始数据源保存为targetDataSource,然后调用init()方法执行初始化操作。
- 在init()方法中,先用原始数据源创建一个连接;然后通过这个连接获得URL地址、数据库类型、用户名称等信息。
- 最后把本数据源代理注册到资源管理器ResourceManager中。由于DataSourceProxy本身就是一个资源,可以由ResourceManager管理。
- 如果开启了表元数据检查(默认不开启),则默认每1分钟执行一次刷新操作。
- 由于ResourceManager是Seata的一个重要组件,所以下面内容我们来分析资源管理器的源码内容。
4.4.2> ResourceManager资源管理器
- 资源管理器ResourceManager相关接口如下图所示:
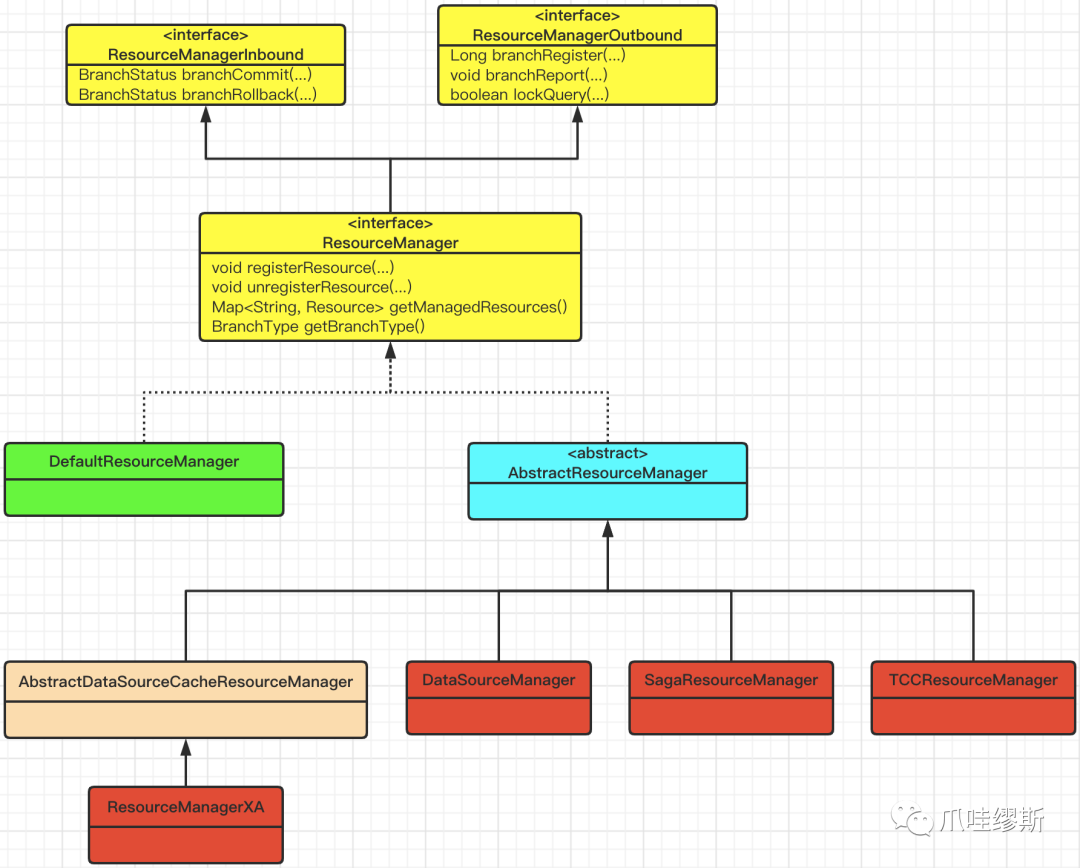
【解释】
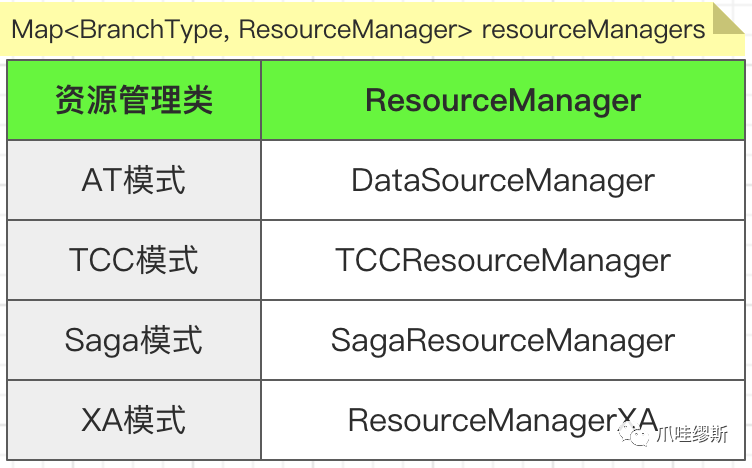
- AT模式的资源管理类——DataSourceManager
- TCC模式的资源管理类——TCCResourceManager
- Saga模式的资源管理类——SagaResourceManager
- XA模式的资源管理类——ResourceManagerXA
- 我们通过上图中源码可以发现,ResourceManager继承了ResourceManagerInbound和ResourceManagerOutbound这两个接口。这两个接口分别提供了“对内”和“对外”的两类操作。而所谓的“对内”和“对外”的视角出发点,就是资源管理器(RM)。
- ResourceManagerInbound接口定义如下:
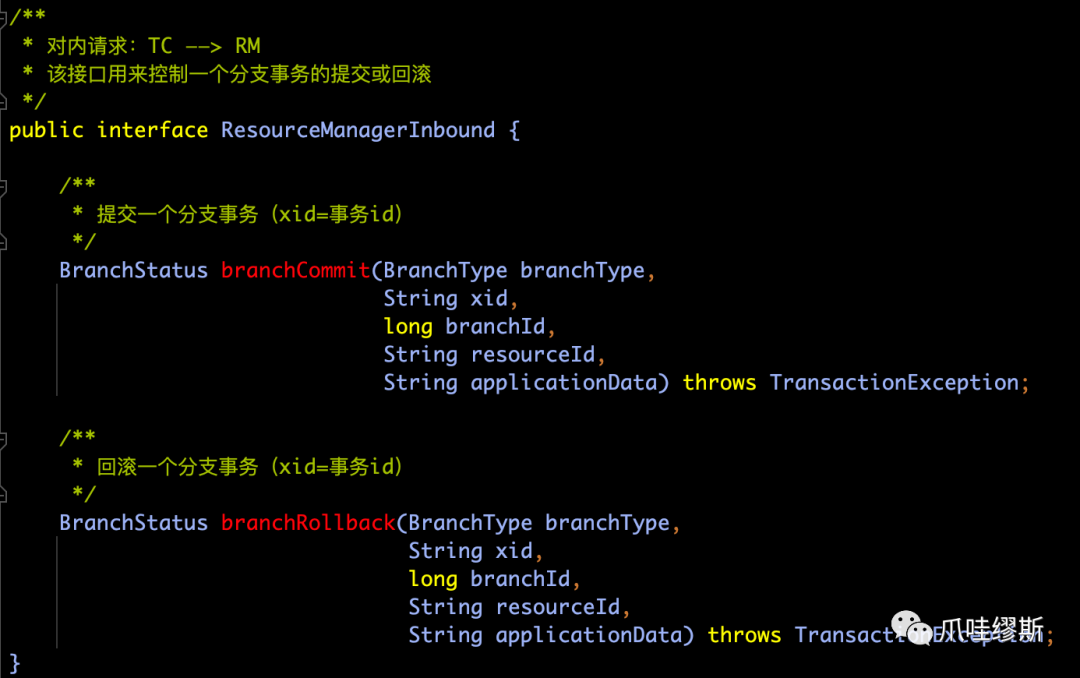
【解释】该接口用来接收TC发送来的请求,其中包含了:二阶段的分支事务提交请求、二阶段的分支事务回滚请求。
- ResourceManagerOutbound接口定义如下:
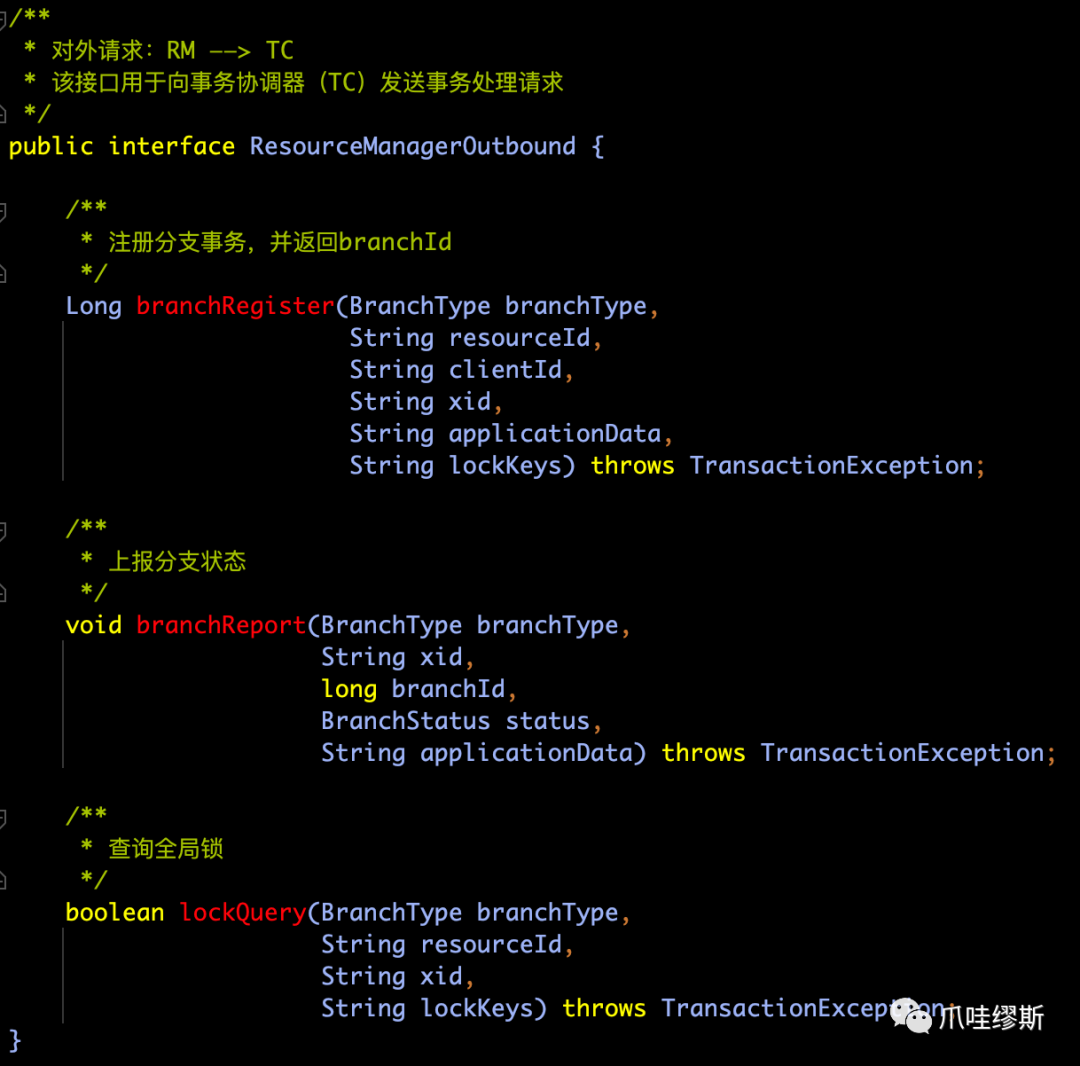
【解释】接口用于RM主动发送到TC的事务处理请求,例如:分支事务注册、事务状态上报、查询全局锁。
- ResourceManager提供了对资源的注册、取消注册、获取所有资源等方法,其接口定义如下:

- 下面我们回顾一下,当我们介绍DataSourceProxy的时候,将数据源代理注册到RM是通过调用DefaultResourceManager.get().registerResource(this)方法来实现的,如下所示:
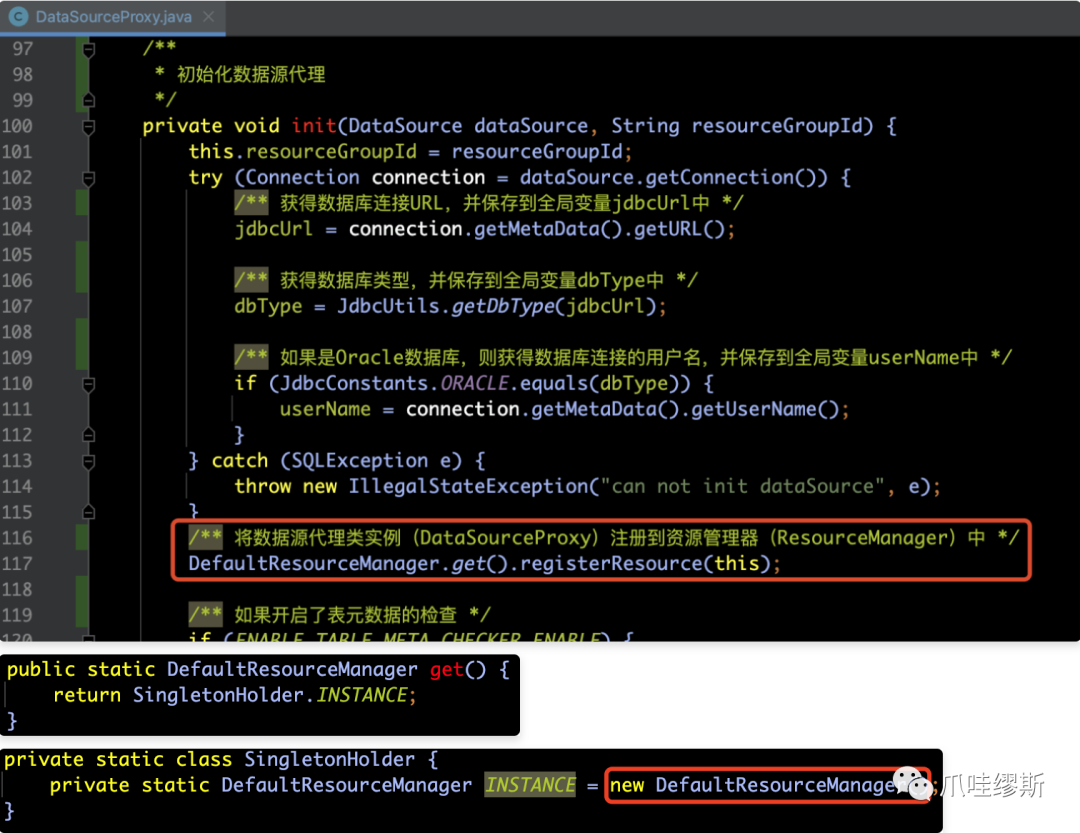
- 那么我们就针对DefaultResourceManager方法是如何实现registerResource(Resource resource)方法,在这个方法内,实际执行了3个部分内容,下图中已经用红框标注了,如下是具体的源码实现:
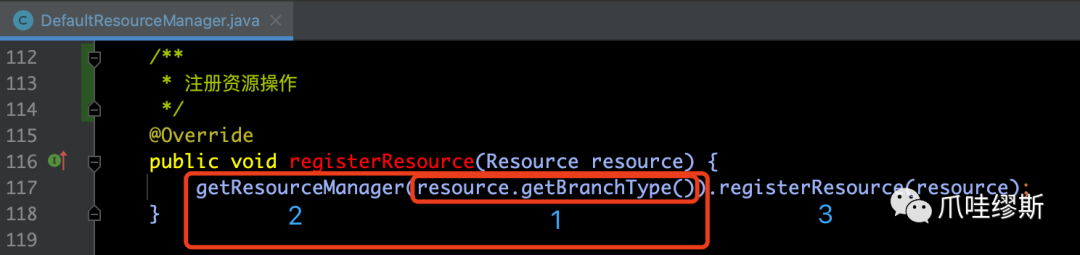
- 第一部分:获得分支类型BranchType
在方法resource.getBranchType()中,resource就是DataSourceProxy实例,它返回的分支类型是AT,如下图所示:
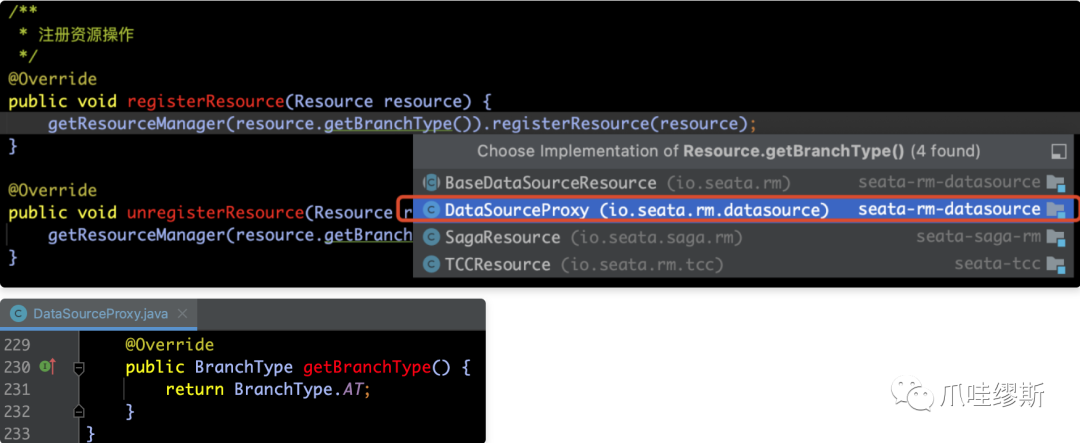
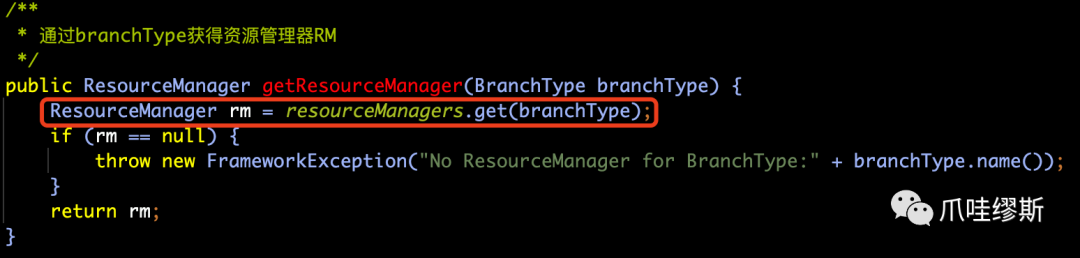
- 第二部分:通过分支类型BranchType获得相应的资源管理器ResourceManager
在getResourceManager(...)方法中,用于获取资源管理器ResourceManager对象,通过入参branchType=AT,我们可以获得AT的资源管理器为DataSourceManager。如下图所示:
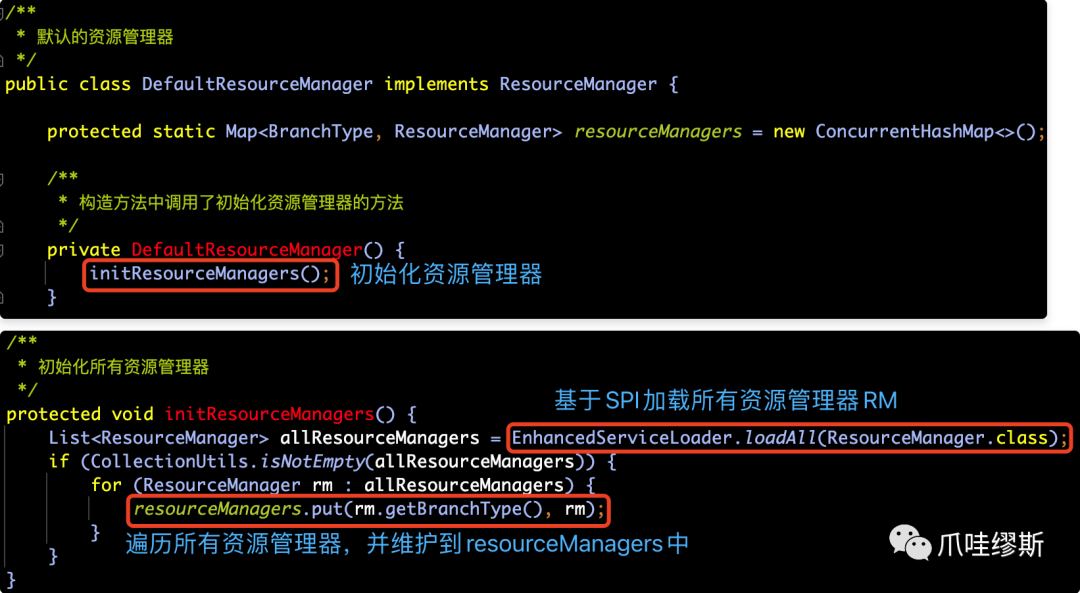
那resourceManagers是在哪个地方初始化的呢?我们来看一下ResourceManager的构造方法
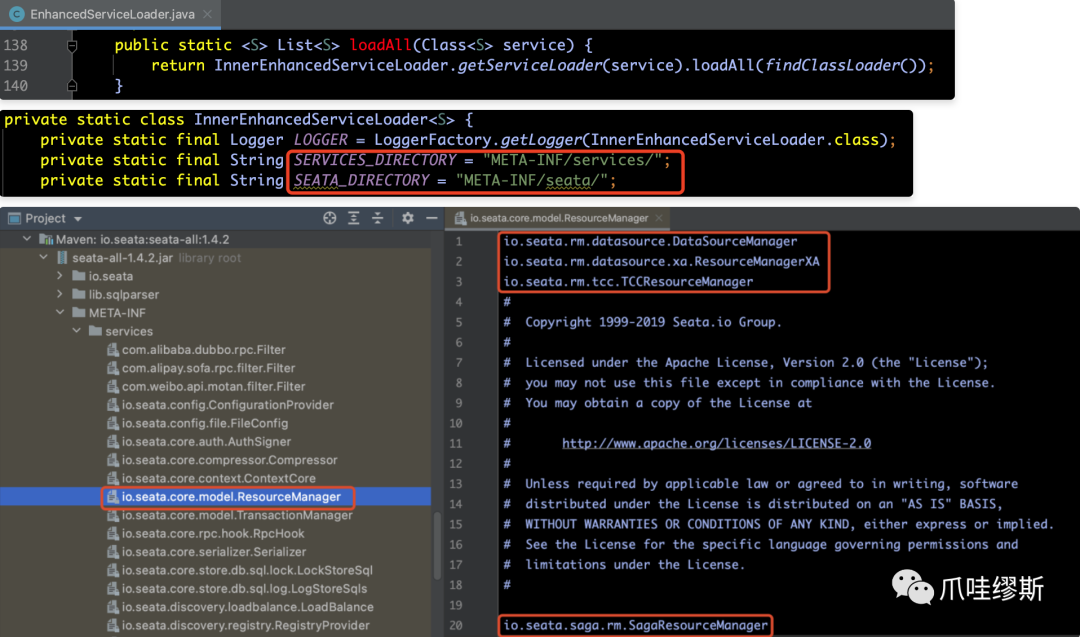
下面我们来看一下EnhancedServiceLoader.loadAll(...)方法,它通过SPI机制加载META-INF/services/io.seata.core.model.ResourceManager中配置的ResourceManager的具体实现类,如下所示:
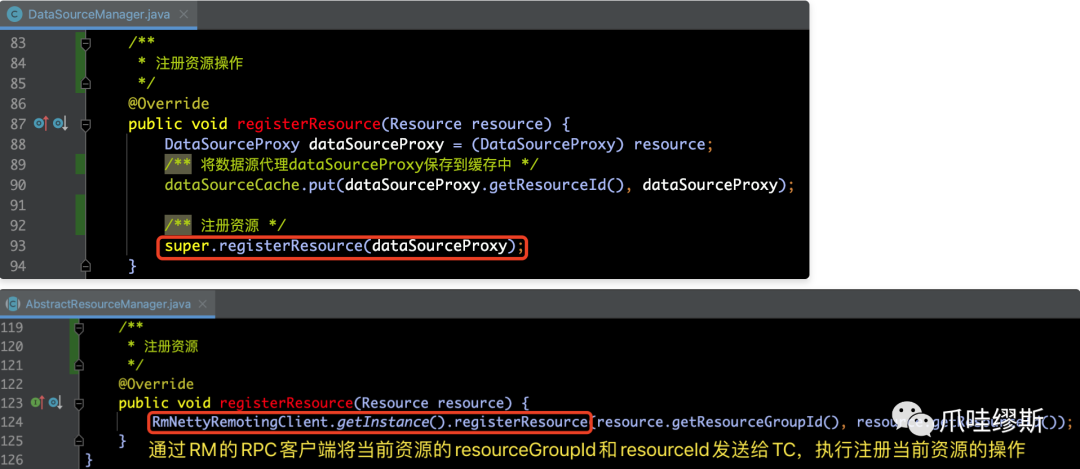
- 第三部分:注册资源Resource
方法DataSourceManager.registerResource(Resource resource)用于注册资源,当TC收到资源注册请求后,会把客户端连接与resourceGroupId和resourceId在内存中建立对应关系。在推进二阶段提交或二阶段回滚操作时,可以根据resourceGroupId和resourceId找到相应的客户端连接并发送请求。这种机制保证了二阶段操作的高可用性。其源码如下所示:
4.4.3> ConnectionProxy
- 上面介绍了数据源代理DataSourceProxy,那么还需要通过它的getConnection()方法来创建数据库的连接代理ConnectionProxy,如下所示:
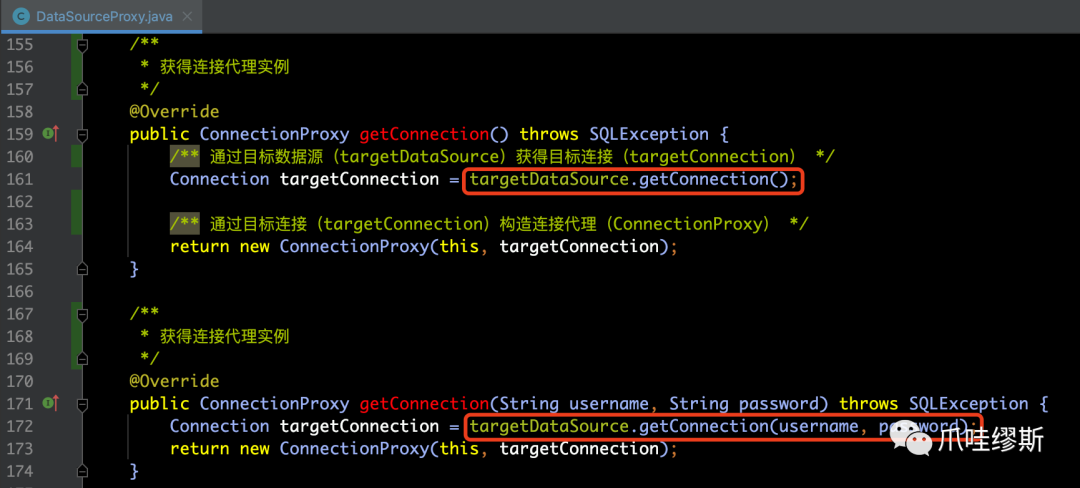
- 当我们构造好连接代理ConnectionProxy之后,那么业务代码拿到的数据库连接就是ConnectionProxy实例,所以在执行本地事务提交的时候,实际执行的是ConnectionProxy类的commit()方法,源码如下所示:
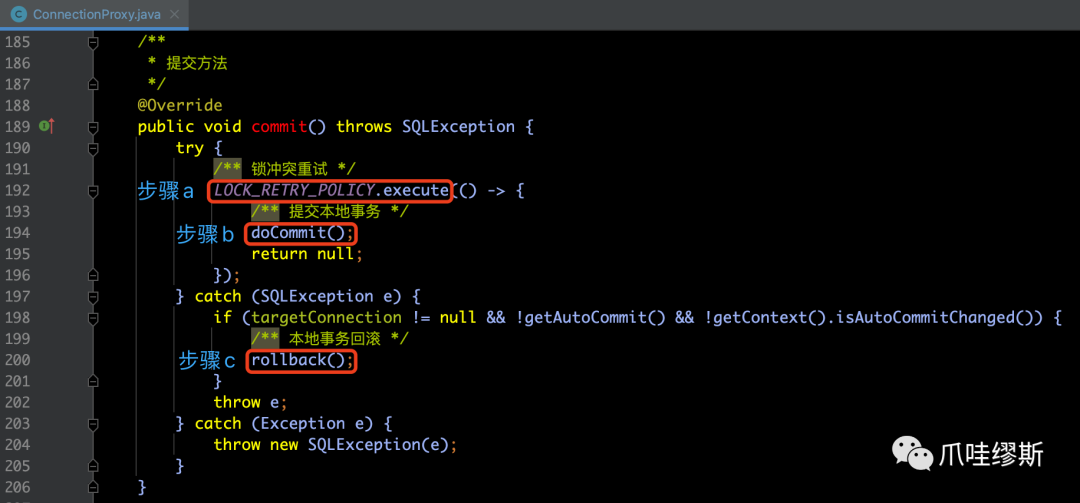
【解释】如上面截图中标注的步骤1和步骤2,进行详细的源码解析。
a> LOCK_RETRY_POLICY.execute()——锁冲突重试
- 在commit()方法中,通过LOCK_RETRY_POLICY.execute()方法增加了锁冲突重试机制(LOCK_RETRY_POLICY = new LockRetryPolicy())。其中,LockRetryPolicy是ConnectionProxy的内部类。那么,我们来看一下LockRetryPolicy的execute()方法执行了哪些内容:
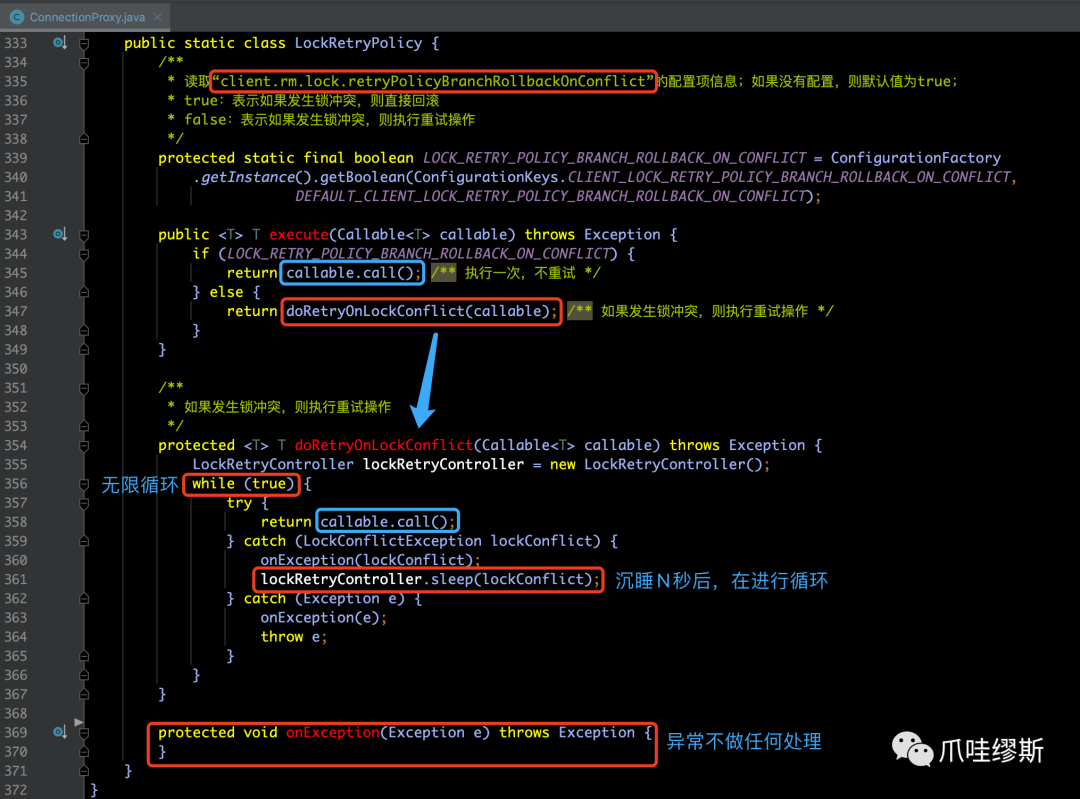
【解释】
- 如果配置client.rm.lock.retryPolicyBranchRollbackOnConflict=false,则会调用重试操作,即:doRetryOnLockConflict()方法,当发生锁冲突的时候,会抛LockConflictException异常,抓取异常后,会调用sleep方法执行睡眠,之后再循环调用callable.call();
- 如果没有配置client.rm.lock.retryPolicyBranchRollbackOnConflict,或者配置该属性为true,则只执行一次callable.call(),不执行重试操作。
- LockRetryController.sleep()方法源码如下所示:
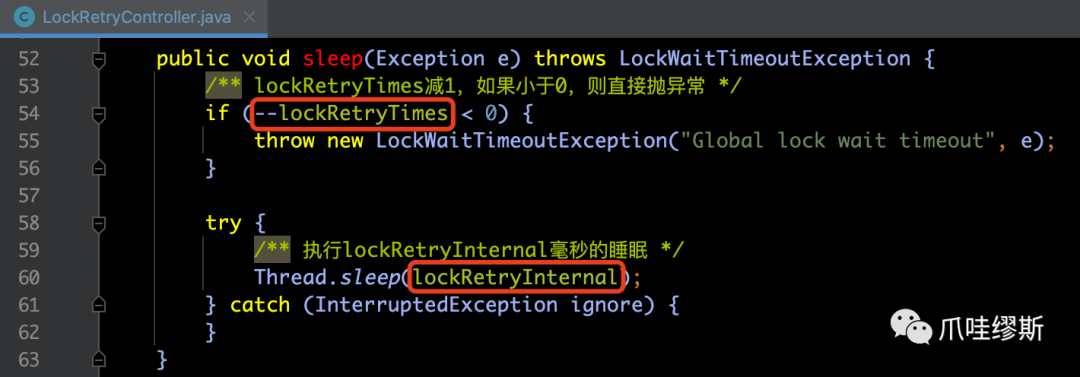
【解释】每次执行sleep方法,都会促使lockRetryTime减1,如果值小于0,则不执行sleep操作了,直接抛出异常。
- 其中,加锁重试次数(lockRetryTimes)和加锁重试间隔(lockRetryInternal)是通过在LockRetryController的构造函数中被初始化的,如下所示:
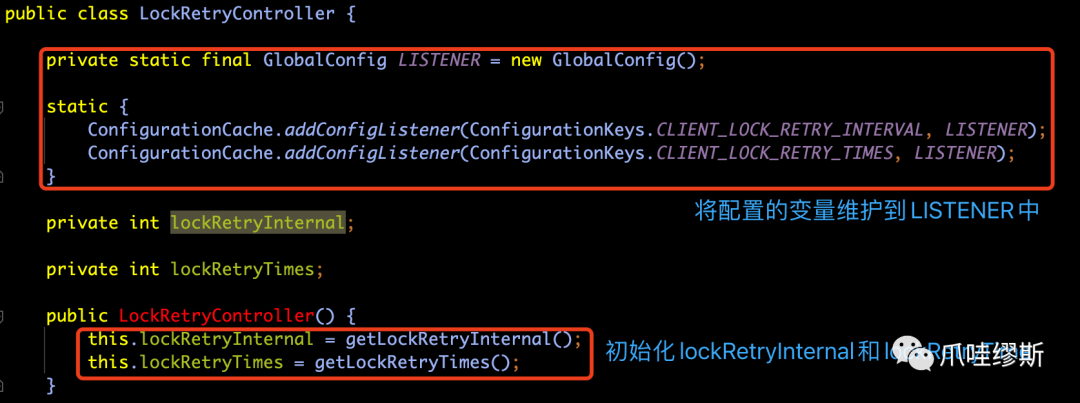
- 构造函数中调用的getLockRetryInternal()方法和getLockRetryTimes()方法实现方式类似,都是先获得定制参数,如果获得不到,则获取全局配置。
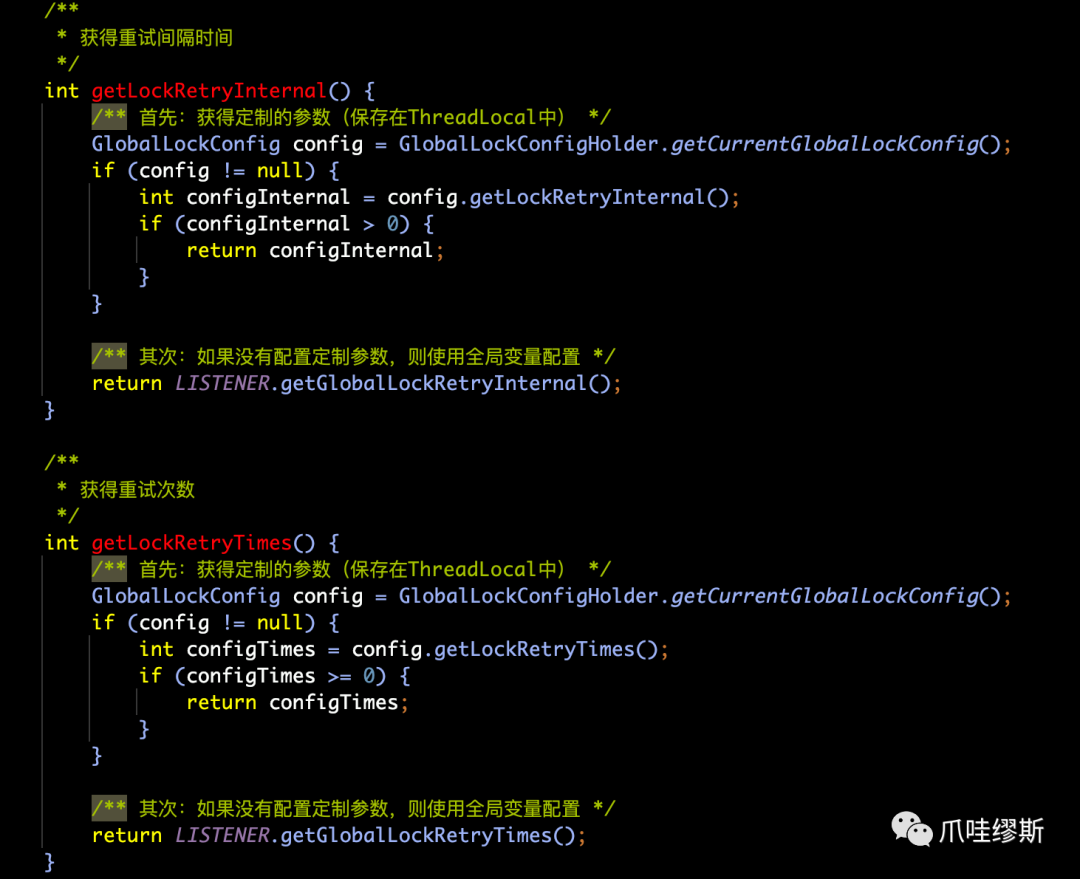
b> doCommit()——提交本地事务
- ConnectionProxy的doCommit()方法逻辑如下所示:
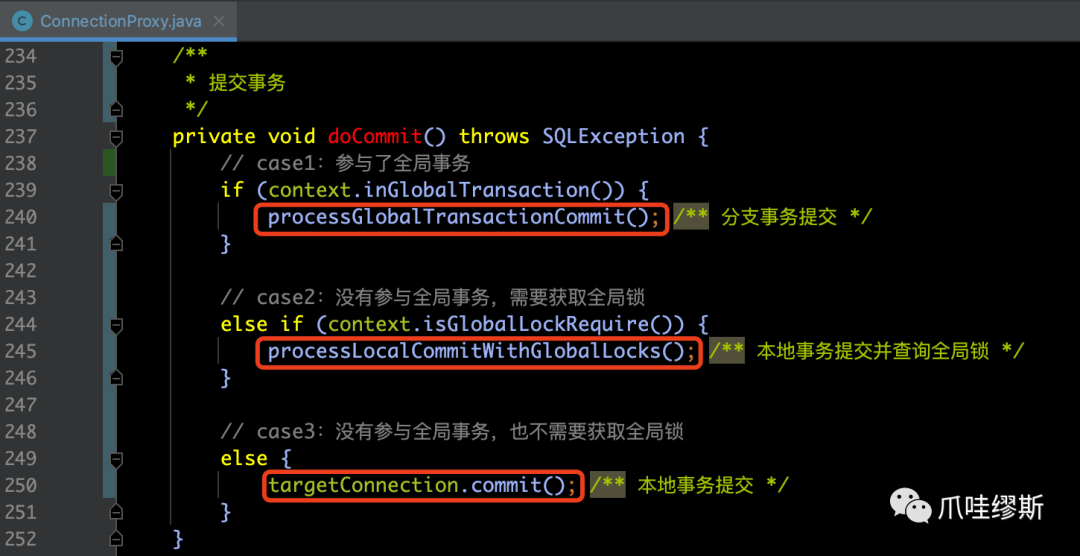
b-1> processGlobalTransactionCommit()
- 该方法是用于分支事务提交逻辑,源码如下所示:
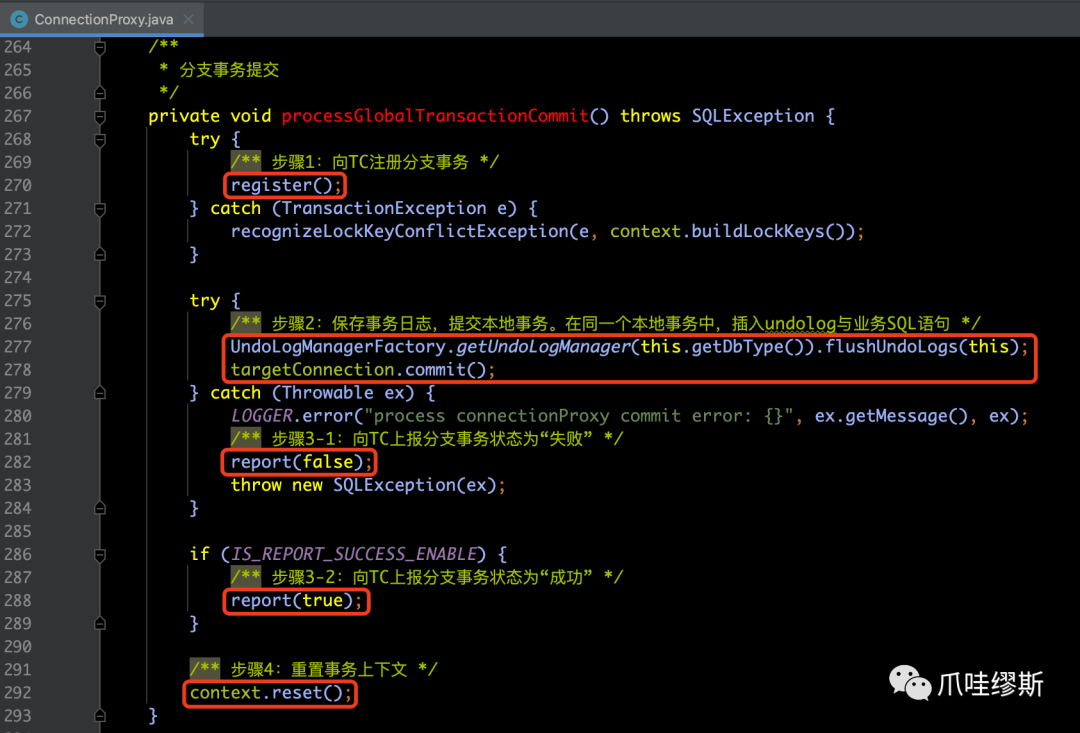
【解释】processGlobalTransactionCommit()方法中包含3个重要的步骤(我们随后会分别解析一下),分别为:
- 1> register() 向TC注册分支事务
- 2> flushUndoLogs(...) 保存事务日志
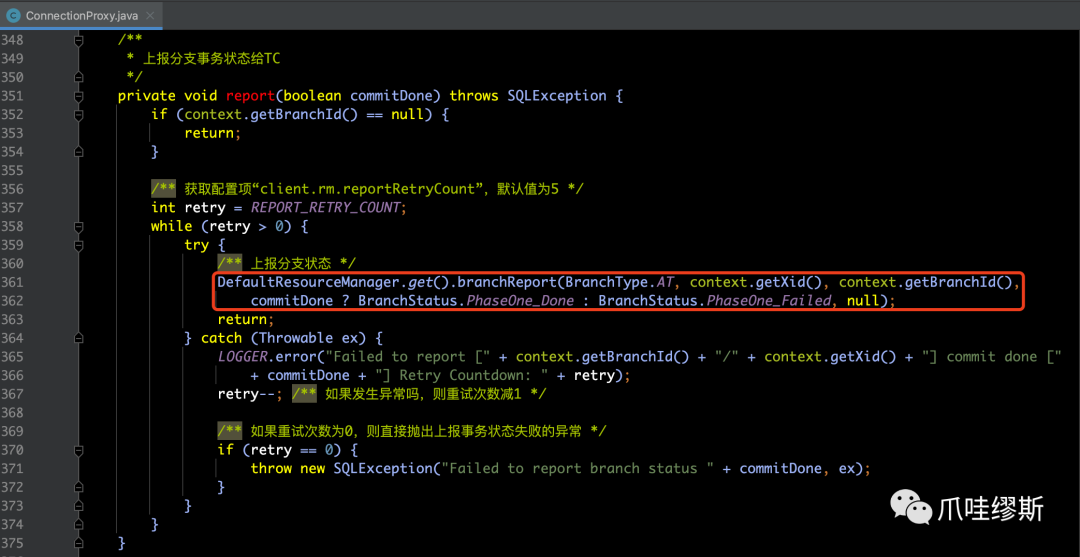
- 3> report(...) 向TC上报分支事务状态
Step1> register()
- register()方法用于向TC注册分支事务,源码如下所示:
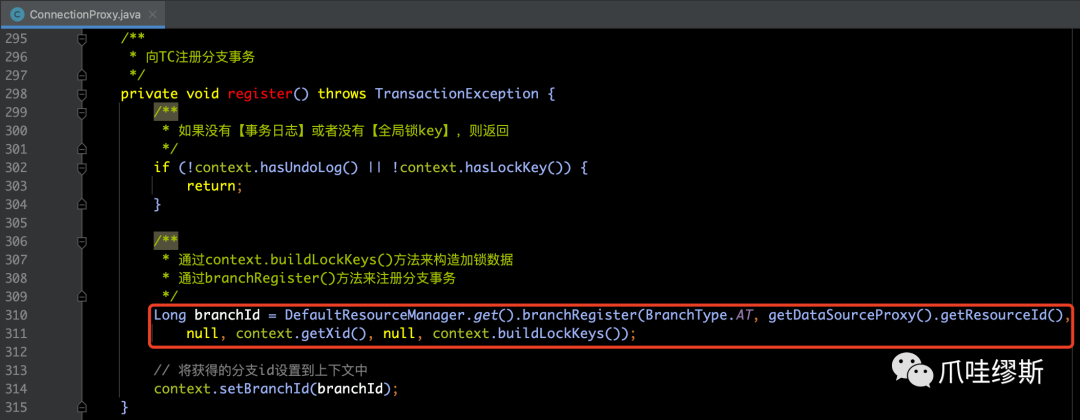
DefaultResourceManager的branchRegister(...)方法用于分支注册操作,源码如下所示:
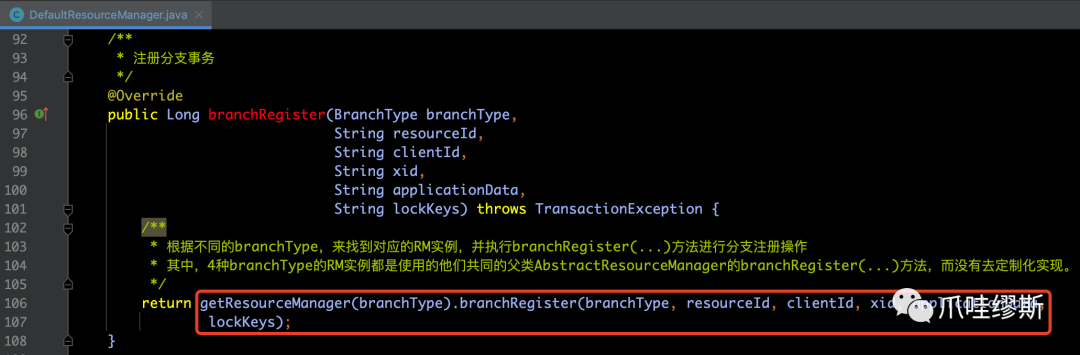
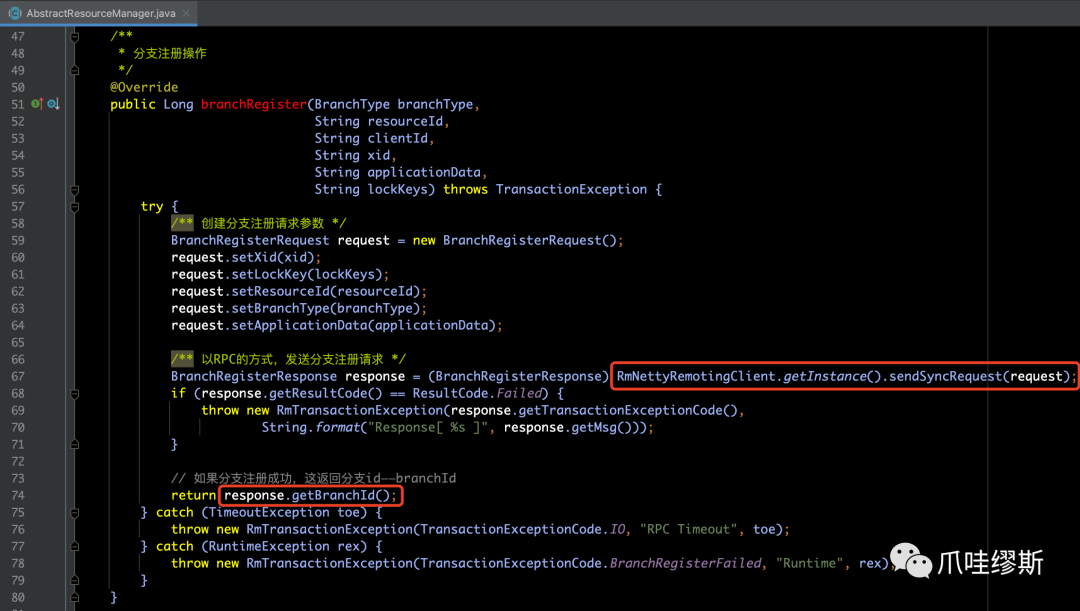
AbstractResourceManager的branchRegister(...)方法逻辑如下所示:
Step2> flushUndoLogs(...)
- flushUndoLogs(...) 用于保存事务日志,源码如下所示:
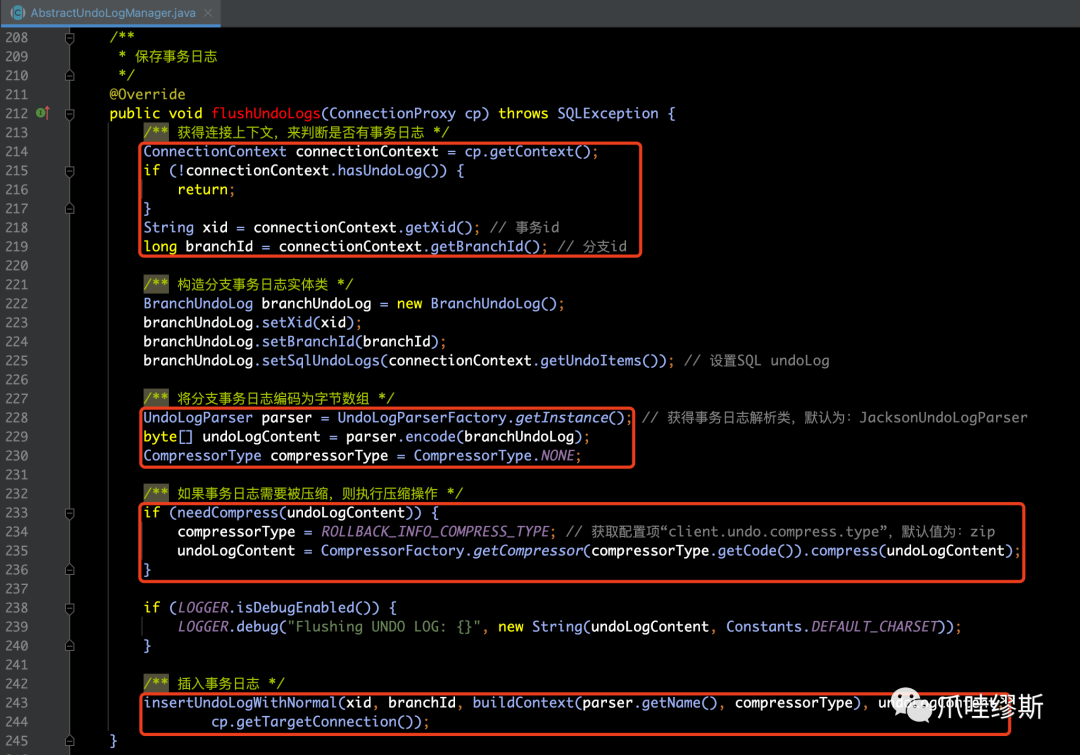
【解释】
- 首先,从上面截图中的源码中可以看到,xid、branchId和undoItems都是从连接上下文(connectionContext)中获取到的。
- 其次,会将日志内容转换为字节数组,采用什么方式转换,可以通过“client.undo.logSerialization”进行配置,默认是JacksonUndoLogParser。

- 第三,如果日志需要被压缩的话,则进行事务日志内容压缩操作,是否需要被压缩的逻辑在needCompress方法中,如下所示:

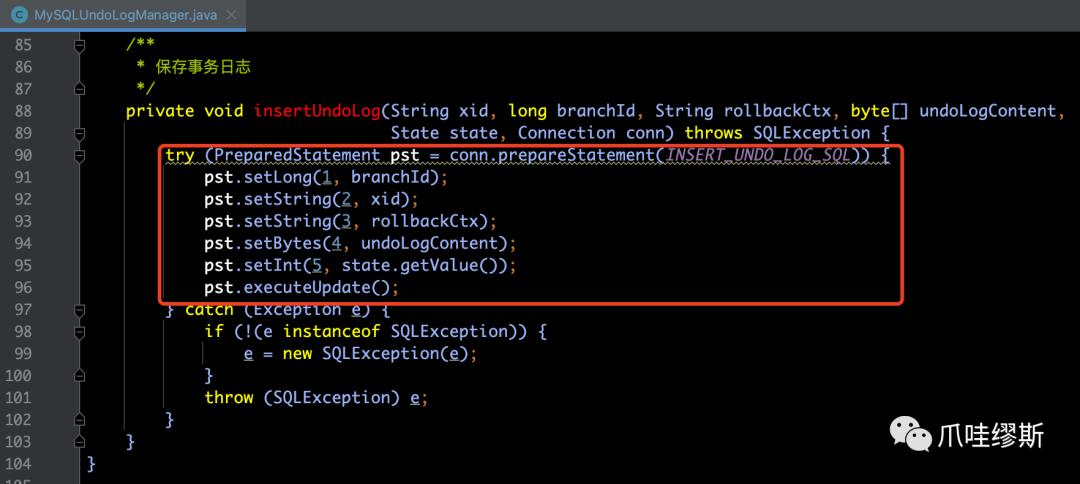
- 最后,调用insertUndoLogWithNormal()方法来插入事务日志,该方法是一个抽象方法,具体实现是由不同的数据库来决定的。


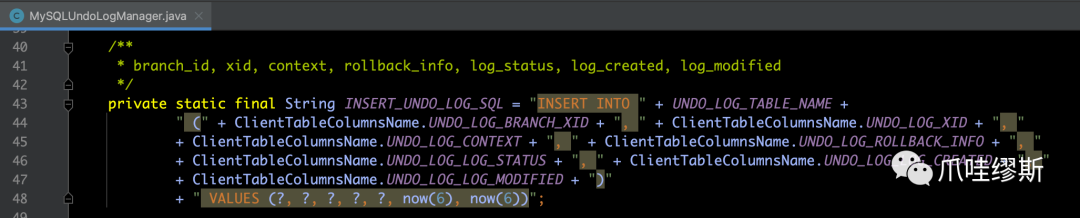
- 一般来说,我们常用的数据库时MySQL,所以我们来看一下MySQLUndoLogManager的insertUndoLogWithNormal()方法源码如下所示:

Step3> report(...)
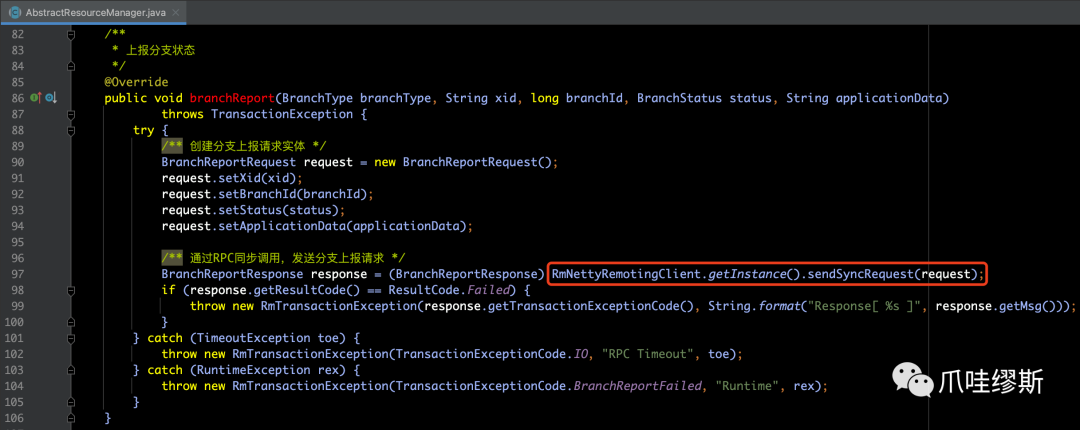
- report(...) 用于向TC上报分支事务状态,源码如下所示:

b-2> processLocalCommitWithGlobalLocks()
- 当需要查询全局锁的时候,就会执行这部分的代码。那么,什么时候去查询全局锁呢?我们知道,在AT模式中,在第一阶段加上Seata全局锁后,提交本地事务,然后释放数据库锁。这就造成了一个问题——在一个分布式事务完成后,数据修改已经入库了,但是它可能还处于一个未结束的分布式事务中,即:它修改的数据对分布式事务来说是中间数据,有可能还会回滚回去。这个时候,另一个分布式事务查询它刚修改的行,就会读到中间数据,即:发生了分布式事务的脏读。
- 但是,这种中间状态的情况并不会长时间持续,一般来说,很快就结束了。所以,如果在实际应用中,允许这种中间状态的产生,则可以不去查询全局锁了。因为毕竟查询全局锁是有一定的性能开销的。
- 下面是processLocalCommitWithGlobalLocks()方法的源码注释:
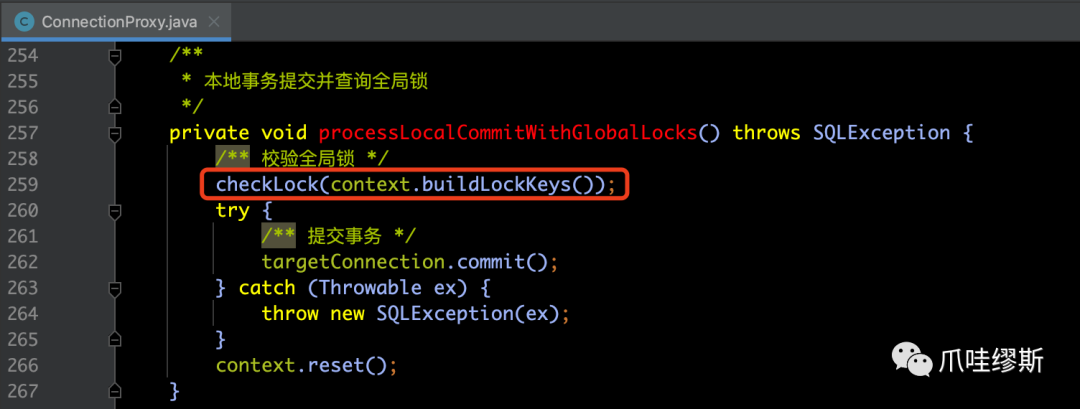
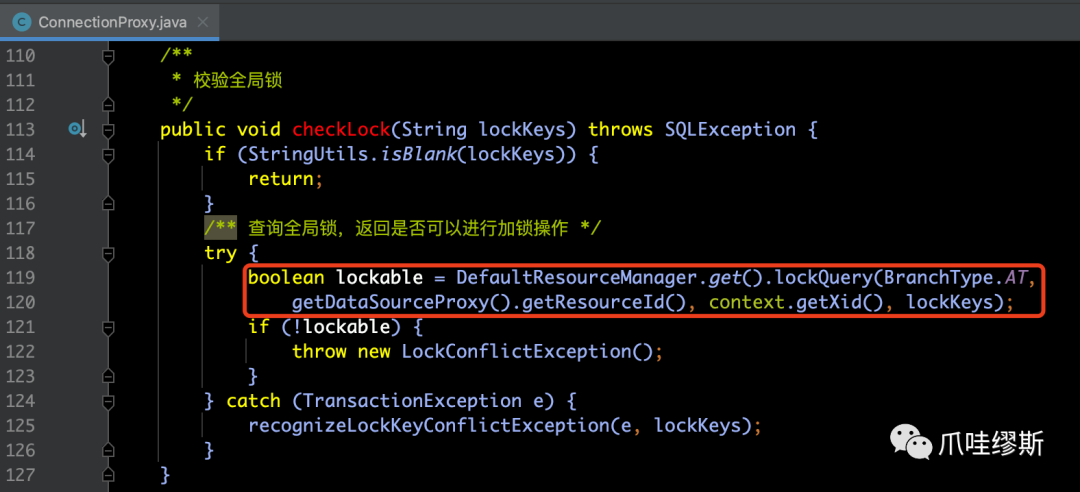
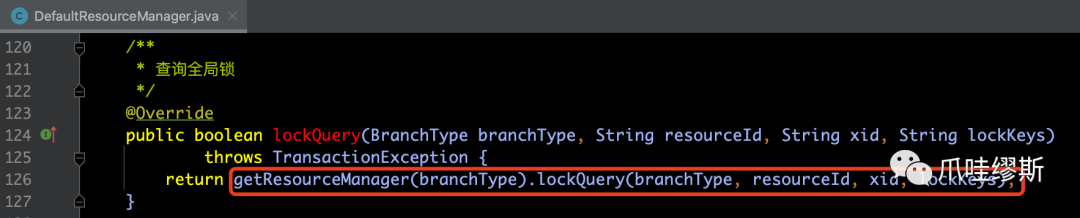
- 其中,根据不同的branchType,来实现不同的lockQuery方法,下面是AT模式
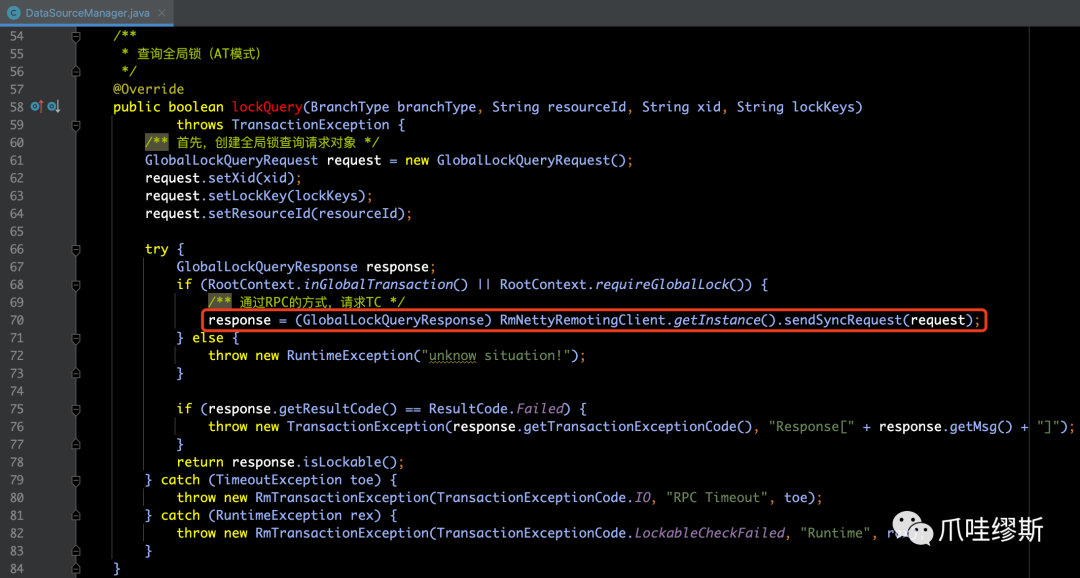
- 除了AT模式之外,其他的模式都是不支持全局锁的,即:直接返回“无全局锁”

b-3> 通过SPI获得响应的实现类
- 我们以获得UndoLogParser为例子,看一下如何通过SPI机制获得UndoLogParser实现的子类

- UndoLogParserFactory.getInstance()方法如下所示:
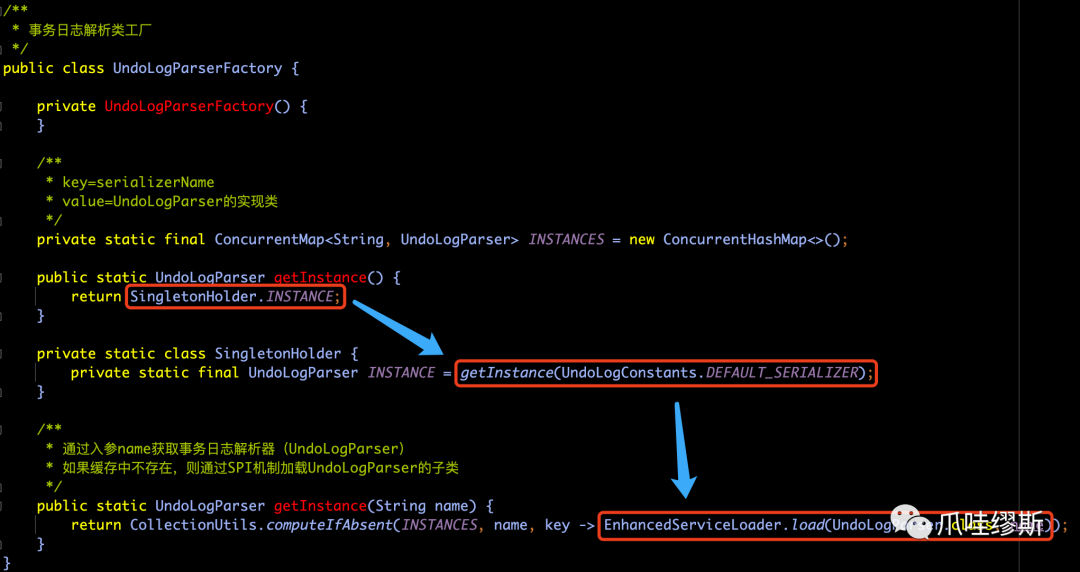


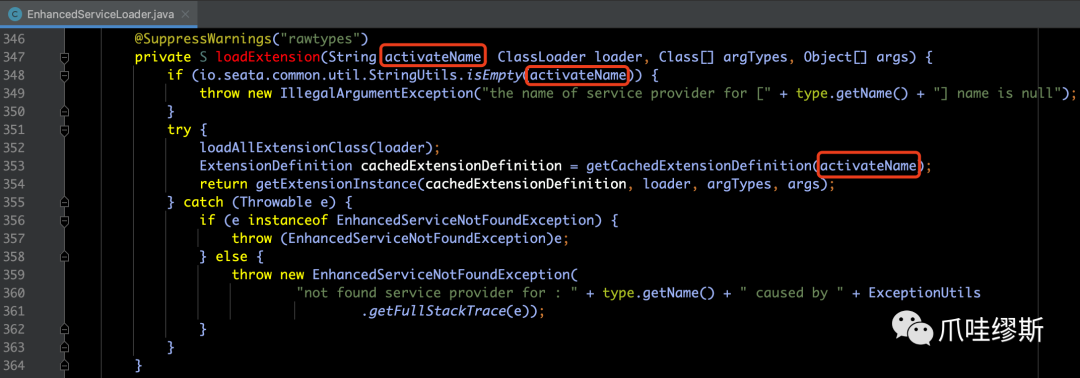

【解释】随着代码的深入跟踪,我们看到最后是从nameToDefinitionsMap通过查询key是activateName来获得UndoLogParser的实现子类。
- 那nameToDefinitionsMap是从哪里初始化的呢?我们来看EnhancedServiceLoader.getUnloadedExtensionDefinition(),在该方法内执行了向nameToDefinitionsMap中赋值的操作,如下所示:
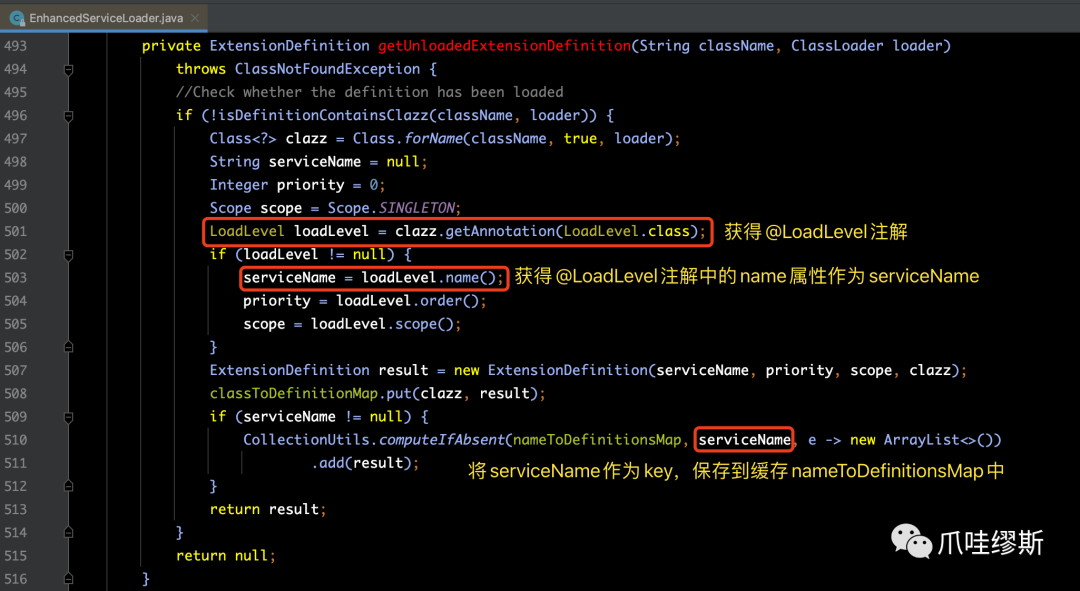

【解释】从上面的源码中我们可以看到,如果我们要获取一个UndoLogParser的某个子类的时候,可以通过指定serviceName的方式,例如:serviceName=“jackson”,那么,再根据io.seata.rm.datasource.undo.UndoLogParser文件中配置的所有UndoLogParser实现类去查找。根据每个实现类的@LoadLevel注解中的name属性,来进行匹配。
4.4.4> StatementProxy和PreparedStatementProxy
- Statement与PreparedStatement的区别
- Statement用于执行静态SQL语句,PreparedStatement用于执行预编译SQL语句的。
- 在使用PreparedStatement对象执行SQL语句时,SQL语句会首先被数据库解析和编译,然后被放到命令缓冲区中。每次执行同一个PreparedStatement对象,SQL语句会被解析一次,但不会被再次编译。在缓冲区中有预编译的命令,并且可以重用。
- PreparedStatement对象可以减少编译次数,提高数据库的性能,并且有更好的安全性。
- 同样向数据库中插入N条记录,PreparedStatement对象会比Statement插入效率高很多。
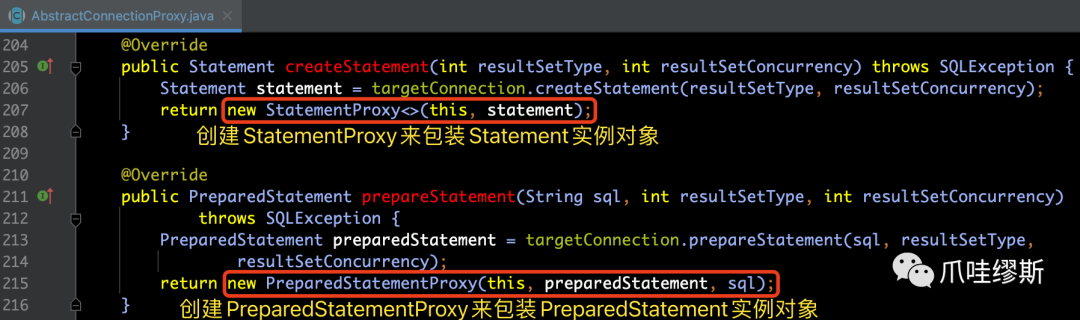
- 在AbstractConnectionProxy中提供了创建StatementProxy和PreparedStatementProxy的方法,如下所示:
- PreparedStatementProxy的类关系图如下所示:
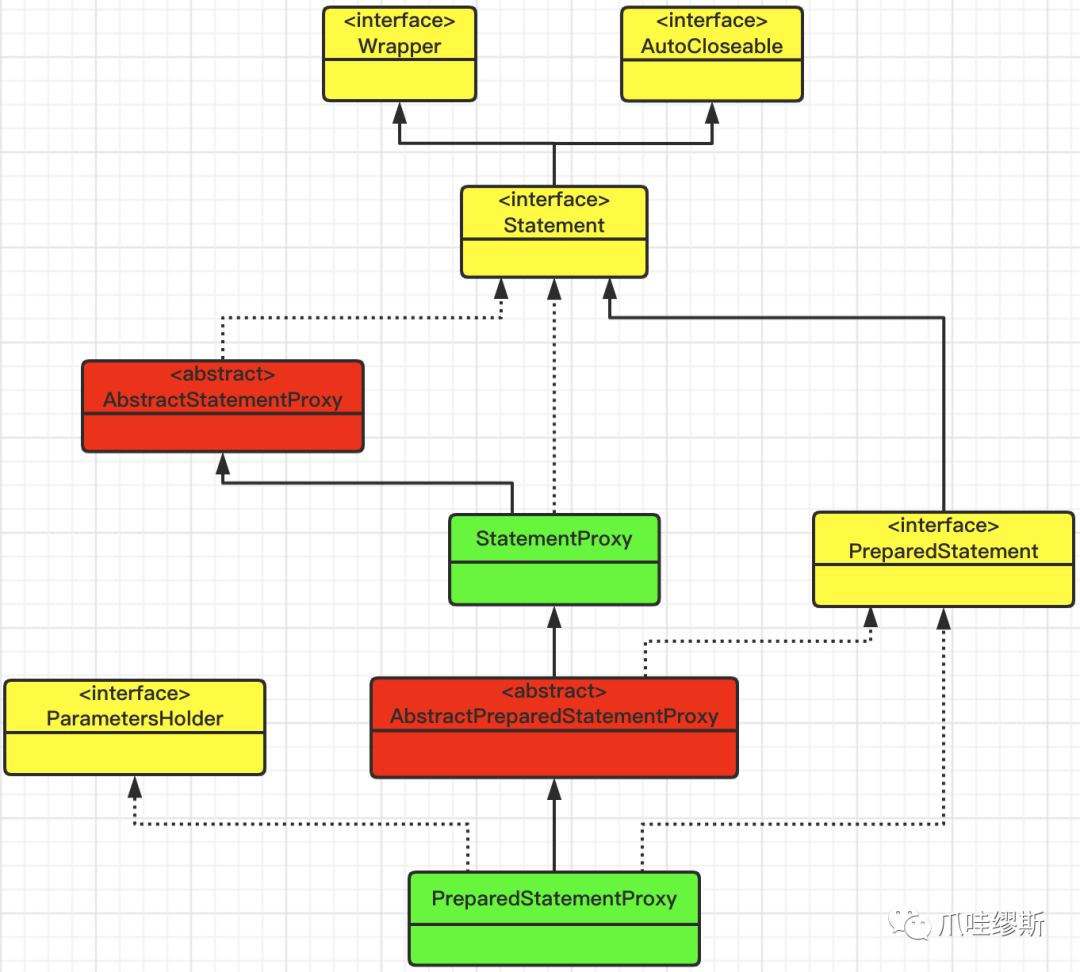
a> AbstractStatementProxy
- AbstractStatementProxy中包含3个变量,分别为:connectionProxy、targetStatement和targetSQL。
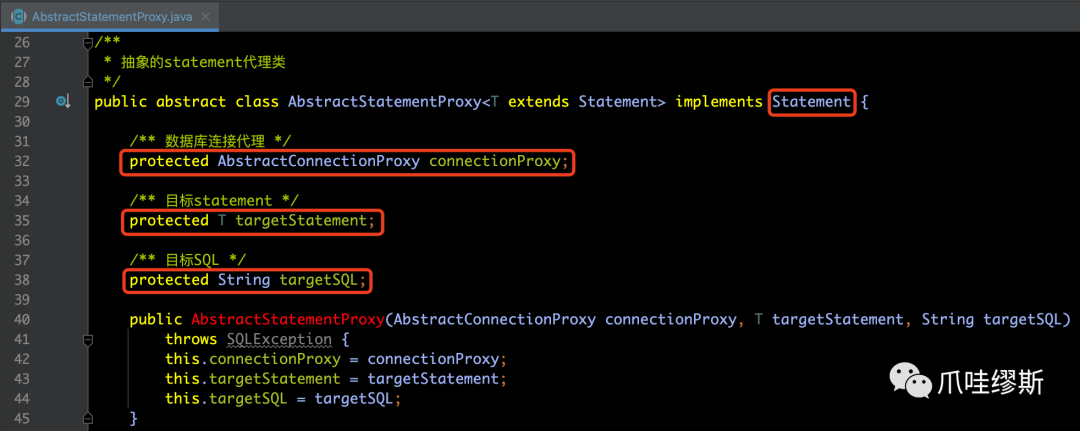
该类中很多方法都是直接调用targetStatement实现的,代理类没有做额外的工作,如下所示:
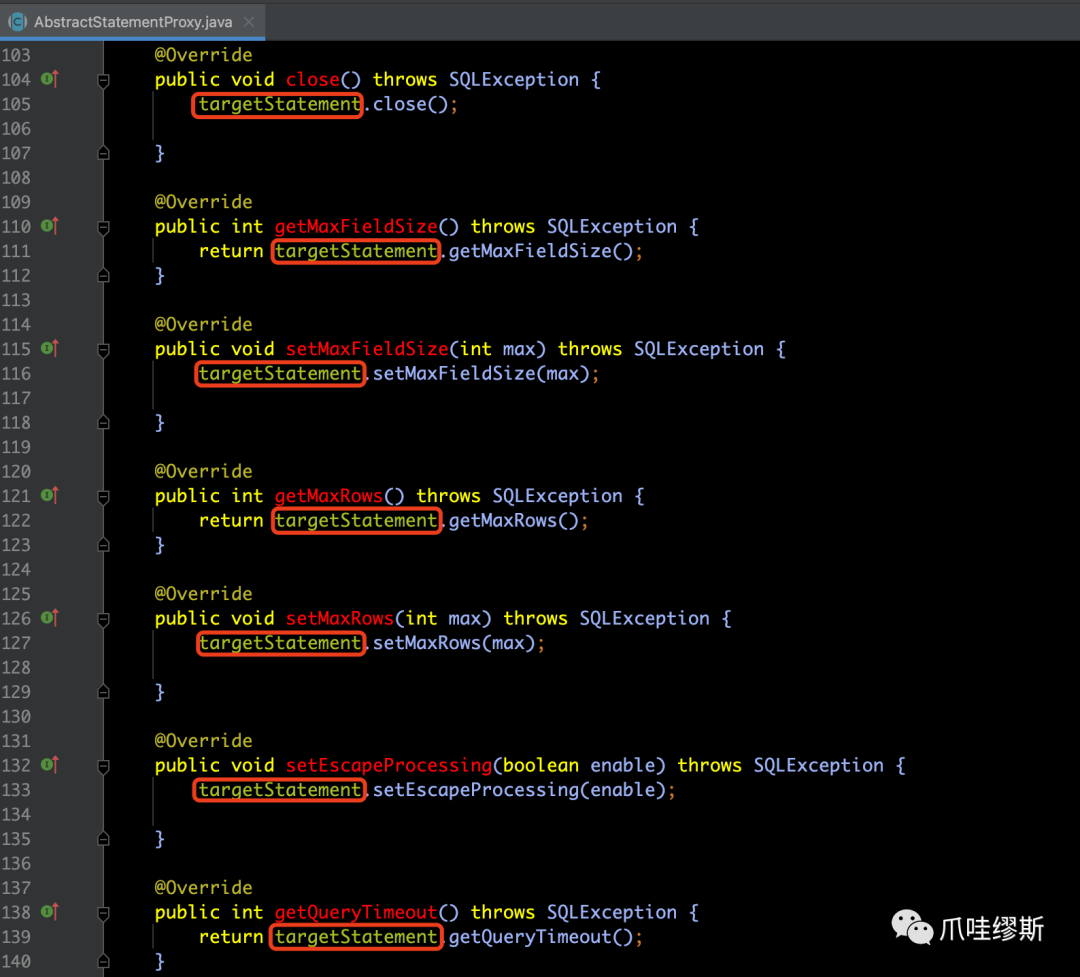
b> StatementProxy
- 我看来看AbstractStatementProxy的实现类StatementProxy的源码,我们会发现,这些方法真正实现都是通过执行模板类ExecuteTemplate的execute()方法来实现的。如下所示:
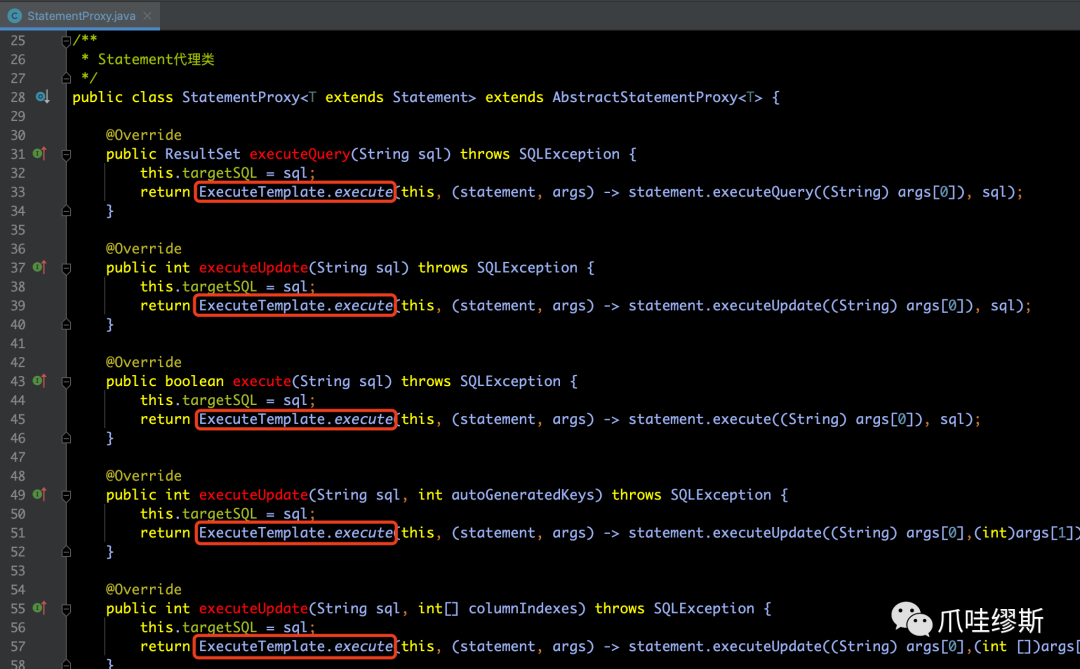
c> ExecuteTemplate执行模板类
- ExecuteTemplate本身只提供了execute(...)方法,源码注释如下所示:
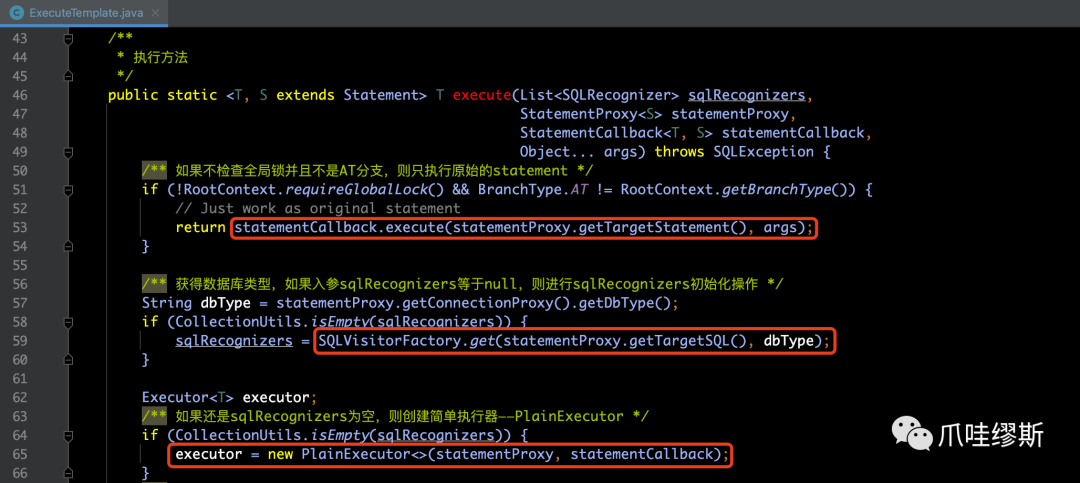
【解释】
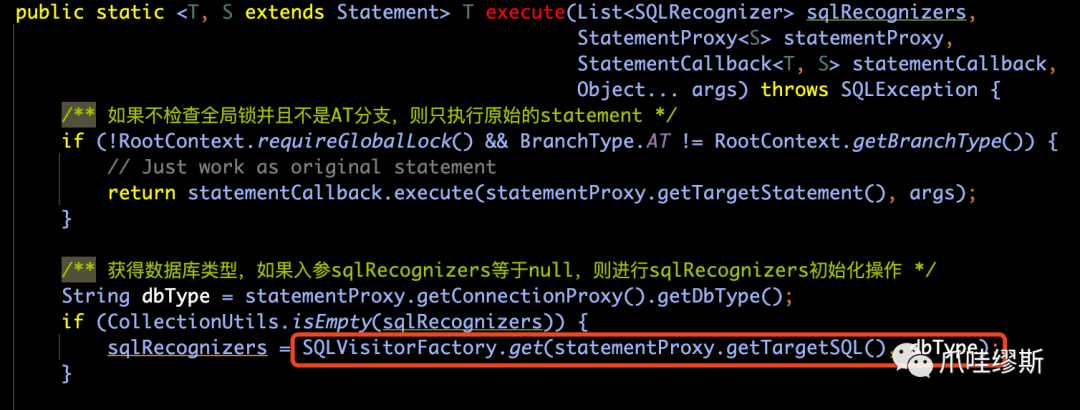
- 首先,判断这个SQL语句不在分布式事务中,并且也没有查询Seata全局锁的要求,则不需要将其纳入Seata框架下进行处理。只需要执行原始的statement即可。
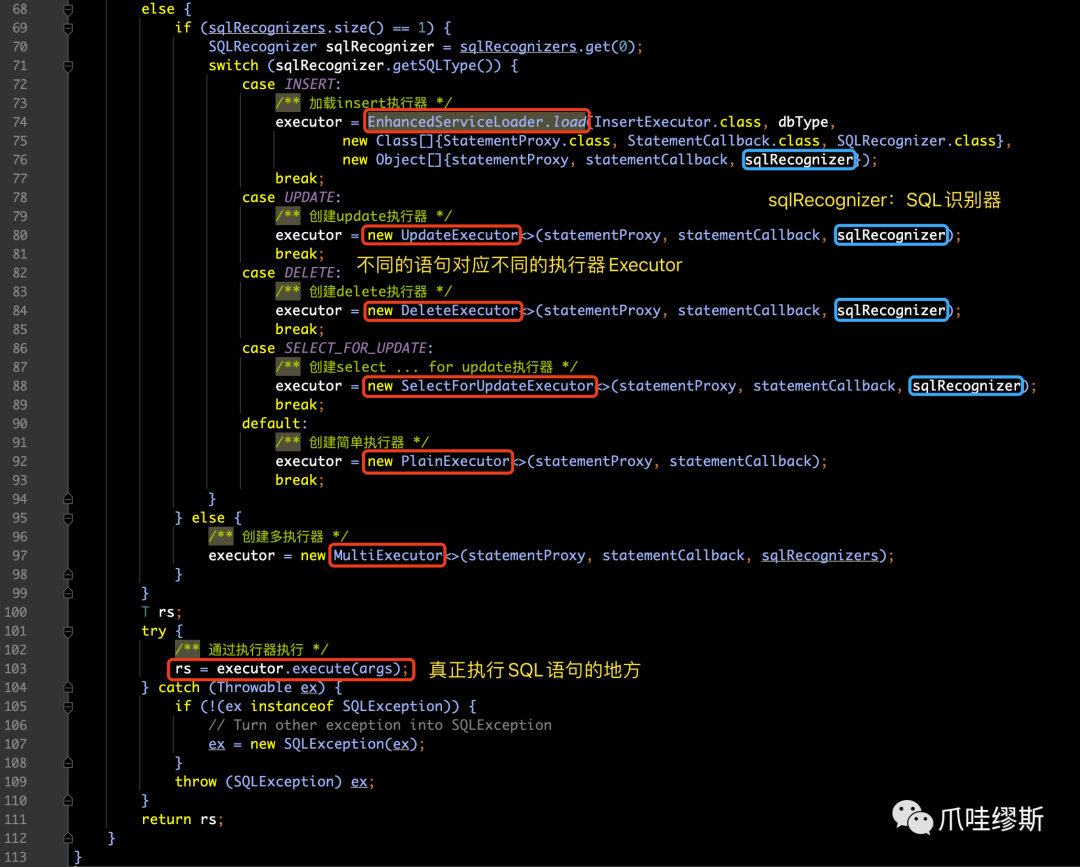
- 如果这个SQL语句在分布式事务中,则将其纳入Seata框架进行处理,并且根据不同的SQL语句类型选用不用的执行器Executor来执行。
- Seata框架处理的SQL语句包括:insert、update、delete、select...for update。
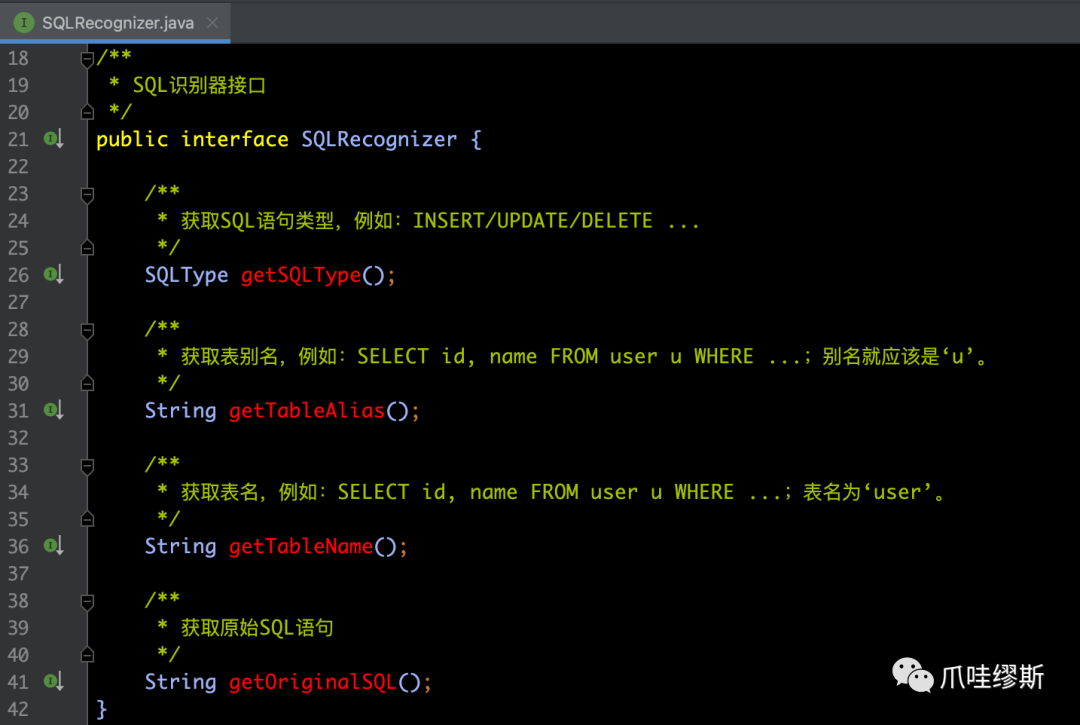
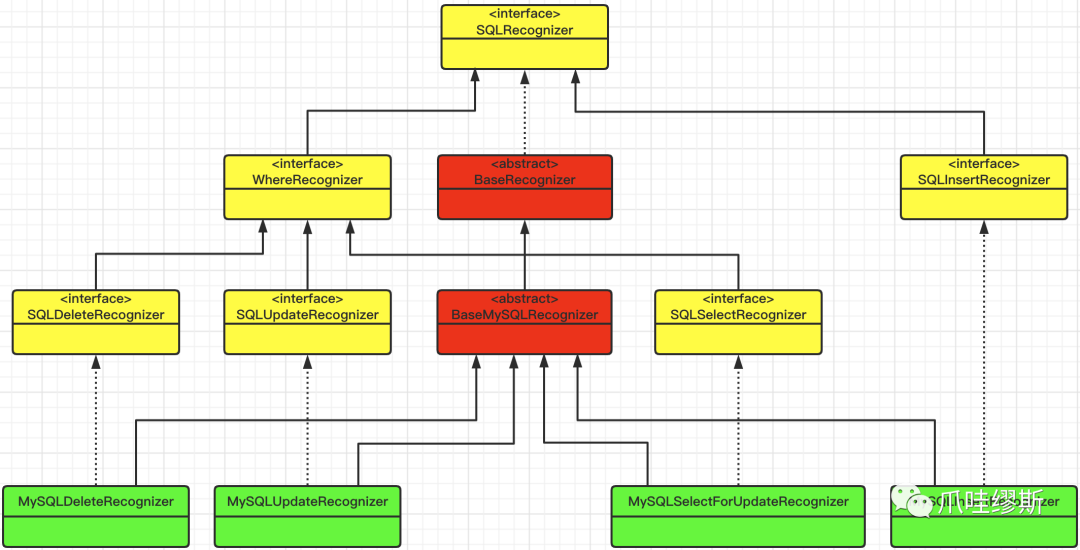
c-1> SQLRecognizer
- SQL识别器的接口源码如下所示:
- 抽象类BaseRecognizer实现了SQLRecognizer接口,而针对不同的数据库,都有其对应的一组实现类,如下所示:
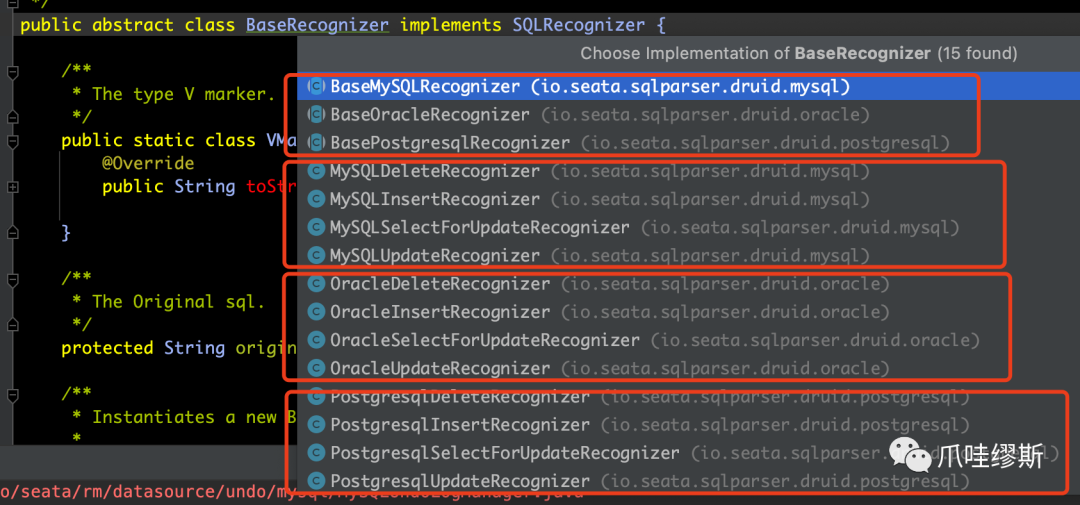
- 那么以我们常用的MySQL数据库为例,看一下MySQL相关接口的类图结构:
c-2> SQLVisitorFactory.get(...)
- 如果sql识别器集合是空的,则通过SQLVisitorFactory.get(...)去获取,如下所示:
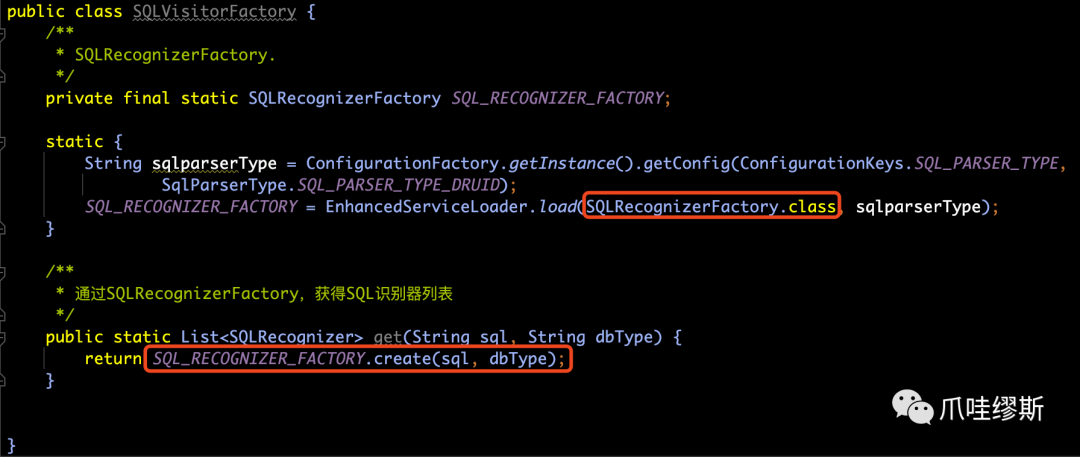
- SQLRecognizerFactory是SQL识别工厂。它是用于创建SQLRecognizer对象的。实现类如下所示:
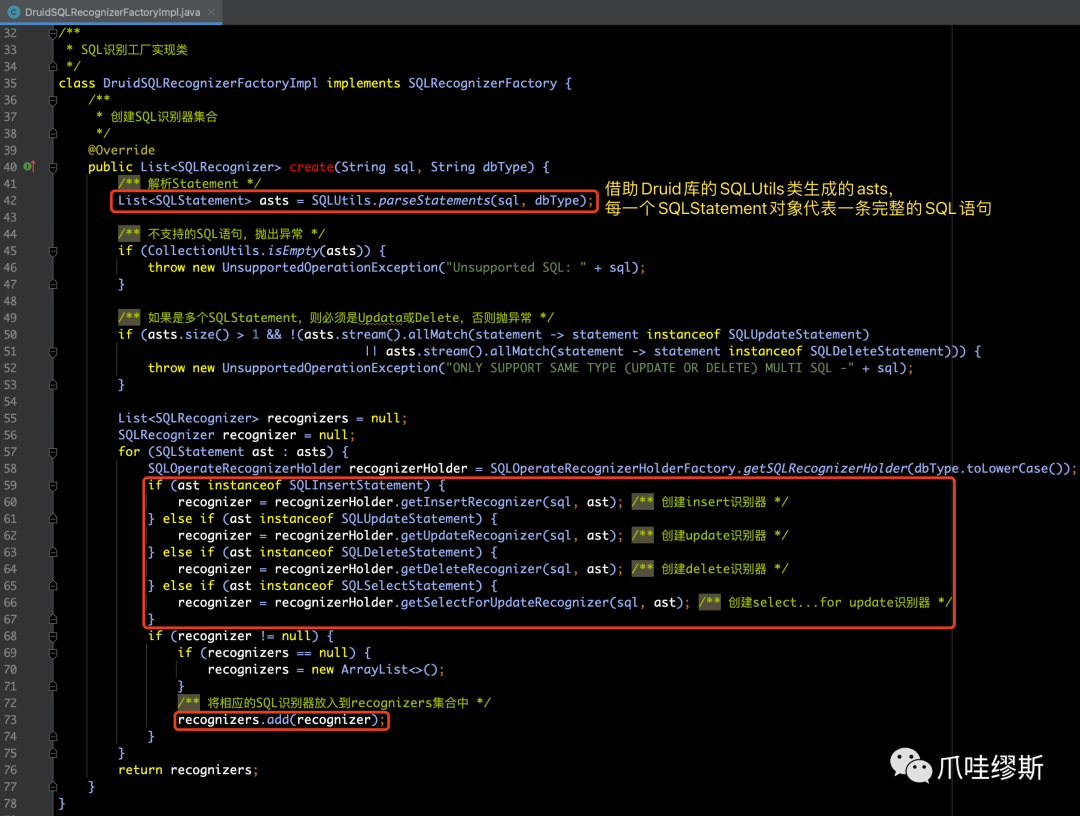
【解释】
- 这些识别器都要借助于开源Druid库生成的抽象语法树AST,由com.alibaba.druid.sql.SQLUtils.parseStatements()方法生成,该方法会把传入的SQL语句解析成SQLStatement对象集合,每一个SQLStatement对象代表一条完整的SQL语句。
- Seata AT模式使用了Druid的解析器解析SQL语句。
c-3> Executor
- SQL执行器Executor接口类图如下所示:
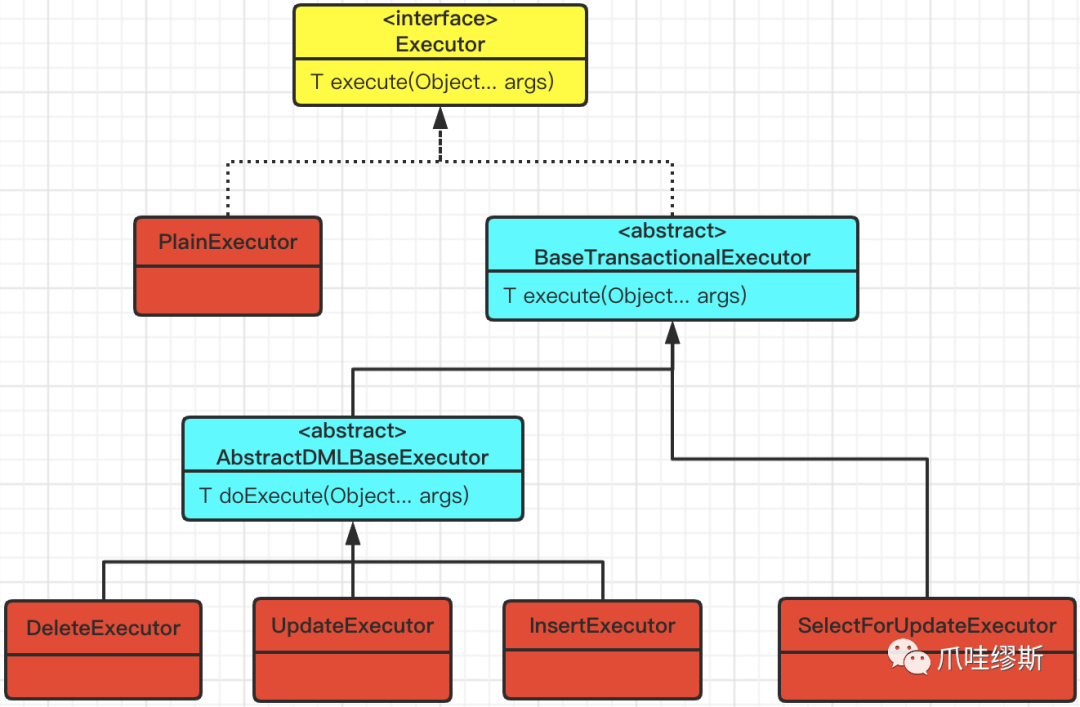
- Executor接口仅提供了一个方法,即:execute(Object... args)
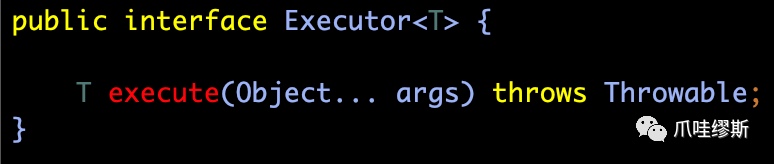
- BaseTransactionalExecutor实现了Executor的execute(...)方法,如下所示:
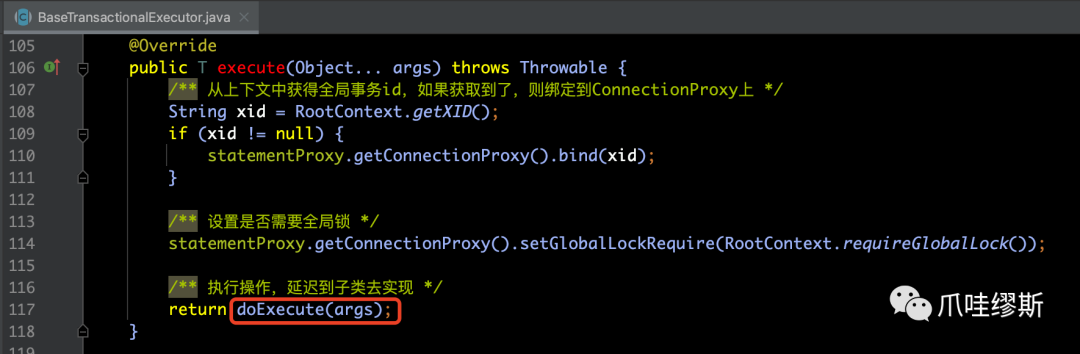
【解释】
- 如果处于分布式事务中,则会绑定全局事务id。
- 如果需要查询Seata全局锁,则在连接上下文中设置需要查询Seata全局锁的标识。
- 最后执行doExecute()方法,该方法由具体的子类去实现。
- 其中,AbstractDMLBaseExecutor实现了BaseTransactionalExecutor的doExecute()方法,具体实现如下所示:
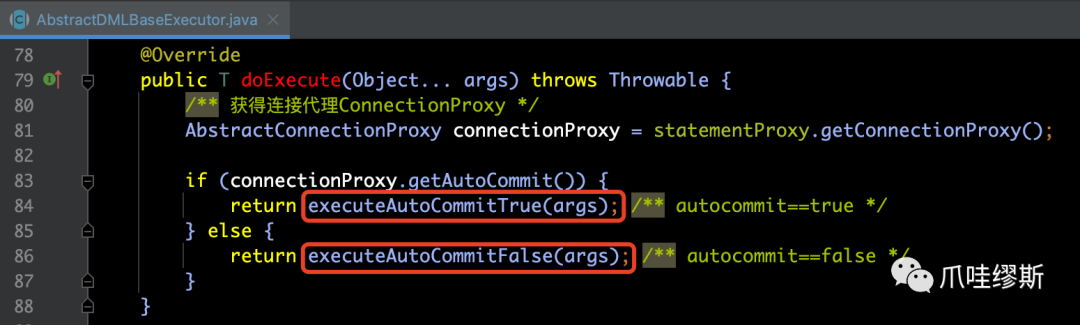
【解释】
- 首先,通过statementProxy获得了连接代理connectionProxy。
- 其次,通过connectionProxy的getAutoCommit()方法可以判断出本次连接是否是事务自动提交的。
- 如果autocommit=1,则执行executeAutoCommitTrue(args)。
- 如果autocommit=0,则执行executeAutoCommitFalse(args)。
- 下面我们来看一下AbstractDMLBaseExecutor的executeAutoCommitTrue(args)方法
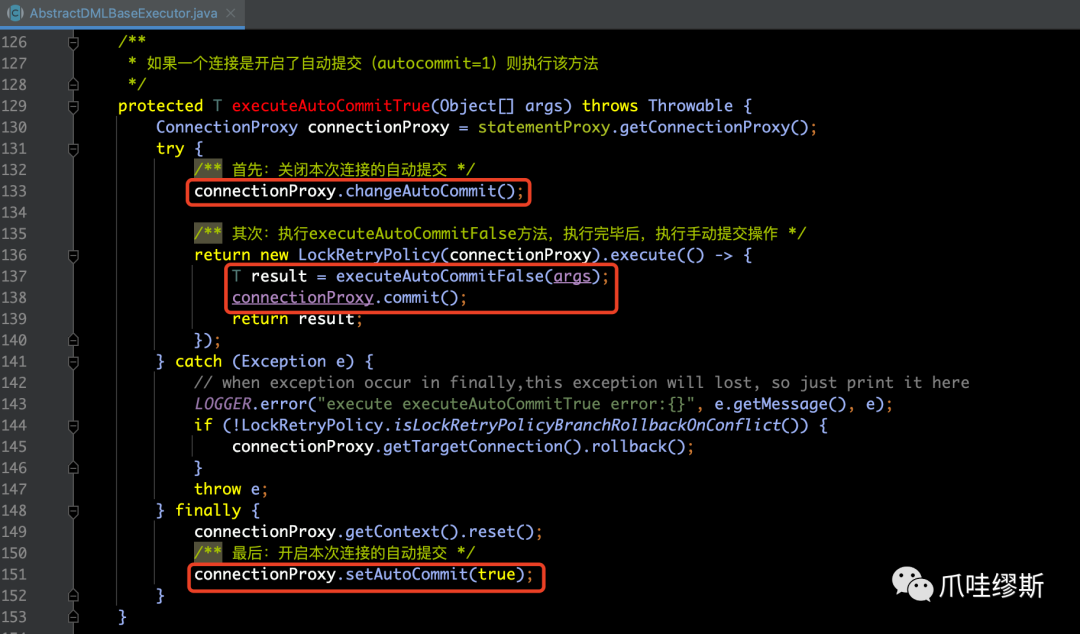
【解释】从上面代码中的逻辑我们可以看出来,针对于已经开启自动提交的连接,会先关闭自动提交,然后调用的实际执行逻辑是executeAutoCommitFalse方法,执行完毕后,会手动进行提交操作,并且最后开启自动提交。
- 下面我们来看一下AbstractDMLBaseExecutor的executeAutoCommitFalse(args)方法
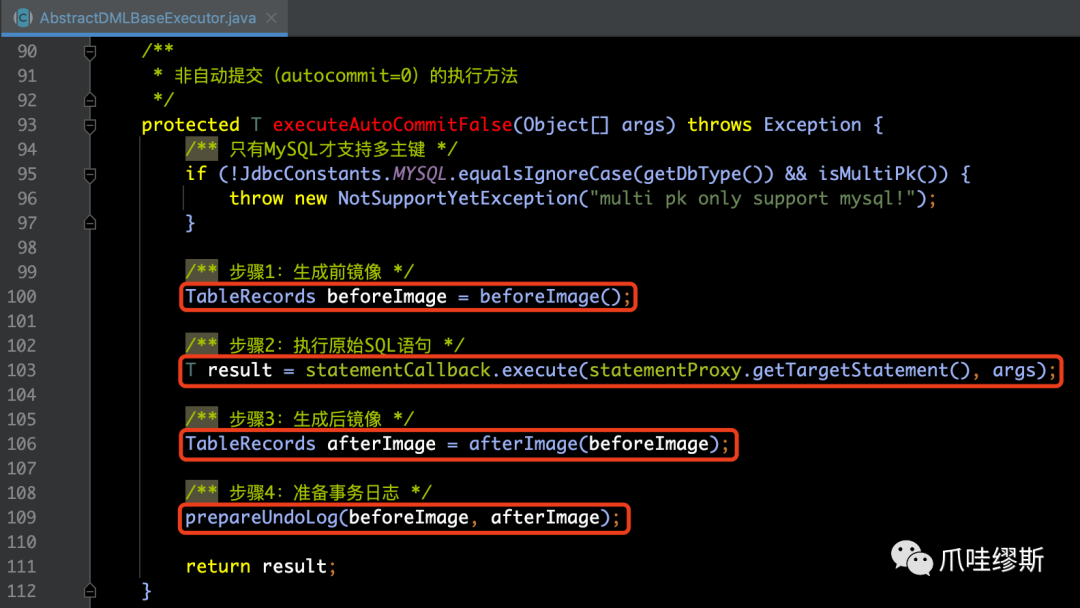
【解释】目前只有MySQL数据库支持多个主键。对于其他数据库,如果表存在多主键,则不允许使用AT模式,但是可以使用TCC、Saga或XA模式。
- 下面我们会针对这4个步骤进行解析
Step1> beforeImage
- 对于不同的SQL类型,匹配不同的执行器Executor,那么对于beforeImage()方法的实现也是不同的。对于insert语句来说,前镜像是空的。而update和delete语句在前镜像实现上是类似的,下面以update语句为例:
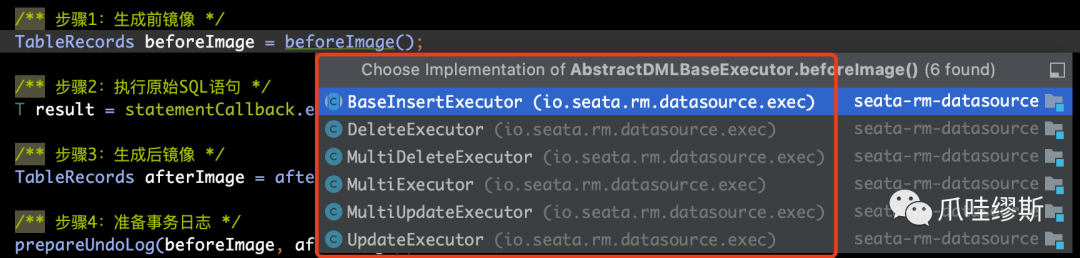
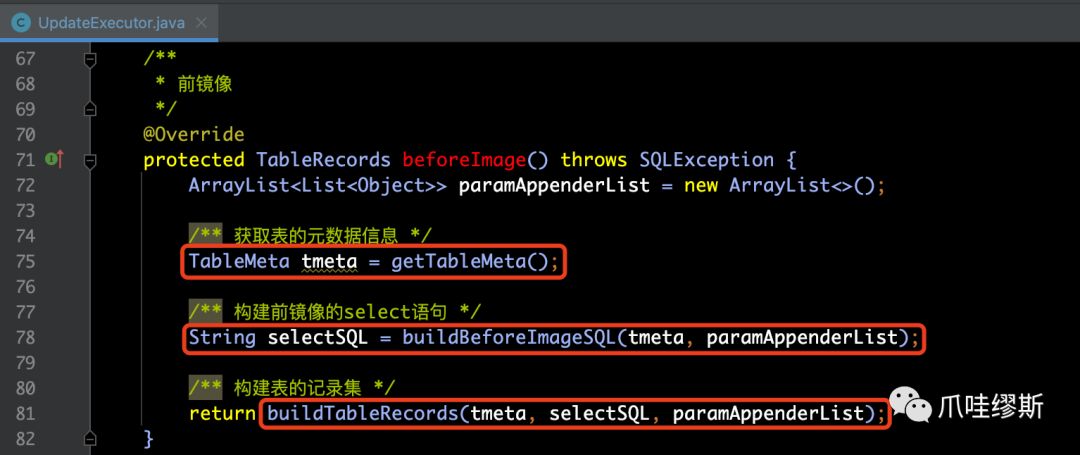
【解释】
- getTableMeta()方法已经在4.2.1中介绍过了,此处就不介绍了。
- 前面也介绍过,前镜像和后镜像都被存放在TableRecords对象中。
- UpdateExecutor的buildBeforeImageSQL()用于构建一条查询前镜像记录的SQL语句,源码如下所示:
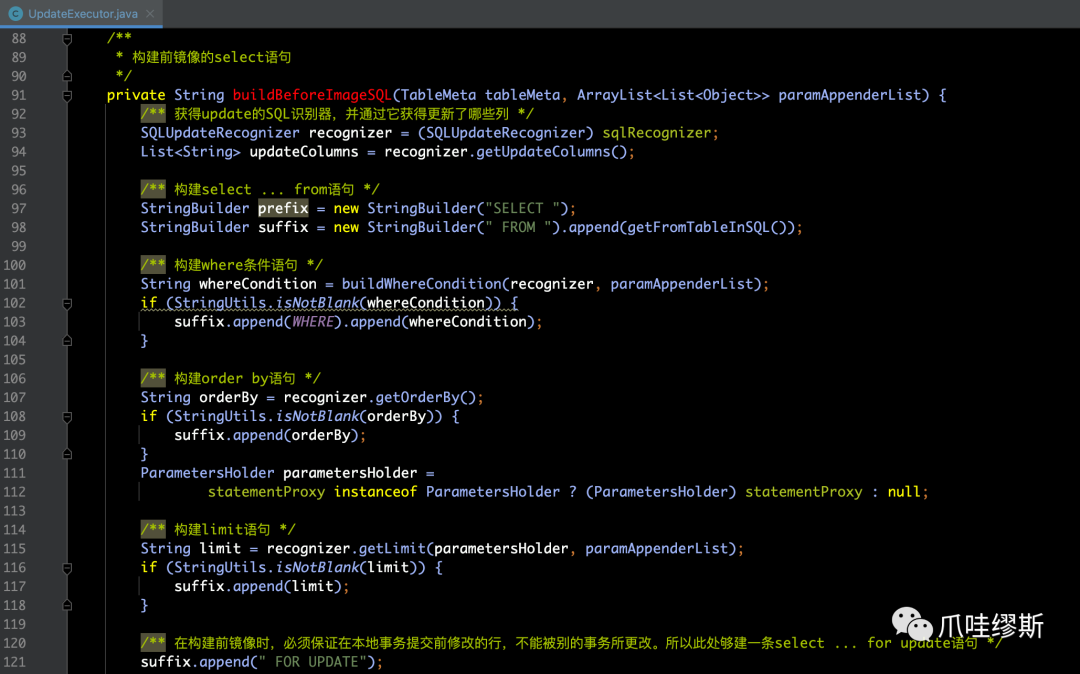
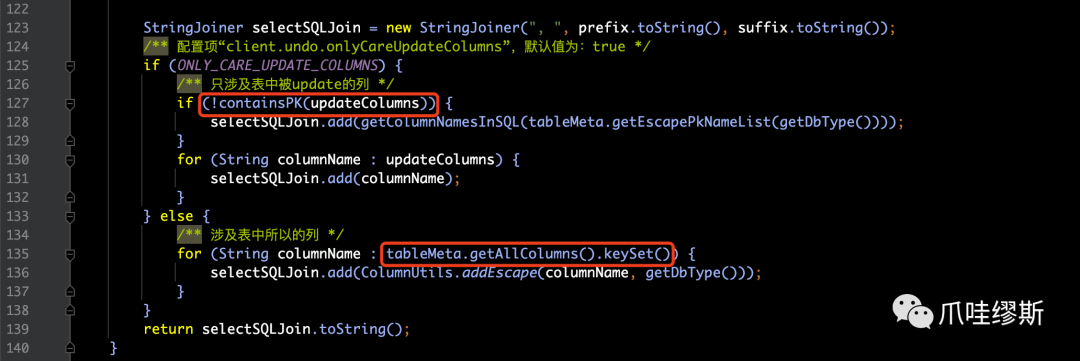
【解释】
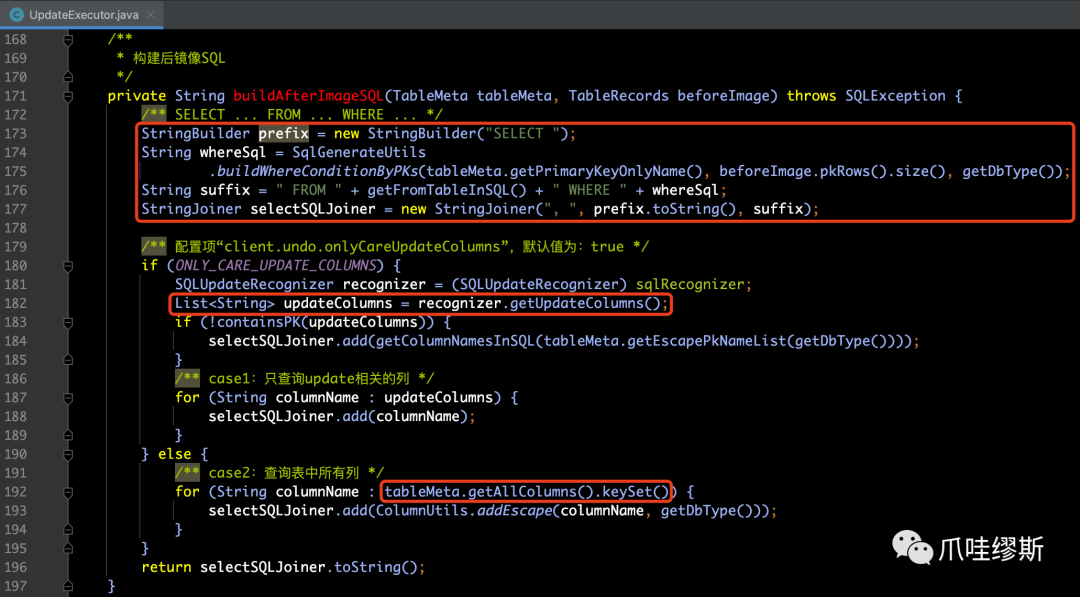
- 通过上面的源码我们发现,拼装的逻辑主要是通过update的SQL识别器,即:SQLUpdateRecognizer来实现的。
- 最终拼装一条“select ... from ... where ... order by ... limit ... for update”的SQL语句,并把参数放在paramAppenderList列表中。
- 获得到了selectSQL语句后,随后会执行buildTableRecords()方法,如下所示:
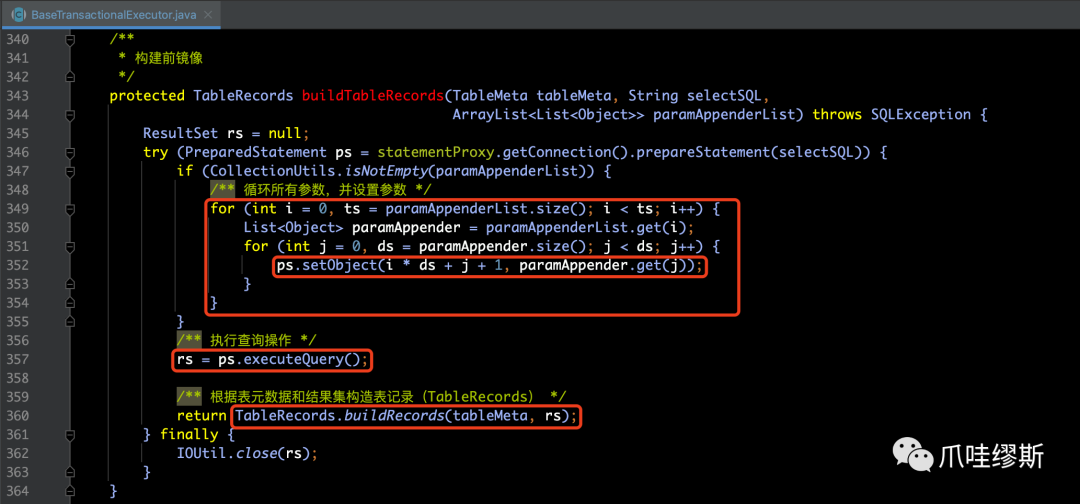
【解释】
- 首先:基于拼装的selectSQL来创建一个PreparedStatement实例对象。
- 其次:遍历paramAppenderList,对预编译SQL赋值参数。
- 然后:执行ps.executeQuery()获得结果集ResultSet。
- 最后:通过TableRecords.buildRecords(...)方法将ResultSet转换为TableRecords。
Step2> execute
- 步骤2中,就是利用目标statement执行原始SQL语句,如下所示:

Step3> afterImage
- 步骤3中,利用afterImage生成后镜像,它与beforeImage方法一样,都是抽象的方法,具体实现都延迟到子类中了。如下所示:
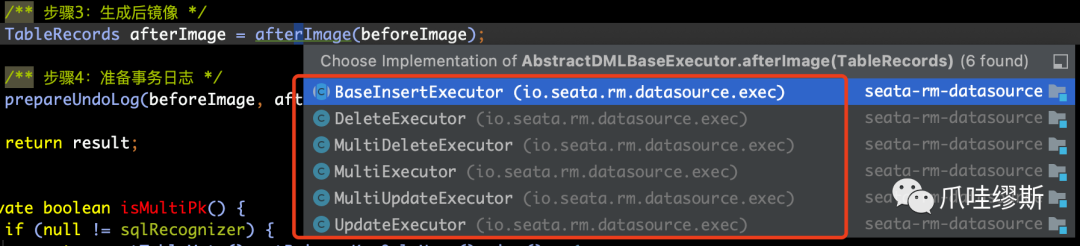
- 如果是delete语句,则后镜像是空的。其中update和Insert在构造方式比较相似,我们还是以UpdateExecutor为例,看一下是怎么处理的后镜像。
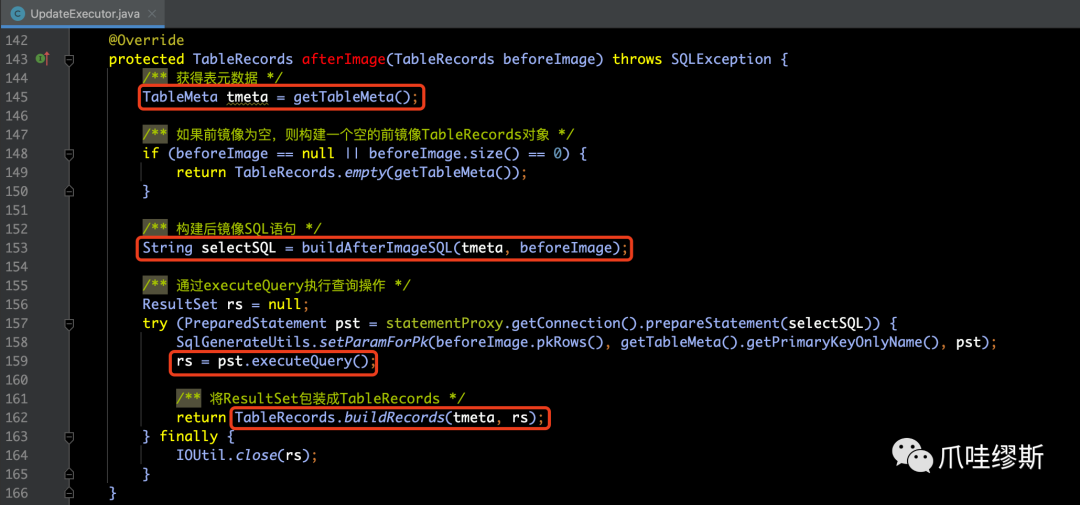
- buildAfterImageSQL(...)方法用于构造后镜像SQL,如下所示:
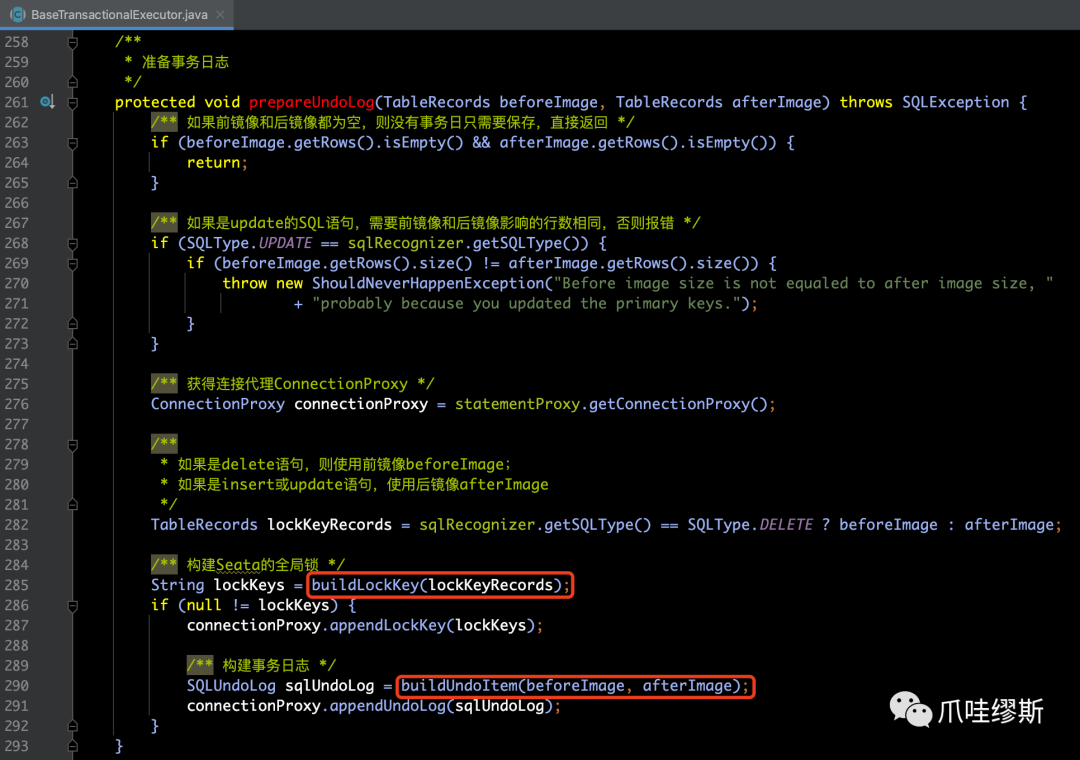
Step4> prepareUndoLog
- 第四步骤是准备事务日志,即:BaseTransactionalExecutor.prepareUndoLog(...)
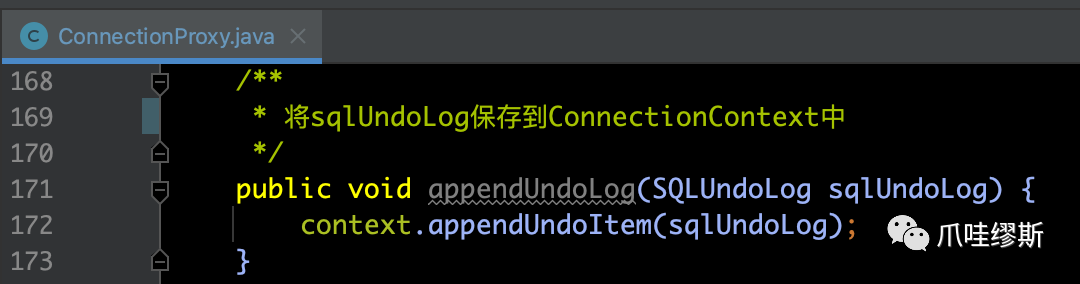
其中,将合并后的事务日志保存到连接上下文ConnectionContext中
【解释】
- 如果beforeImage和afterImage都为空,则直接返回。因为没有事务日志需要保存。
- 检查update语句的beforeImage和afterImage行数是否相同,如果不相同,则直接报错。对于update来说,前镜像和后镜像保存的是相同行,所以行数应该是相同的,只是行的内容不同。
- 通过调用buildLockKey()方法构建Seata行锁数据
- 如果是delete语句,则使用beforeImage;
- 如果是insert或update语句,则使用afterImage;
- 一个本地事务中可能包含多条SQL语句,每条SQL语句都可能生成Seata行锁数据,需要在构建完成本条SQL语句的行锁数据后将这些行锁数据合并成一个大字符串。
- 执行buildUndoItem()方法把beforeImage和afterImage构建为undoLog,把新构建的undoLog与用该本地事务中别的SQL语句已经构建的undoLog合并在一起。
4.5> AT模式的两阶段提交
4.5.1> 一阶段处理
- 一阶段处理流程如下所示:

【解释】
- 首先:在一阶段中,Seata会先拦截业务SQL语句,解析SQL语句的语义,提取表元数据,找到SQL语句要更新的业务数据。
- 其次:在业务数据被更新前将其保存成前镜像。
- 然后:执行SQL语句更新业务数据;在业务数据更新后,将其保存成后镜像,并生成Seata事务锁数据,构建事务日志并且插入事务日志表。
- 以update tb_user set name='muse' where id=1;为例,整个流程如下所示:
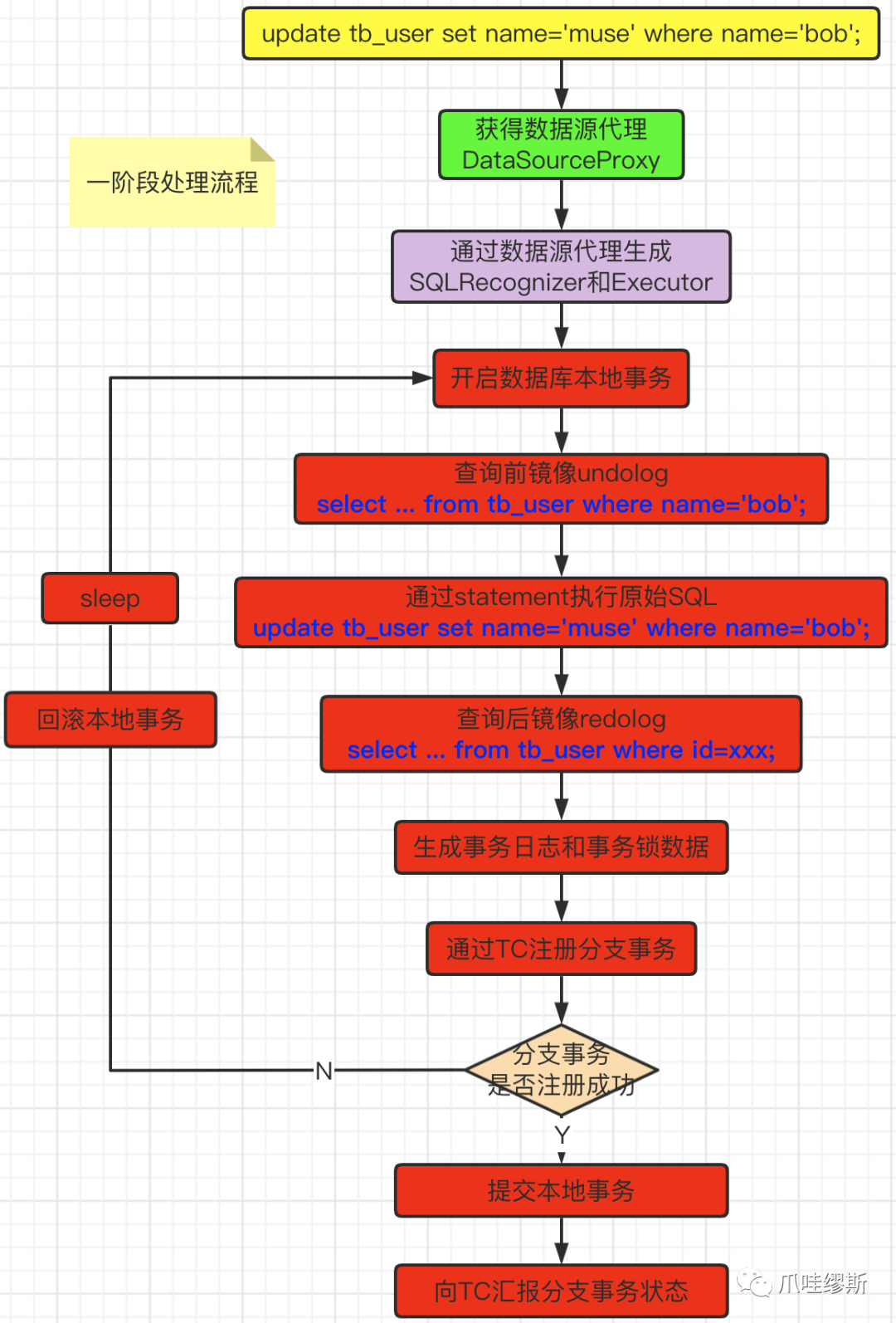
【解释】在本地事务提交之前,通过TC注册分支事务。
- 如果发生全局锁冲突,则回滚本地事务,在休眠一段时间之后重新开启数据库本地事务。
- 如果没有全局锁冲突,则注册分支事务成功。
- 一阶段的主要工作是生成SQLRecognizer、Executor、beforeImage、afterImage等。AT模式客户端的主要开销都在一阶段中。
4.5.2> 二阶段的提交处理
- 如果全局事务是提交状态,则TC会先进行“放锁”操作,然后释放各个分支事务在一阶段加的全局锁,并推进二阶段提交。
- RM在接收到分支事务二阶段提交指令后,只需要删除保存的事务日志数据,完成数据清理即可,因为SQL语句在一阶段中已经提交至数据库中了。
- 为了提升性能,RM会立即返回TC处理成功,并通过异步线程批量删除在二阶段中提交的分支事务的日志数据。
- 在AT模式中,是通过DataSourceManager.branchCommit()方法来完成分支事务的二阶段提交的,如下所示:
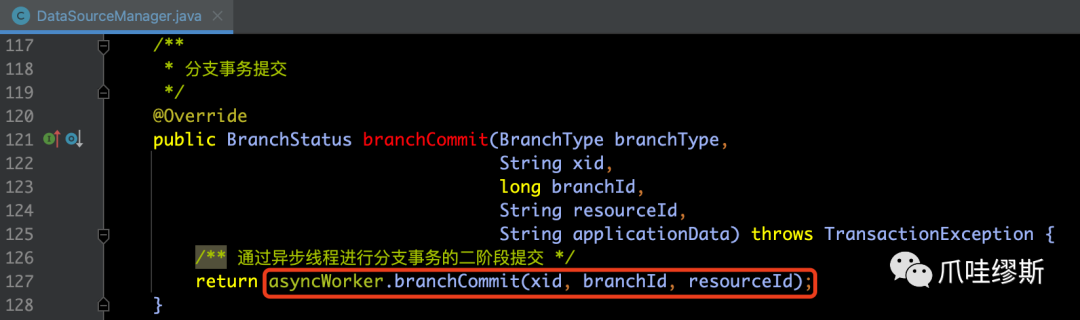
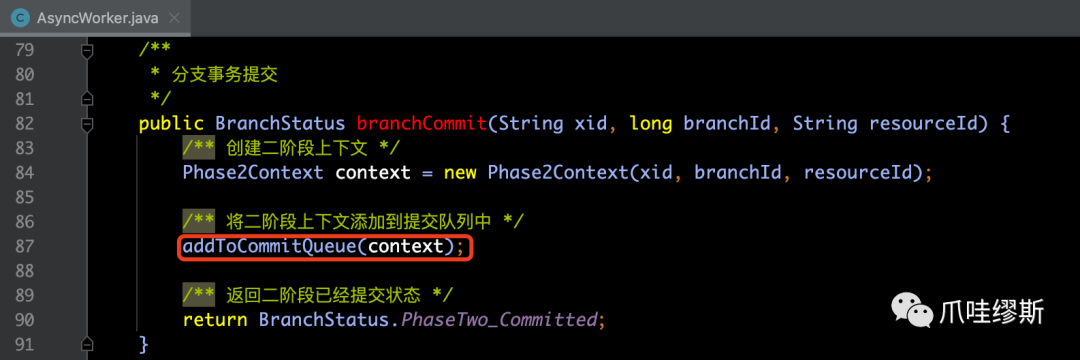
【解释】创建完二阶段上下文后,将二阶段上下文添加到CommitQueue中,随即就返回二阶段已提交状态了。此阶段采取的是异步方式,而非同步阻塞的方式。
- 下面,我们来着重看一下将二阶段上下文添加到CommitQueue的代码逻辑,如下所示:
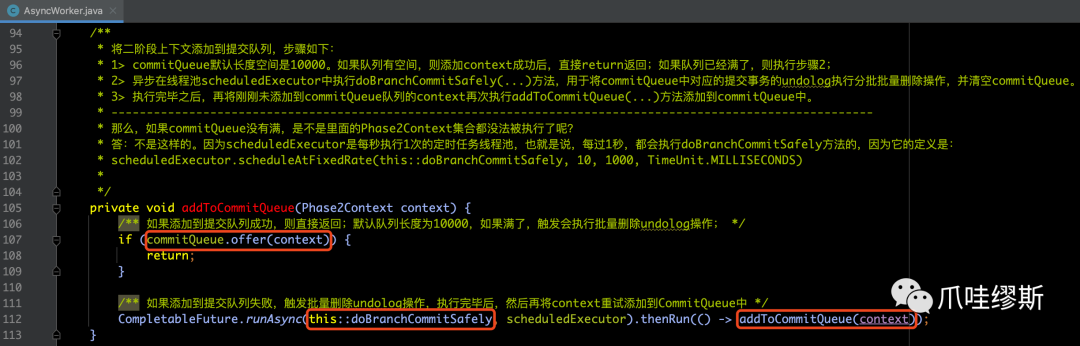
scheduledExecutor是每秒执行一次的定时任务线程池,如下所示:
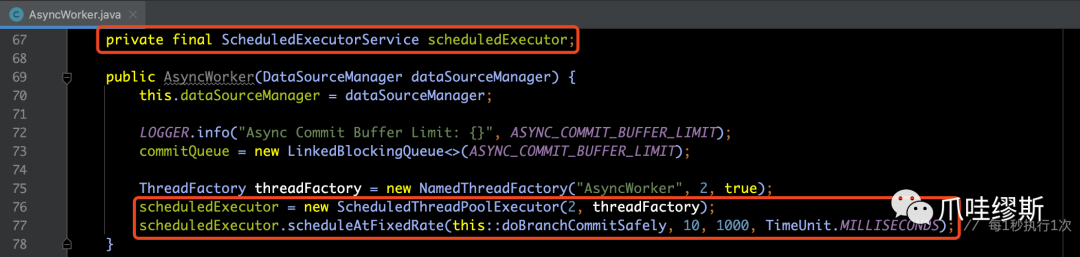
【解释】调用offer方法将Phase2Context提交到提交队列中。如果返回false,则说明commitQueue已经满了。
- 如果commitQueue已经满了,则会采取异步执行doBranchCommitSafely()方法,执行如下代码:
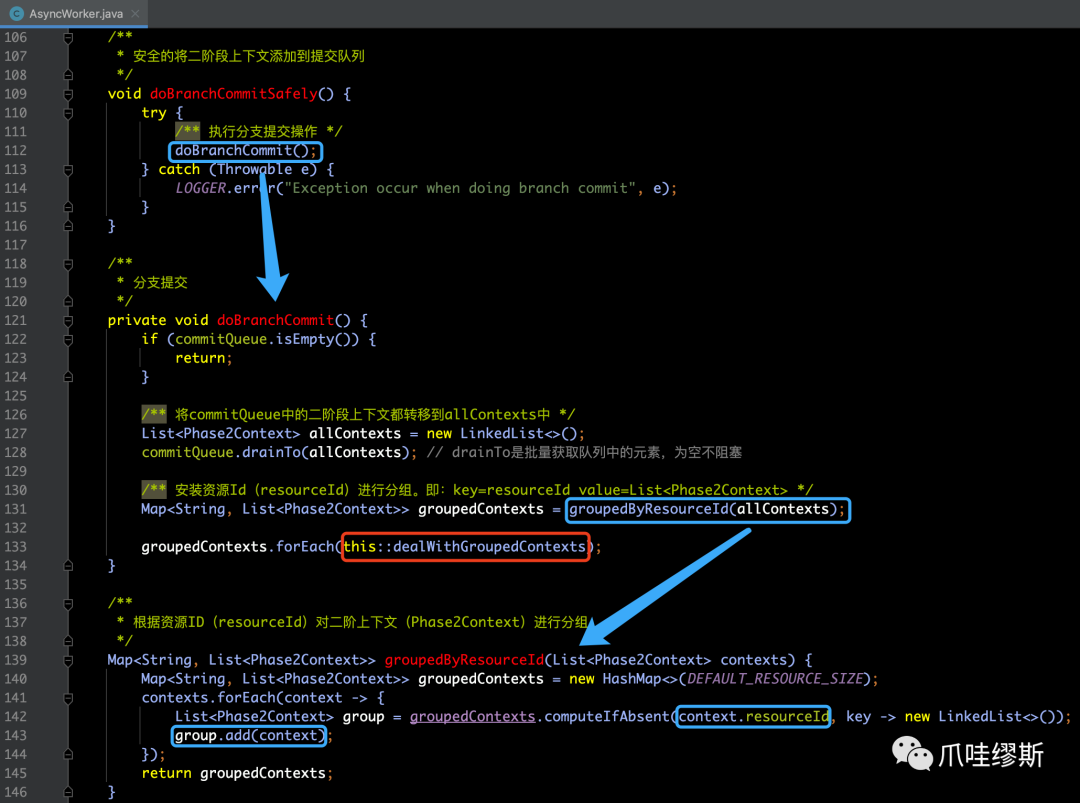
【解释】
- 该方法的入参是已经按照资源id汇总的二阶上下文集合,即:contexts中所有的二阶上下文的resourceId都是第一个入参值。
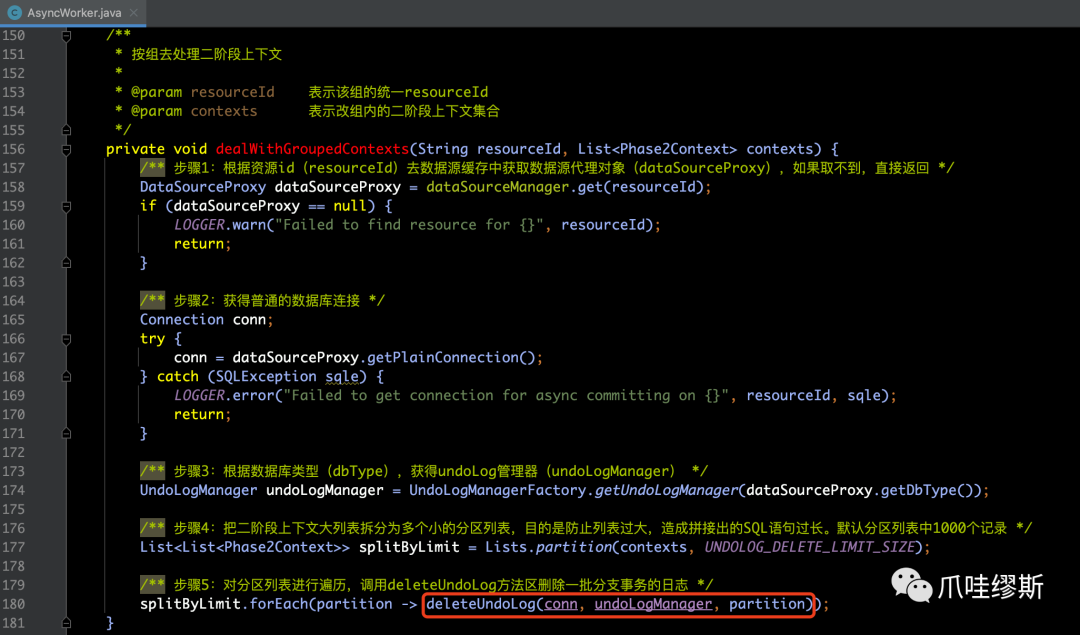
- 由于Phase2Context集合大小不确定,为了方式列表过大,拼装的SQL语句过长,所以默认采取每1000条记录为一组的方式进行分批切割操作。
- 然后针对每个批次进行批量删除undoLog操作,即:deleteUndoLog。
- 如下是批量删除undoLog的逻辑代码deleteUndoLog()的源码注释:
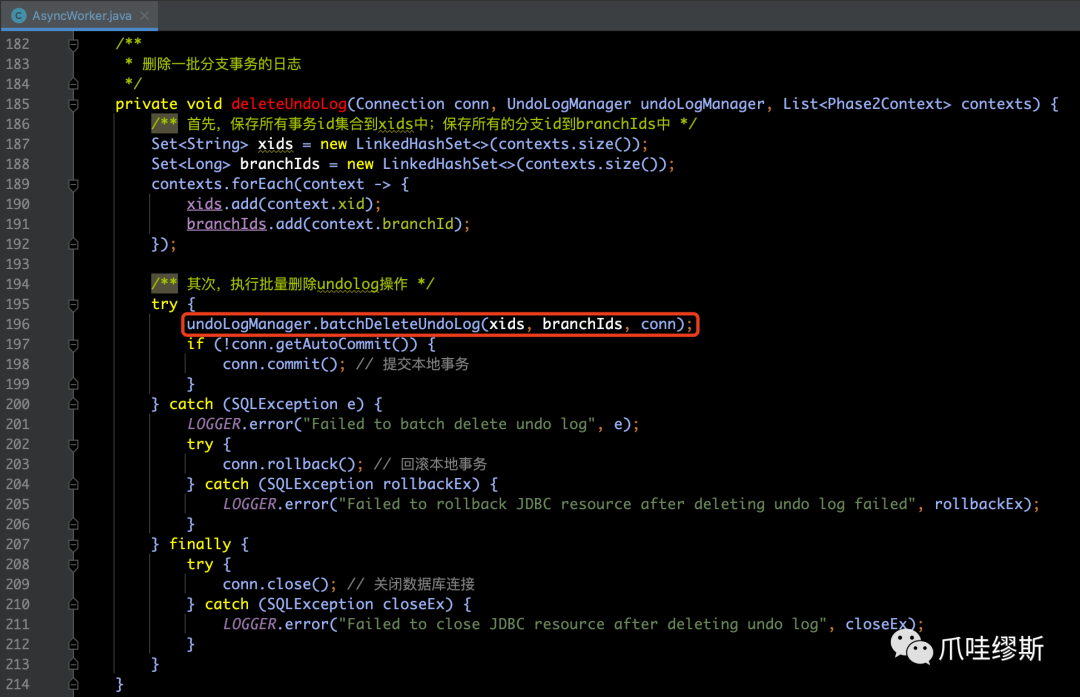
- 统计完事务集合xids和分支集合branchIds后,传递给batchDeleteUndoLog方法,源码如下所示:
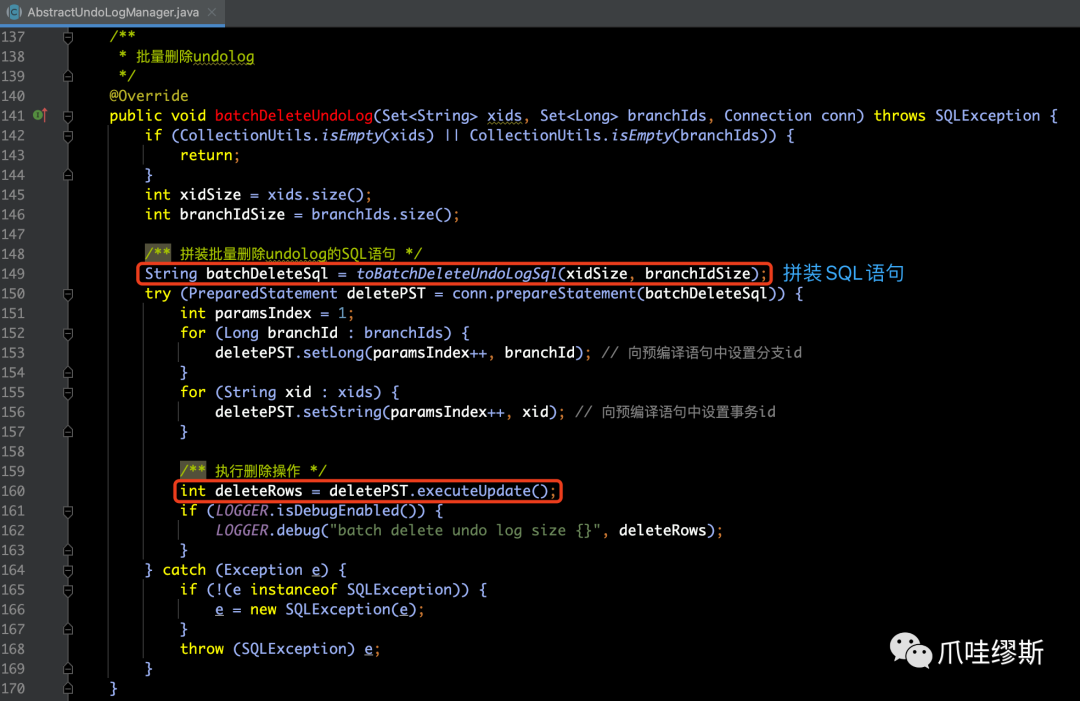
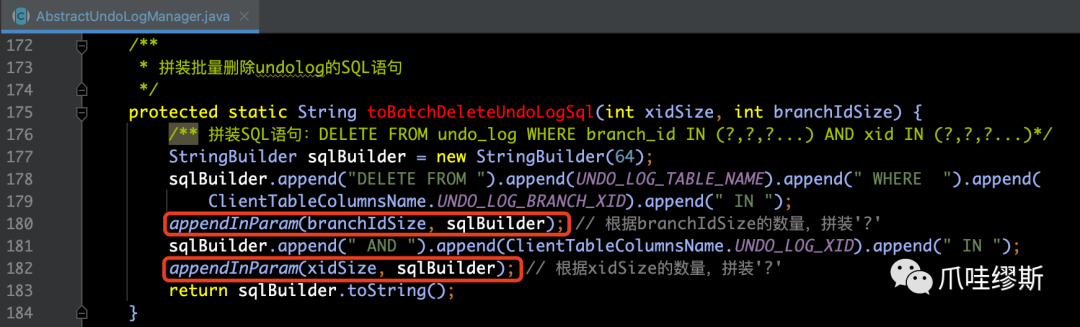
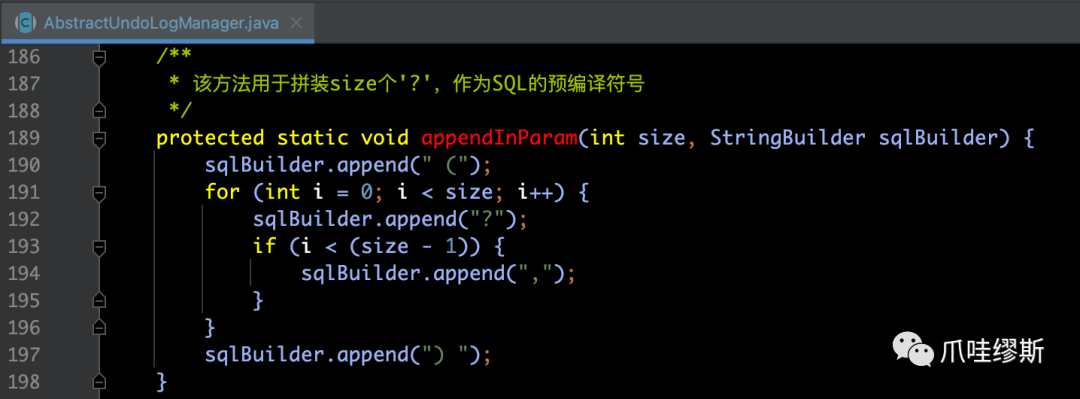
- 将事务id集合的size和分支id集合的size都传递给toBatchDeleteUndoLogSql方法的目的,就是用于拼装size个‘?’,作为预编译的占位符。拼装后的SQL类似于:DELETE FROM undo_log WHERE branch_id IN (?,?,?...) AND xid IN (?,?,?...);源码如下所示:
4.5.3> 二阶段的回滚处理
4.5.3.1> 概述
- 如果全局事务是回滚状态,那么TC会触发二阶段回滚操作。
- RM在收到分支二阶段回滚指令后,会回滚一阶段已经执行的业务SQL语句,还原业务数据。
- 二阶段回滚的基本思想是:用前镜像还原业务数据。如下图所示:
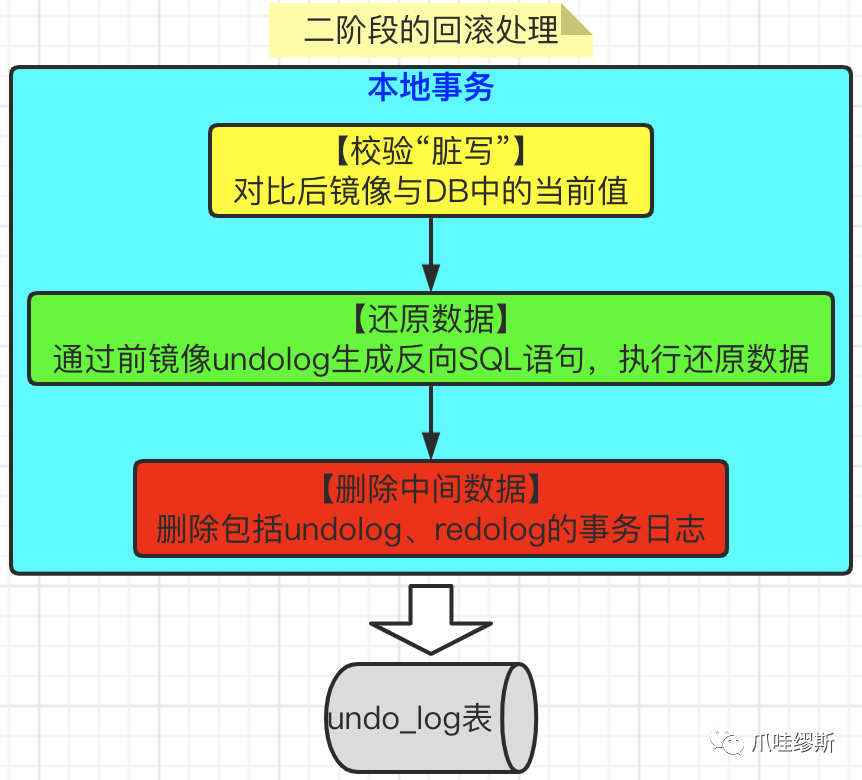
【解释】在还原前,要先校验“脏写”,即:对比后镜像和数据库中的当前值。
- 如果数据完全一致,则说明没有“脏写”,可以还原数据。
- 如果数据不一致,则说明有“脏写”,需要转人工处理。
- 要分析一下分支事务回滚逻辑,我们先来看一下DataSourceManager的branchRollback()方法,如下所示:
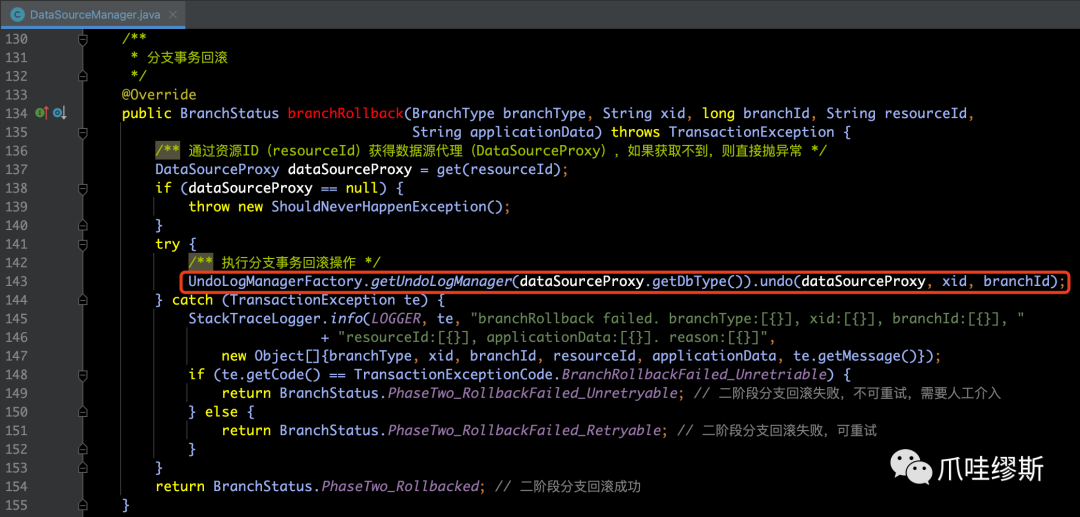
- 真正执行分支事务回滚操作的就是在AbstractUndoLogManager的undo(...)方法中
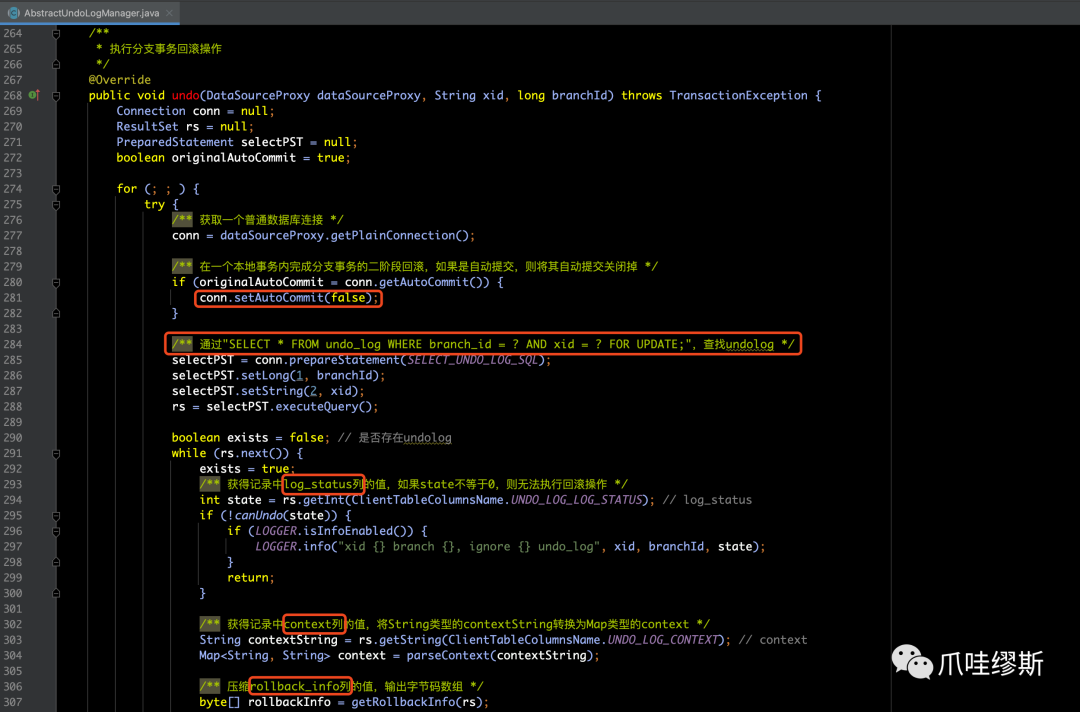
【解释】
- undo()方法核心逻辑:使用undo_log数据来补偿分支事务在一阶段中锁增加、删除、修改的数据。
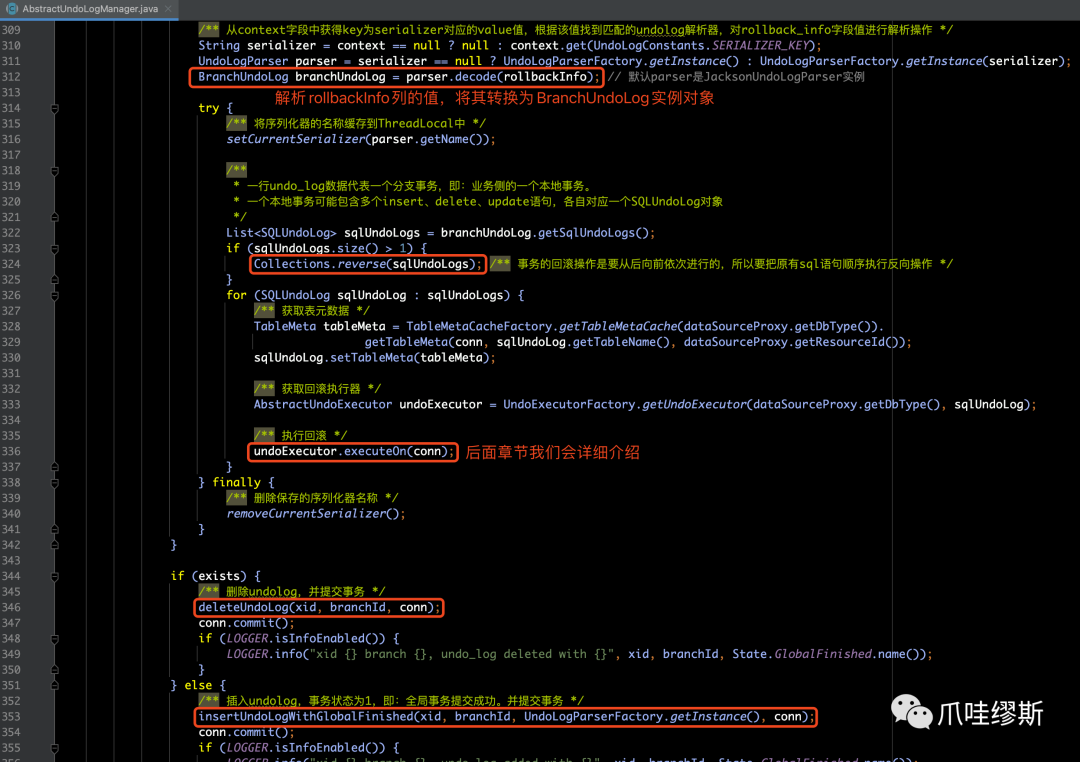
- 在上方代码中,先查找在undo_log表中本分支事务ID和XID所对应的记录,并把查到记录的rollback_info字段内容转化为BranchUndoLog对象,然后循环处理BranchUndoLog包含的所有SQLUndoLog对象。
- 对于每个SQLUndoLog对象,都使用Undo执行器完成回滚。在所有SQLUndoLog对象对应的回滚都完成后,删除分支事务对应的undo_log,并提交本地事务。
4.5.3.2> Undo执行器
- 对于每个SQL语句进行回滚,是通过AbstractUndoExecutor的executeOn()方法,如下所示:
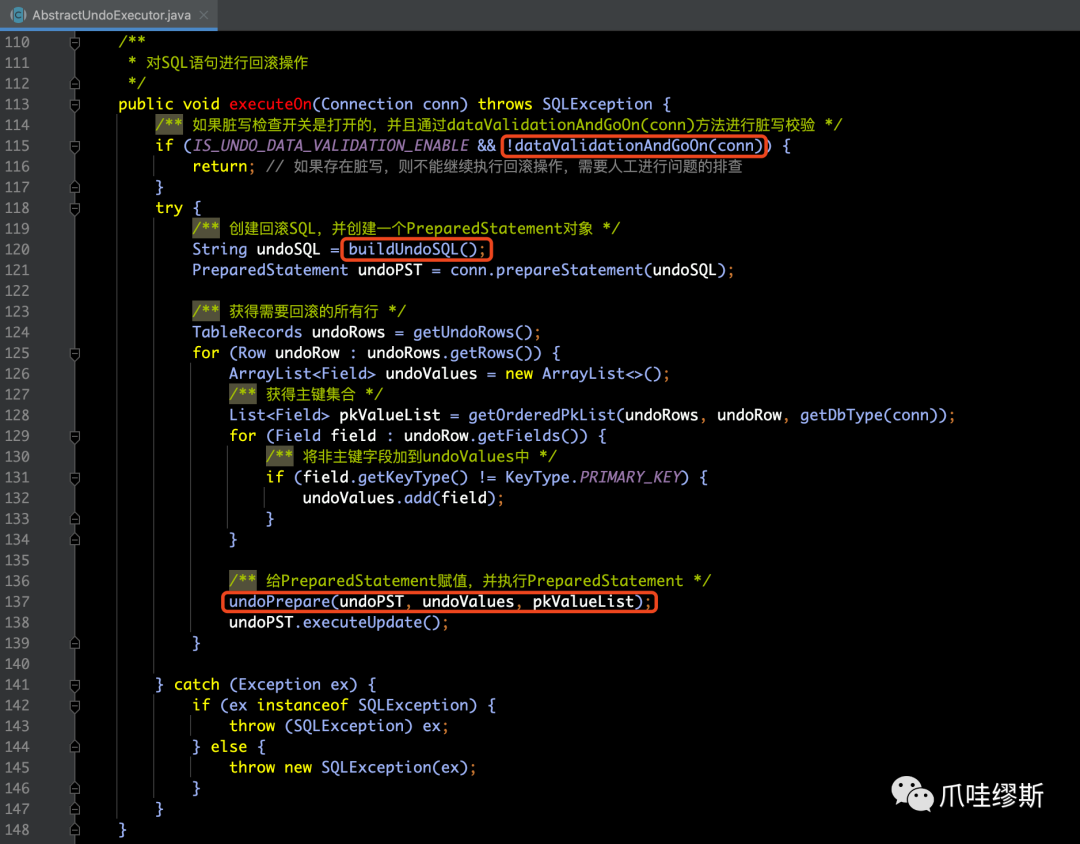
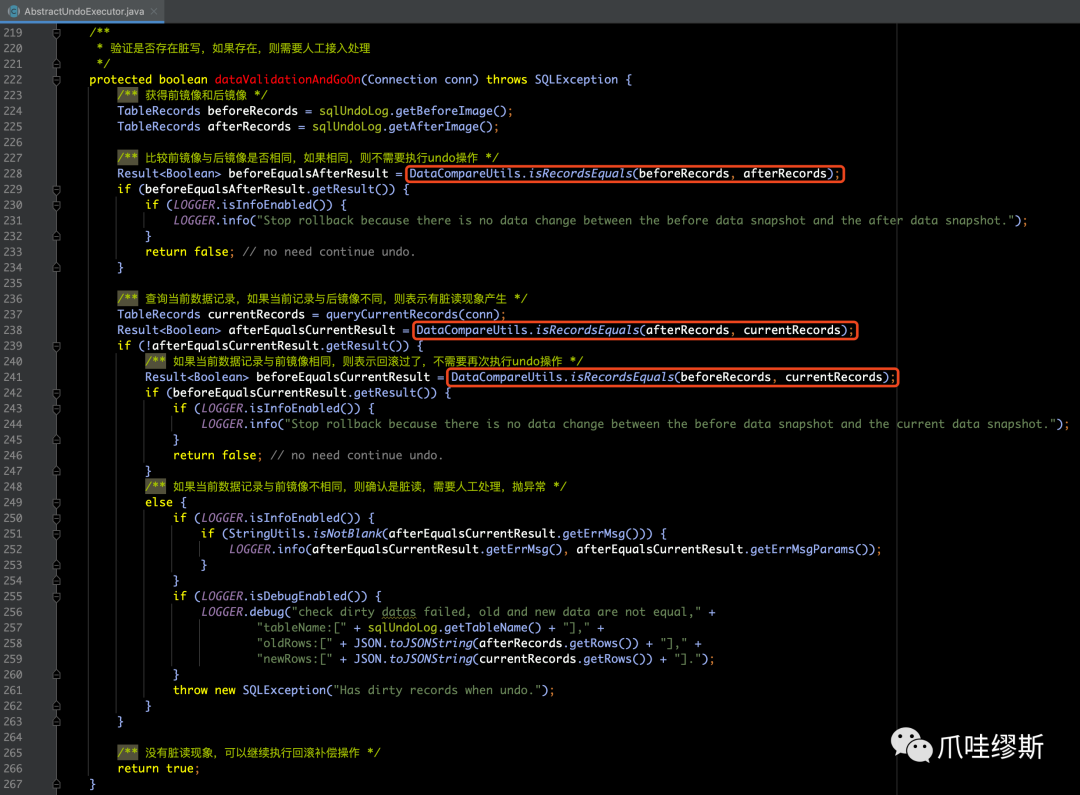
a> dataValidationAndGoOn
- 脏写检查的目的是防止错误的数据补偿。具体逻辑在AbstractUndoExecutor的dataValidationAndGoOn()方法:
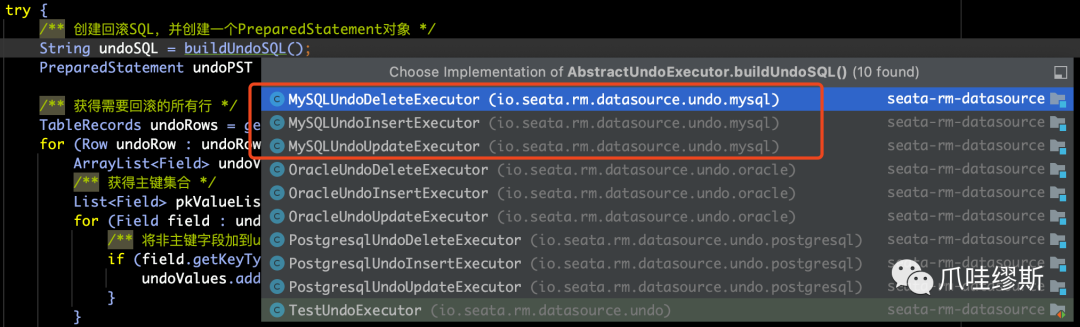
b> buildUndoSQL
- buildUndoSQL()是一个抽象方法,对于不同的数据库都有对应的实现,并且根据不同的数据库操作也有insert、delete和update这3种实现类,如下所示:
b-1> MySQL的insert回滚执行器
- 构建基于MySQL数据库的insert语句的回滚SQL,我们要参照MySQLUndoInsertExecutor的buildUndoSQL()方法:
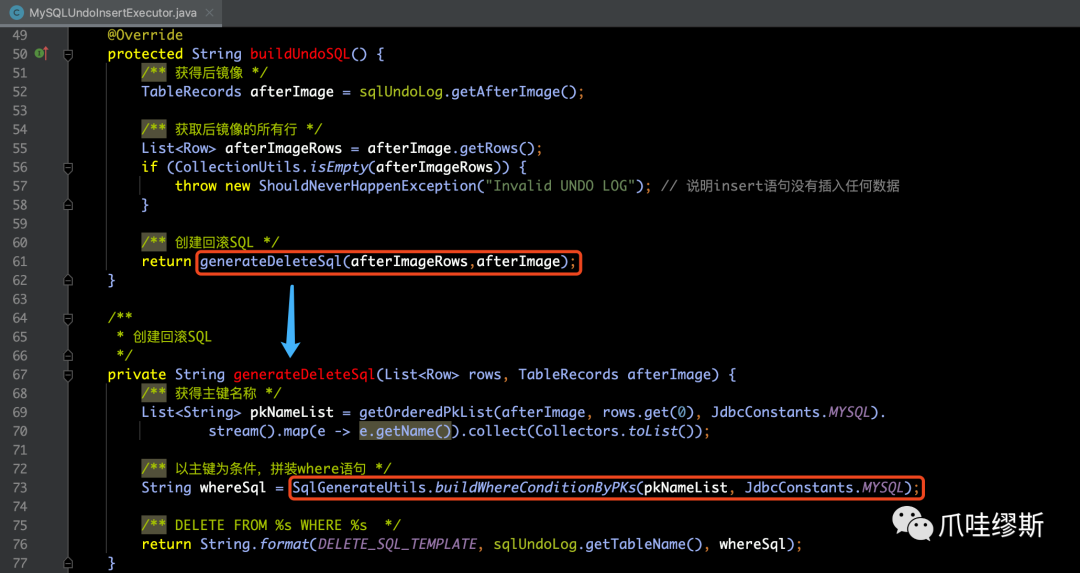
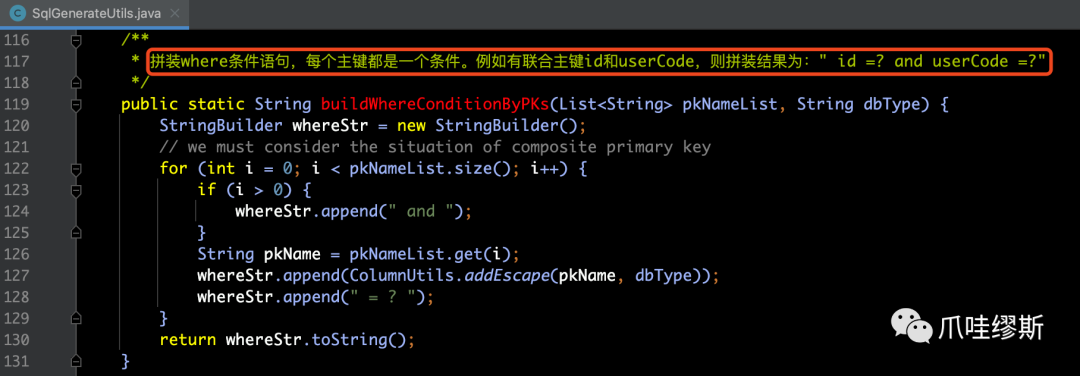
【解释】如果业务SQL语句是insert语句,则它的回滚语句就是delete语句,删掉在一阶段中插入的行。
b-2> MySQL的delete回滚执行器
- 构建基于MySQL数据库的delete语句的回滚SQL,我们要参照MySQLUndoDeleteExecutor的buildUndoSQL()方法:
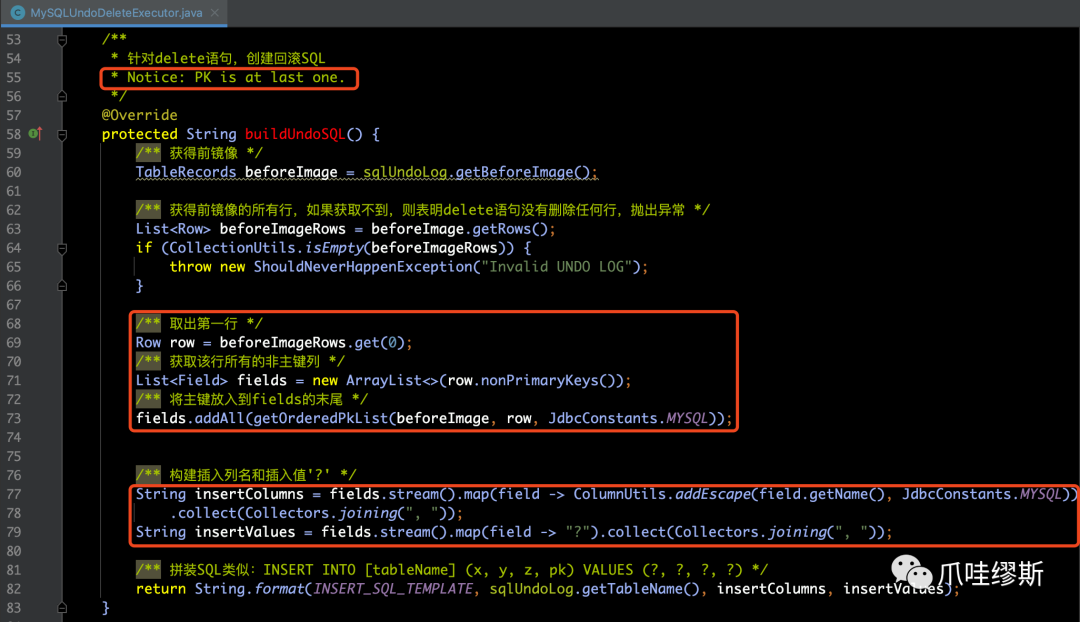
【解释】
- 在buildUndoSQL()方法中,以SQLUndoLog对象的前镜像作为数据来源(即:在一阶段中删除的行)来构建insert语句。
- 如果业务SQL语句为delete语句,则它的回滚语句就是insert语句,把在一阶段中删除的行重新插入进去。
b-3> MySQL的update回滚执行器
- 构建基于MySQL数据库的update语句的回滚SQL,我们要参照MySQLUndoUpdateExecutor的buildUndoSQL()方法:
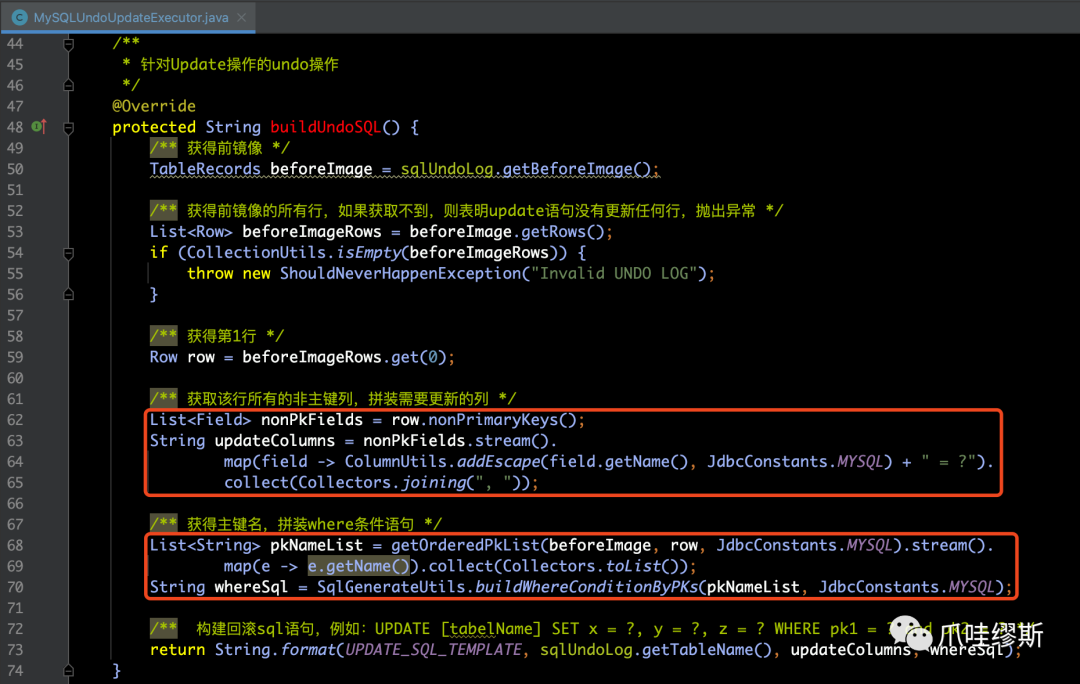
【解释】
- 在buildUndoSQL()方法中,以SQLUndoLog对象的前镜像作为数据来源(即:在一阶段中更新的行在更新之前的值)来构建update语句。
- 如果业务SQL语句为update语句,则它的回滚语句就是update语句,把在一阶段中更新的行的值恢复回去。
- 在RM成功完成分支事务的二阶段回滚后,TC会对该分支事务在一阶段中加的Seata全局锁进行“放锁”操作。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号